


- 首页
- 产品
- 下载
- 学生专享NEW
-
帮助中心
SPSS神经网络怎么分区 SPSS神经网络如何解读
发布时间:2022-08-19 13: 20: 05
品牌型号: DELL Vostro 3400
系统:Windows 10 64位家庭中文版(21H1)
软件版本:IBM SPSS Statistics(28.0.0.1)
SPSS多层感知器神经网络分析是基于模仿人类大脑结构及思维模式的信息处理系统,可通过算法从数据中学习并形成训练模型,再将模型用于分析数据以得到预测结果,因此在进行神经网络分析时会将数据分为训练区与检验区,以便于得到准确预测数据的概率,SPSS神经网络怎么分区,SPSS神经网络如何解读呢?今天一起来看看吧。
一、SPSS神经网络怎么分区
先将现有数据表格导入SPSS中,或者在SPSS安装文件夹下的“Sample”文件夹中有很多自带的数据模板,可以用这些模板数据来体验功能效果。
图1:SPSS自带数据模板 点击菜单“分析”-“神经网络”-“多层感知器”进入神经网络设置面板。

图2:神经网络多层感知器设置 在变量设置板块中,将想要预测的变量置入因变量,将类型变量加入因子,将其他连续型变量加入协变量。
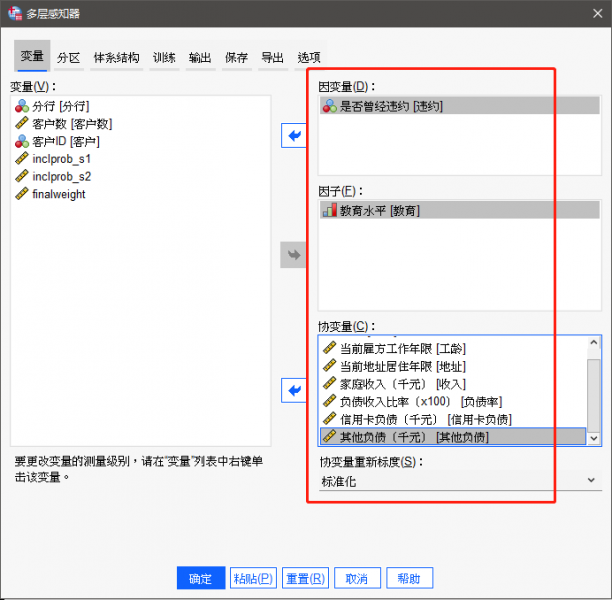
图3:神经网络变量设置 在“分区”板块可以对神经网络进行分区。
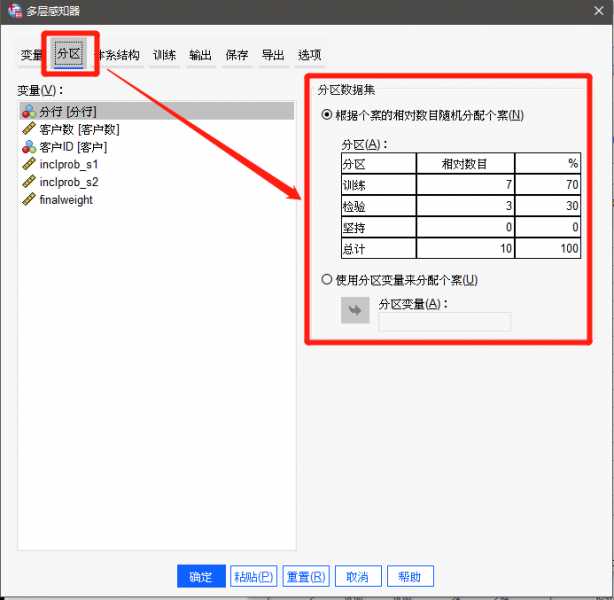
图4:设置分区数据 在分区设置有两种分区方式。
1、随机分区
可以根据样本数量自动分配个案,默认是训练数据占70%,检验数据占30%,而且这两者的占比可以手动调整,从样本总量中随机划分训练样本与检验样本。
2、分区变量指定样本分区
通过给样本指定分区变量来进行分配,这样就能有目的性地将一部分样本设置为训练集,另一部分设置为检验集,并进行针对性地神经网络分析。
在完成神经网络设置后开始神经网络分析,SPSS会自动生成输出文档,包括网络图、模型摘要、参数估算值、预测图、自变量重要性图等。
二、SPSS神经网络如何解读
通过上面的数据可以得到一份分析报告,按照报告中数据与表格展现顺序,我们来看看神经网络分析数据的解读方法。
1、个案处理摘要
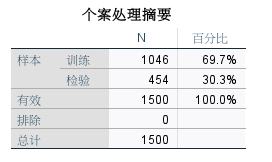
图5:个案处理摘要 这里是SPSS对数据的分区与采用摘要数据,共1500条数据,随机分配了1046条作为训练集数据,占比69.7%,剩余数据则作为检验集数据,占比30.3%,没有无效数据,所以“排除”为0。
2、网络信息
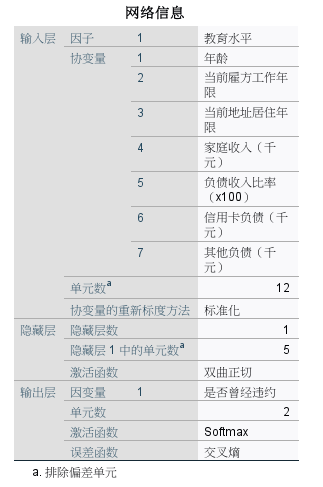
图6:网络信息 这一部分内容分三层,显示了本次分析所设置的输入层影响因子与协变量内容,隐藏层单元数,以及输出层的内容。
3、神经网络图
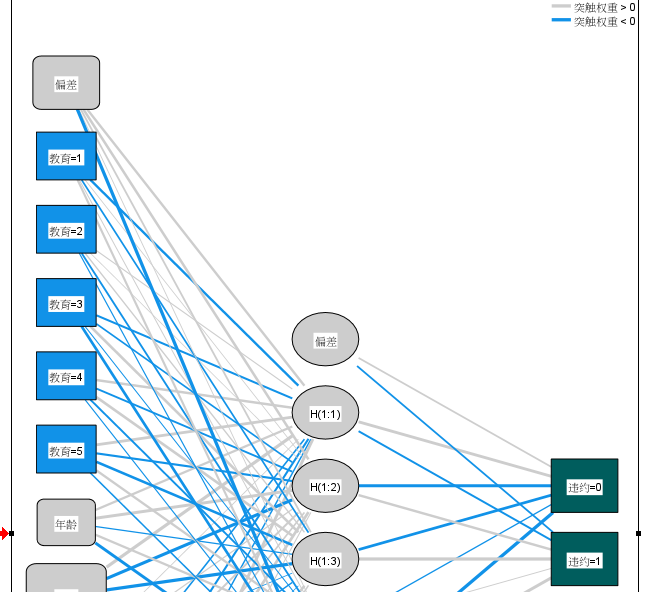
图7:神经网络图 这一部分可以看到不同变量之间的颜色、图形各不相同,一个变量的线条颜色越深,代表其在计算分析中的权重越高;变量的板块越大,则代表其价值越高。
4、分类
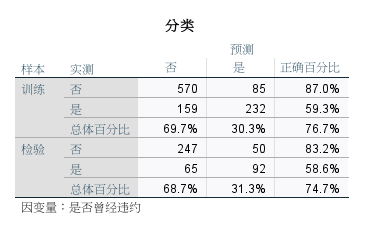
图8:分类数据 从分类数据中可以看到随机分配的训练集与检验集中样本数据的预测正确率仅有“59.3%”和“58.6%”,说明本次分析效果不是很好,正确率较低。(正确率低不代表神经网络算法不好,而是说明这份样本数据不适合用神经网络算法来进行分析)
5、自变量重要性与正态化重要性
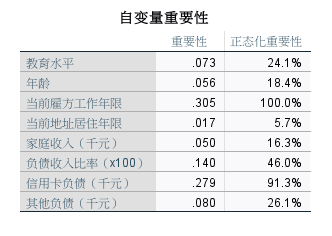
图9:自变量重要性 自变量重要性与正态化重要性的结果一致,不过一个以数值与表格形式体现,一个以柱状图形式体现。
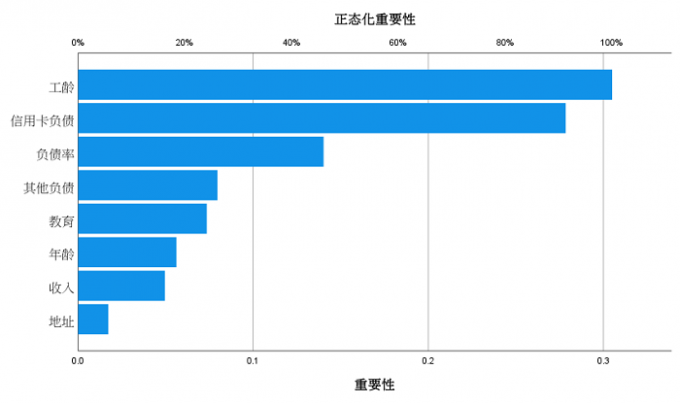
图10:正态化重要性 这两个报告数据显示,各个变量对是否违约的结果影响力大小排列是:工龄>信用卡负债>负债率>其他负债>教育>年龄>收入>地址。
三、SPSS神经网络设置技巧
在上面进行神经网络分析示例时,介绍了设置变量与分区的方法,接下来讲一讲其他选项的设置技巧。
1、输出设置
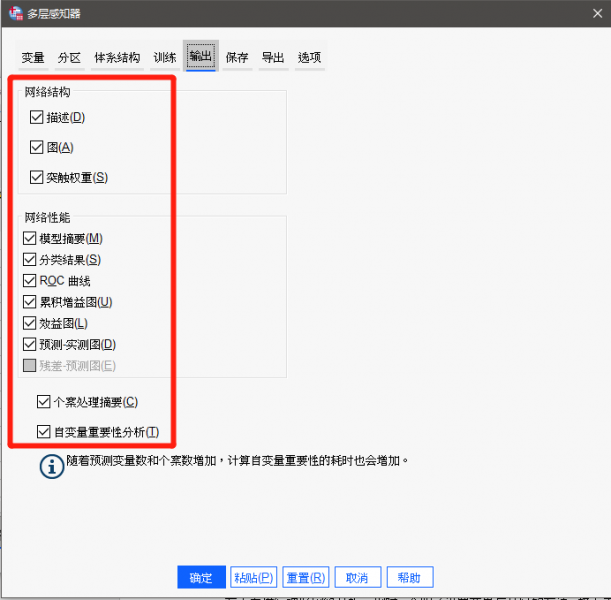
图11:输出设置 建议在输出设置中将能勾选的项目全部勾选上,尤其时“网络结构”中的“描述”、“图”与“突触权重”,以及下面的“自变量重要性分析”,这几个还是比较重要的。
2、保存设置
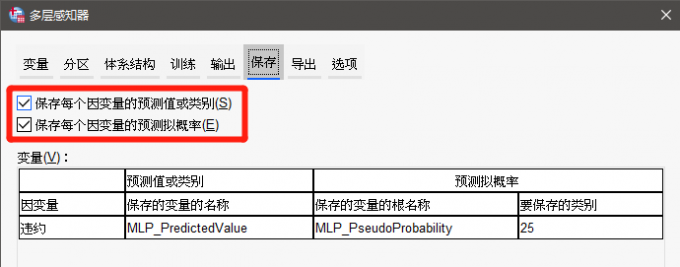
图12:保存设置 在保存设置中,可以将图中两个“因变量的预测值或类别”与“因变量的预测拟概率”选项都勾选上。
主要就是设置“变量”、“分区”、“输出”与“保存”四项,其他的选项设置可以根据自己需要再进行修改。
以上便是SPSS神经网络怎么分区,SPSS神经网络如何解读的全部内容了,大家如果想要了解更多数据分析技巧,欢迎关注IBM SPSS中文网站。
作者:∅
展开阅读全文
︾
标签:IBM SPSS Statistics,SPSS教程,神经网络,IBM SPSS
读者也访问过这里:热门文章SPSS数据分析显著性差异分析步骤 SPSS显著性差异分析结果怎么看数据的显著性差异分析主要有三种方法,分别是卡方检验、T检验和方差分析。这三种方法都有具体的数据要求:卡方检验是对多个类别的数据进行分析,T检验是对两组数据进行分析,方差分析是对多组数据进行检验。下面,小编具体说明一下SPSS数据分析显著性差异分析步骤,SPSS显著性差异分析结果怎么看。2022-01-07实践SPSS单因素方差分析之检验结果解读在《实践SPSS单因素方差分析之变量与检验方法设置》一文中,我们已经详细地演示了IBM SPSS Statistics单因素方差分析方法的变量选择以及相关的选项、对比设置。2021-01-11spss如何做显著性分析 spss显著性差异分析怎么标abc在统计分析中,显著性分析是分析相关因素之间是否存在显著影响关系的关键性指标,通过它可以说明分析结论是否由抽样误差引起还是实际相关的,可论证分析结果的准确性。下面大家一起来看看用spss如何做显著性分析,spss显著性差异分析怎么标abc。2022-03-14SPSS回归分析中的f值是什么 SPSS回归分析F值在什么范围合适回归分析中以R表示相关性程度的高低,以F评价回归分析是否有统计学的意义,使用IBM SPSS Statistics进行回归分析,可以非常快速的完成R,F的计算,并且给出回归曲线方程,那么,SPSS回归分析中f值是什么?SPSS回归分析F值在什么范围合适,本文结合实例向大家作简单的说明。2022-07-22SPSS多元logistic回归分析的使用技巧回归分析是数据处理中较为常用的一类方法,它可以找出数据变量之间的未知关系,得到较为符合变量关系的数学表达式,以帮助用户完成数据分析。2021-04-26SPSS相关性分析结果怎么看相关性分析是对变量或个案之间相关度的测量,在SPSS中可以选择三种方法来进行相关性分析:双变量、偏相关和距离。2021-04-23最新文章SPSS多重插补数据怎么分析 SPSS多重插补后用哪个结果在数据分析的领域中,多重插补数据是一项重要的数据分析方法,许多数据分析场景中都可以看到它的影子。多重插补数据并不是简单地对数据的内容进行补充,而是在填补缺失值的基础上对数据进行了再一次的分析和模拟,体现出数据样本的不确定性。所以后续的数据分析需要在多重插补的数据分析基础之上根据结果进行合并,这样才能得到更加准确的结果。下面以SPSS为例,给大家介绍SPSS多重插补数据怎么分析,SPSS多重插补后用哪个结果的具体内容。2026-07-01SPSS如何绘制茎叶图 SPSS茎叶图怎么分析我们在进行数据分析的过程中,可以借助数据分析后绘制的图像来辅助我们解读数据。数据分析图像能够更加直观地表现出数据的变化幅度以及分布状况,而在数据分析的图像中,茎叶图能够在保留数据信息的同时展现数据样本的轮廓。所以茎叶图就可以成为我们数据分析的一个重要工具,但是许多小伙伴对茎叶图的绘制和使用并不熟悉。下面以SPSS为例,给大家介绍SPSS如何绘制茎叶图,SPSS茎叶图怎么分析的具体内容。2026-07-01SPSS怎么对多选题进行频率分析 SPSS频率分析怎么做我们在问卷数据分析过程中,常常会遇到多选题。这时候,常规的频率分析可能就无法适配多选项的计数需求,而SPSS中的多重响应功能可精准完成多选题的频率统计,同时也能通过基础频率分析功能完成单选题的常规统计。接下来我将为大家介绍:SPSS怎么对多选题进行频率分析,SPSS频率分析怎么做的相关内容。2026-07-01SPSS回归分析加入中介变量怎么做 SPSS中介效应分析结果解读相信大家在进行社会科学研究的时候,常常使用到中介效应分析这个方法。中介效应分析能够清晰地揭示自变量对因变量的影响是否通过中介变量进行传递,让变量间的作用路径更明确。接下来我将为大家介绍:SPSS回归分析加入中介变量怎么做,SPSS中介效应分析结果解读的相关内容。2026-06-02SPSS随机性检验步骤分析 SPSS随机性检验结果分析数据序列的随机性是保障后续统计检验有效性的重要前提,如果出现了非随机分布的数据。有可能会导致分析结果出现偏差。在SPSS中,我们通过游程检验可以快速完成数据随机性的判断。接下来我将为大家介绍:SPSS随机性检验步骤分析,SPSS随机性检验结果分析的相关内容。2026-06-02SPSS绘制箱线图步骤 SPSS箱线图怎么分析SPSS作为一款功能比较齐全的数据统计分析软件,其绘图功能是很全面的,除了常规的条形图、饼形图、折线图外,还有在各种调研报告中常用到的箱线图,可能有些读者朋友不知道怎么用SPSS绘制箱线图,下面将以实际数据给大家在SPSS中演示SPSS绘制箱线图步骤,SPSS箱线图怎么分析。2026-06-02读者也喜欢这些内容:
-
SPSS显著性小于0.001的意义 SPSS显著性大于0.05怎么办
在使用SPSS软件进行数据分析工作的过程中,得到的显著性水平分析结果具有极为重要的作用。它能够帮助我们衡量变量之间是否存在真实的关联,或者不同组别数据之间是否存在实质性的差异。今天我们就一起来探讨关于SPSS显著性小于0.001的意义,SPSS显著性大于0.05怎么办的问题。...
阅读全文 >
-
SPSS神经网络如何应用 SPSS神经网络隐藏层设置
神经网络,顾名思义就是通过模拟动物的神经元来进行数据分析的一种统计模型,通常用于应对非线性或较为复杂的数据。今天我就以SPSS神经网络如何应用,SPSS神经网络隐藏层设置这两个问题为例,来向大家讲解一下SPSS中有关神经网络的相关知识。...
阅读全文 >
-

SPSS因子载荷值是哪个 SPSS因子载荷系数要大于多少
如果我们研究的问题里面有很多的影响因素,而且每个因素都好像很重要,无法剔除其中的一些元素。在这种情况下,我们常常会引入因子分析的研究方法,因子分析是一种降维的方法,可以将一些相似的元素总结为共性因子,这样我们就能将多个因素减少为少数几个因素。本文会给大家介绍SPSS因子载荷值是哪个,SPSS因子载荷系数要大于多少的相关内容,感兴趣的小伙伴不容错过。...
阅读全文 >
-
SPSS检验值怎么看 SPSS检验值怎么得出
在数据统计领域,测量SPSS检验值可以对繁杂的数据组别进行对比和分析,有助于展开后续针对数据关联和差异的研究。今天,我们以SPSS检验值怎么看,SPSS检验值怎么得出这两个问题为例,带大家了解一下SPSS检验值计算和分析的相关知识。...
阅读全文 >
-

















