- 首页
- 产品
- 下载
- 学生专享NEW
-
帮助中心
SPSS相关性分析结果怎么看
发布时间:2021-04-23 10: 27: 54
相关性分析是对变量或个案之间相关度的测量,在IBM SPSS Statistics中可以选择三种方法来进行相关性分析:双变量、偏相关和距离。
分析方法是操作手段,结果是得到分析后的数据列表,那么使用SPSS进行相关性分析后该如何查看并解读结果呢?下面整理了几种常见相关分析结果的解读,大家可以参考一下。
一、双变量分析
1.数据
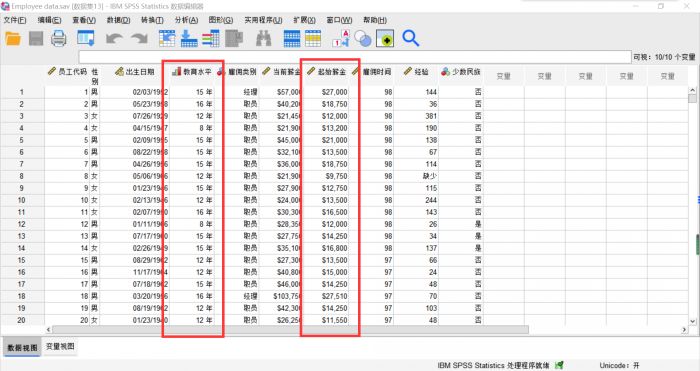
图1:数据列表 数据样本如上图所示,是某家公司录取员工的基本情况,我们要探究的是教育水平和起始薪金之间的相关性。
2.分析设置
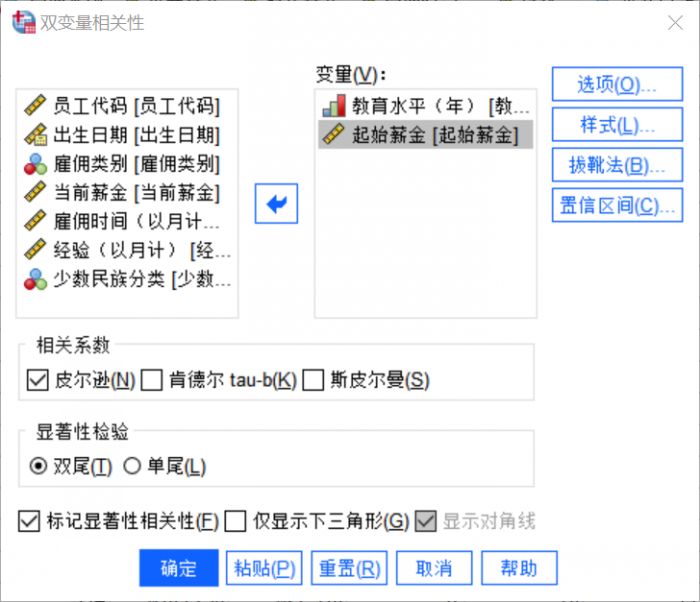
图2:双变量分析设置 对两个变量进行如上图设置,选择皮尔逊相关和双尾检验。
3.结果分析
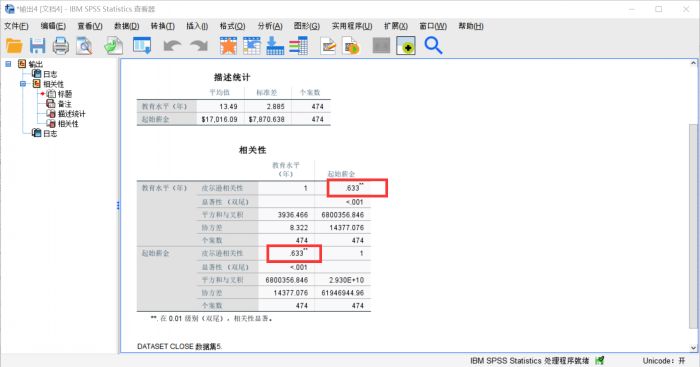
图3:分析结果 结果中一般会有两个表(只运用一种分析方法),第一个表是频率统计和基本的计算结果,显示数据的平均值、标准差和个案数。
第二个表是表征数据相关性的,我们需要重点关注的一个参数是皮尔逊相关系数,也就是常说的p值,若这个值的绝对值大于0.05,就表示变量间存在显著相关性。
表中有两个数据被用星号标注,这就是大于0.05的p值,表明教育水平和起始薪金存在显著的正相关性。
二、偏相关分析
1.分析设置
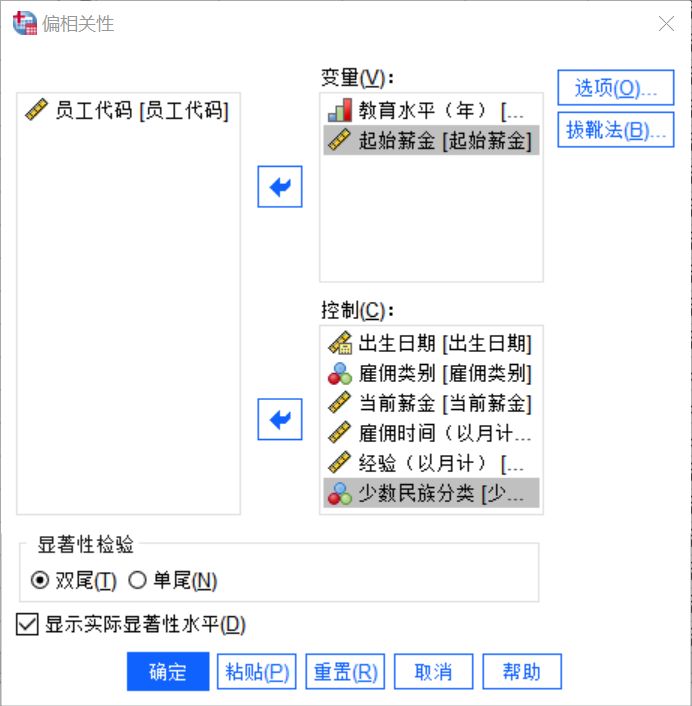
图4:分析设置 偏相关分析是用来剔除有关变量的干扰、用以分析其他变量之间相关性的方法。
同样使用上述样本,如果我们要更为精确地探讨起始薪金和教育水平的相关性,可以将其余变量都视作干扰变量全部剔除,分析设置如上图。
2.结果分析
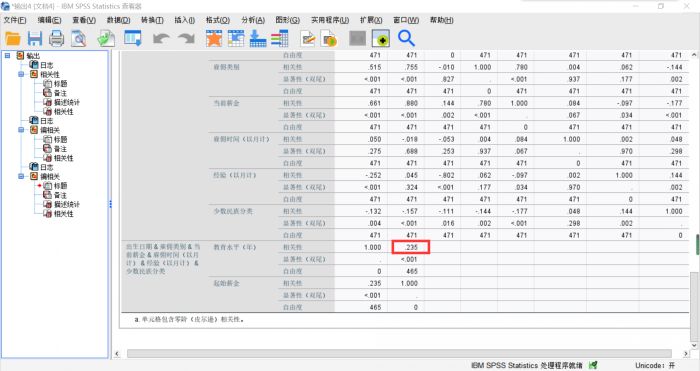
图5:偏相关结果 由于控制变量较多,这个表格也较为复杂,但可以直观看出每两个变量之间的相关性方向和强弱。
在表格最后,是控制变量后对教育水平和起始薪金的相关性分析,可以发现,其他变量被控制后,皮尔逊系数明显下降,由双变量分析中的0.633降为0.235,它们之间仍然具有正相关性,但相关程度大大降低。
由此可见,对于变量数目较多且关系复杂的数据,分析两个变量或特定变量之间的相关性时,使用偏相关分析结果会更为可靠一点。
三、距离分析
1.个案非相似性距离分析
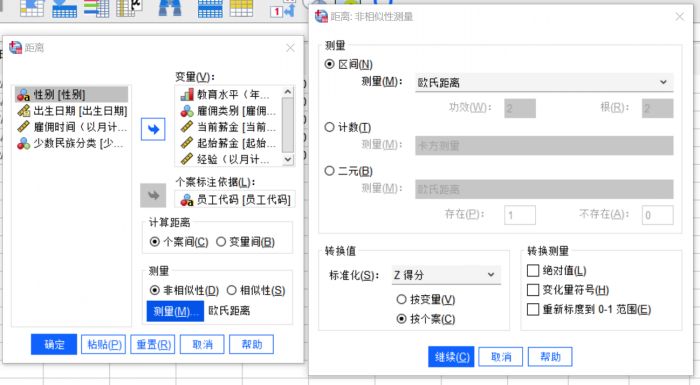
图6:距离分析设置 选择本数据样本的前五组数据作为分析对象,通过对教育水平、雇佣类别、起始薪金、现在薪金、经验几个变量的分析计算个案间的非相似性距离。
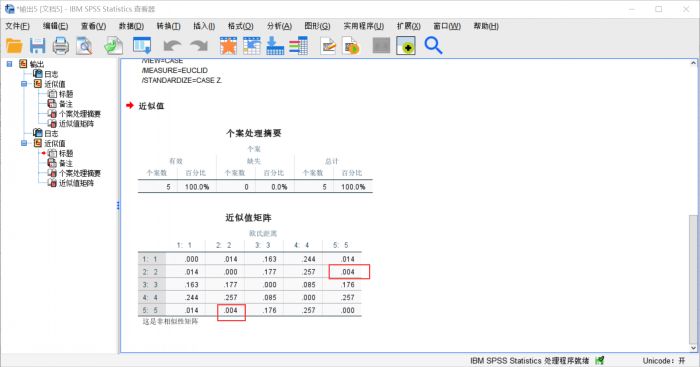
图7:结果分析 这种分析方法的结果是得到一个非相似性矩阵,表中的参数值越小,相似性越大,表中显示,个案2和个案5之间的距离最小,所以他们的相关性最强。
2.变量相关性距离分析
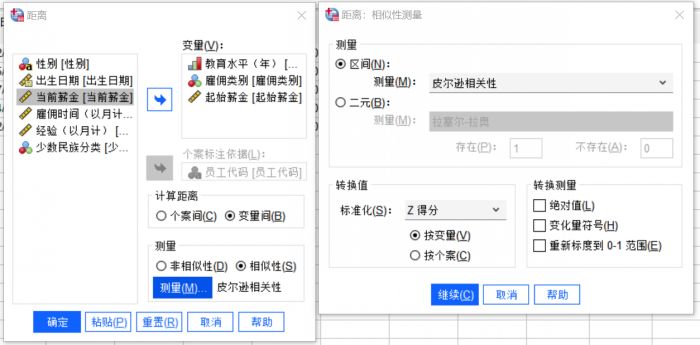
图8:分析设置 将分析对象变为个案,非相似性改为相似性,进行如上设置。
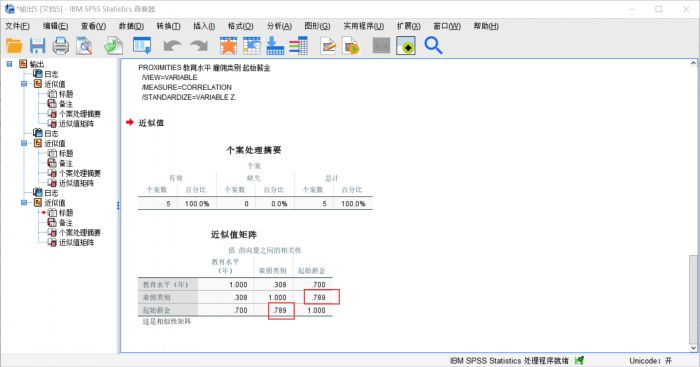
图9:结果分析 和非相似性矩阵类似,我们会得到一个相似性矩阵,其中的参数表示变量之间的相似性距离,参数越大,相关性越强。
从表中显示的参数来看,在被分析的三个变量中,起始薪金和雇佣类别的距离最大,相关性最强。
四、小结
关于使用SPSS相关性分析后的结果,本次的分享就到这里啦,三种方法的应用范围和分析精度都有所不同,大家根据自己需要选择即可,希望可以对大家有所帮助!
作者:参商
展开阅读全文
︾
标签:IBM SPSS Statistics,相关性分析,SPSS相关性检验,SPSS相关性
- 上一篇:SPSS二阶聚类分析教程
- 下一篇:如何使用SPSS进行季节性分解
热门文章SPSS数据分析显著性差异分析步骤 SPSS显著性差异分析结果怎么看数据的显著性差异分析主要有三种方法,分别是卡方检验、T检验和方差分析。这三种方法都有具体的数据要求:卡方检验是对多个类别的数据进行分析,T检验是对两组数据进行分析,方差分析是对多组数据进行检验。下面,小编具体说明一下SPSS数据分析显著性差异分析步骤,SPSS显著性差异分析结果怎么看。2022-01-07实践SPSS单因素方差分析之检验结果解读在《实践SPSS单因素方差分析之变量与检验方法设置》一文中,我们已经详细地演示了IBM SPSS Statistics单因素方差分析方法的变量选择以及相关的选项、对比设置。2021-01-11spss如何做显著性分析 spss显著性差异分析怎么标abc在统计分析中,显著性分析是分析相关因素之间是否存在显著影响关系的关键性指标,通过它可以说明分析结论是否由抽样误差引起还是实际相关的,可论证分析结果的准确性。下面大家一起来看看用spss如何做显著性分析,spss显著性差异分析怎么标abc。2022-03-14SPSS回归分析中的f值是什么 SPSS回归分析F值在什么范围合适回归分析中以R表示相关性程度的高低,以F评价回归分析是否有统计学的意义,使用IBM SPSS Statistics进行回归分析,可以非常快速的完成R,F的计算,并且给出回归曲线方程,那么,SPSS回归分析中f值是什么?SPSS回归分析F值在什么范围合适,本文结合实例向大家作简单的说明。2022-07-22SPSS多元logistic回归分析的使用技巧回归分析是数据处理中较为常用的一类方法,它可以找出数据变量之间的未知关系,得到较为符合变量关系的数学表达式,以帮助用户完成数据分析。2021-04-26SPSS相关性分析结果怎么看相关性分析是对变量或个案之间相关度的测量,在SPSS中可以选择三种方法来进行相关性分析:双变量、偏相关和距离。2021-04-23最新文章SPSS怎么合并变量为一个因子 SPSS因变量和因子怎么判断我们在使用SPSS进行问卷数据分析的过程中,多个题项往往共同测量同一个潜在维度,直接使用单个题项分析会导致结果零散,将这些相关变量合并为一个因子,能精准提炼数据的核心特征。接下来我将为大家介绍:SPSS怎么合并变量为一个因子,SPSS因变量和因子怎么判断的相关内容。2026-07-02SPSS怎么给数据分等级 SPSS怎么给数据加单位在处理数据的时候,我们可能会想给部分范围数据设置等级,比如分数大于90分的,设置为优秀;分数处于75到90之间的,设置为良好等。在SPSS软件里,我们可以用重新编码的方式,给数据分不同的等级,让其含义更丰富。接下来,本文会给大家介绍SPSS怎么给数据分等级,SPSS怎么给数据加单位的相关内容。2026-07-02SPSS怎么进行简单随机抽样 SPSS怎么进行信效度分析我们在进行问卷调研后,往往需要进行实证的数据分析。在这个过程里,简单随机抽样能够从全量数据中抽取代表性样本,是一种能降低数据分析工作量的核心方法,同时也可以保障样本的随机性与代表性。另外,信度检验验证数据的可靠性,效度分析检验问卷的结构合理性,二者是开展后续统计分析的重要前提。接下来我将为大家介绍:SPSS 怎么进行简单随机抽样,SPSS 怎么进行信效度分析的相关内容。2026-07-02SPSS做频数分布表如何分组 SPSS的频数分布表如何分析数据分析时,连续型变量的原始取值通常较为分散,直接统计频数的话,很难清晰呈现数据的整体分布规律。如果能够分组制作频数分布表,就能将零散的数据整合为有序的组别,直观展现不同区间的样本分布情况。接下来我将为大家介绍:SPSS做频数分布表如何分组,SPSS的频数分布表如何分析的相关内容。2026-07-02SPSS中的f值怎么算 SPSS中的f值显著性数值范围是多少在方差分析、回归分析等统计的方法中,f值多用于判断多组间均值差异是否显著、回归模型是否具有统计学意义。使用SPSS,无需手动计算复杂的f值公式,只需通过对应模块完成变量设置。接下来我将为大家介绍:SPSS中的f值怎么算,SPSS中的f值显著性数值范围是多少的相关内容。2026-07-02SPSS如何将数据转换成二分类 SPSS如何将数据转换成文本原始数据类型往往无法直接满足全部分析与展示需求,所以在数据分析的过程中,我们需要将连续变量或多分类变量转换成二分类变量。而将数值编码转换成文本标签,能让数据结果更直观易懂。接下来我将为大家介绍:SPSS如何将数据转换成二分类,SPSS如何将数据转换成文本的相关内容。2026-07-02读者也喜欢这些内容:
-
SPSS中的F值是什么 SPSS中P值和F值如何计算
在SPSS得出的运算结果中,会出现一些F值、P值等结果,对于初学者来说,这些统计量可能会有点陌生,但它们在数据研究中,有着重要的意义。其实不仅是SPSS,其他同类型的统计软件也会出现这些统计量。接下来我们会介绍SPSS中的F值是什么,SPSS中P值和F值如何计算的相关内容,让大家可以更熟悉这方面的内容。...
阅读全文 >
-
SPSS回归分析加入中介变量怎么做 SPSS中介效应分析结果解读
相信大家在进行社会科学研究的时候,常常使用到中介效应分析这个方法。中介效应分析能够清晰地揭示自变量对因变量的影响是否通过中介变量进行传递,让变量间的作用路径更明确。接下来我将为大家介绍:SPSS回归分析加入中介变量怎么做,SPSS中介效应分析结果解读的相关内容。...
阅读全文 >
-
SPSS 安装激活流程
...
阅读全文 >
-
SPSS如何计算四分位数间距 SPSS加权平均怎么做
在数据统计分析中,我们常常需要计算四分位间距和加权平均值,SPSS 作为一款功能强大且应用广泛的软件,不仅可以快速计算四分位数间距,还可以精准分析数据的加权平均值。下面我们就一起来探讨SPSS如何计算四分位数间距,SPSS加权平均怎么做的相关问题。...
阅读全文 >