




仅剩:

发布时间:2025-06-26 11: 10: 00
品牌型号:戴尔 Vostro 15 7510
系统:Windows 11
软件版本:IBM SPSS Statistics 25
IBM SPSS Statistics是一款功能强大的统计软件,具备如数据处理、数理统计、分析预测,数据可视化等功能。借助IBM SPSS Statistics,我们可以快速完成数据分析工作,避免大量的数学计算,大大提高工作效率。使用IBM SPSS Statistics,首先要注意数据类型的设置,数据类型设置不正确,可能导致统计出现错误。SPSS连续变量和分类变量的区别,SPSS连续变量和分类变量的关系是怎样的,本文向大家作简单介绍。
一、SPSS连续变量和分类变量的区别
连续变量是指在一定范围内,可以连续取值的变量,如一天内的气温变化。分类变量是指有类别区分的变量,例如男性和女性。针对不同变量,数学家发展了不同的数理统计方法,旨在使得统计结果更符合数学规律,更能够指导实践。例如t检验,其检验对象为连续变量,是指在样本量较少时,服从正态分布的样本分布为t分布,此时应该以t分布进行假设检验。
例如某矿石含矿量为146g/kg,对该矿石进行了重复检测,根据数据分析,检测结果是否可信。
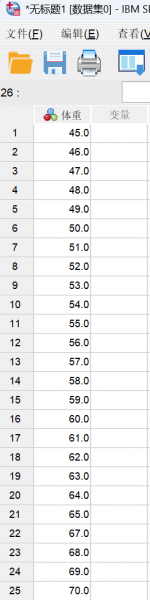
此时检测结果为连续变量,如图1所示。

对这些数据进行单样本t检验,结果如图2所示。

sig.(双尾)检验值为0,小于5%,认为在95%的置信水平下,该检验值和实际值存在显著差异,差异值为-17.61538,所以认为检验值不可信。对于分类变量,则不能采用t检验进行假设检验。
以上向大家介绍了连续变量和分类变量的区别,连续变量和分类变量有什么关系,我们在第二小节中向大家介绍。
二、SPSS连续变量和分类变量的关系
分类变量是对连续变量统计后分组,继续比较差异,例如医院考察病人某项生理指标,此时会将病人分为两组,一组施加干预,一组不施加干预。一段时间后,分别统计各组指标,统计指标正常和不正常的人数,进行统计学检验,分析干预是否有效。数据如图所示。

对上述数据进行卡方检验,结果如图所示,皮尔逊卡方渐进显著性(双侧)为0.004,小于0.05,认为两组存在显著性差异,干预有效。
使用SPSS进行数据分析,一定要明确数据类型,不同的数据类型服从不同的分布,应选择恰当的统计方法。

本文向大家介绍了有关SPSS连续变量和分类变量的区别,SPSS连续变量和分类变量的关系的内容。对于连续变量,我们一般采用如t检验、回归分析等方法进行统计。对于分类变量,我们一般采用如卡方分析、logistics回归等分析方法,其根源在于,应使用合适的数学方法处理不同类型的数据,因此大家进行数据分析时,要时刻注意数据的类型,避免产生错误,造成排查困难。
展开阅读全文
︾
读者也喜欢这些内容:

SPSS软件安装与注册试用教程
IBM SPSS Statistics作为一款全球知名的数据统计分析软件,无论是在学术研究领域,还是商业经营领域,都起着举足轻重的作用。其推出的一系列统计分析方法,可用于数据的分析运算、挖掘、模型预测等多个方面。...
阅读全文 >
SPSS显著性小于0.001的意义 SPSS显著性大于0.05怎么办
在使用SPSS软件进行数据分析工作的过程中,得到的显著性水平分析结果具有极为重要的作用。它能够帮助我们衡量变量之间是否存在真实的关联,或者不同组别数据之间是否存在实质性的差异。今天我们就一起来探讨关于SPSS显著性小于0.001的意义,SPSS显著性大于0.05怎么办的问题。...
阅读全文 >
在SPSS中分类变量可以转换为连续变量吗 SPSS分类变量与连续变量的相关分析怎么做
SPSS是一款比较优秀的数据统计分析软件,很多统计达人都喜欢使用SPSS进行各种数据分析,而SPSS之所以深受大家的喜爱,除了有着强大的数据分析功能,还可以进行数据处理,例如SPSS可以将连续变量和分类变量进行转换,下面给大家详细讲解在SPSS中分类变量可以转换为连续变量吗,SPSS分类变量与连续变量的相关分析怎么做。...
阅读全文 >

SPSS分析数据带一个-号什么意思 SPSS里面的度量、有序和名义什么意思
SPSS作为一款专业的数据分析软件,无论是市场研究、医疗保健、调查问卷、零售百货等领域,经常会用到它帮助我们对数据进行分析。刚开始使用SPSS难免会遇到操作上的问题,下面就给大家介绍一下SPSS分析数据带一个-号什么意思,SPSS里面的度量、有序和名义什么意思的相关内容。...
阅读全文 >
