


- 首页
- 产品
- 下载
- 学生专享NEW
-
帮助中心
SPSS中如何进行快速聚类分析
发布时间:2021-04-21 10: 36: 11
作为广受数据分析师青睐的一款数据统计和分析软件,IBM SPSS Statistics中有全面的数据分析方法,今天我们要介绍的是它的聚类分析中的快速聚类分析。
一、方法概述
聚类分析是将研究对象按照一定的标准进行分类的方法,分类结果是每一组的对象都具有较高的相似度,组间的对象具有较大的差异。
这类分析方法多用于对于数据样本没有特定的分类依据的情况,IBM SPSS Statistics会通过对数据的观察为用户做出较为完善的分类。
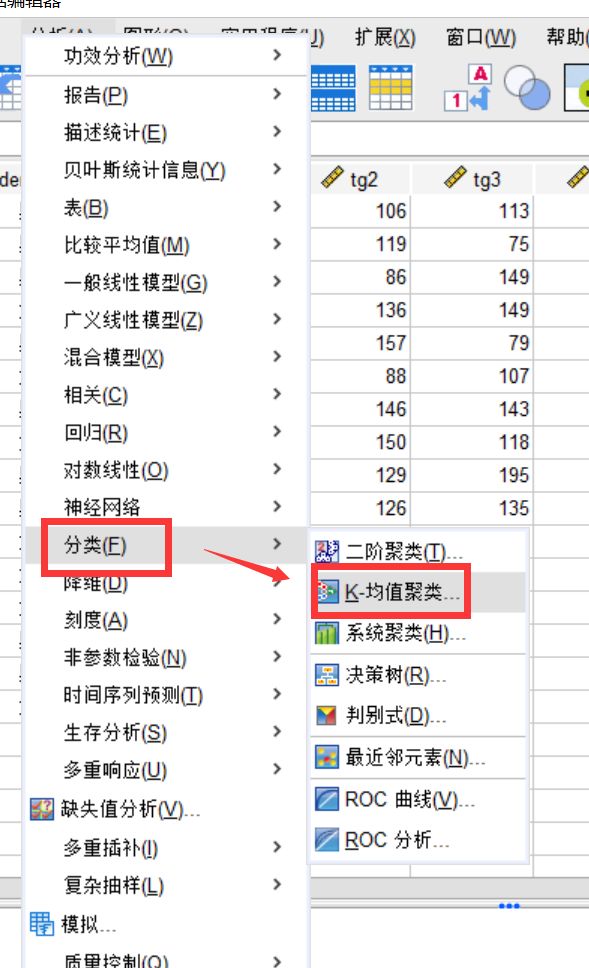
图1:功能位置 快速聚类是聚类分析的一种,使用到的功能在“分析”——“分类”中的“K-均值聚类”。
二、案例分享
1.样本数据
图2:样本数据 我们这里选择的数据样本是一部分学生的各科期末成绩,使用快速聚类方法可以分析各个学生成绩分布的差异和共性。
2.变量设置
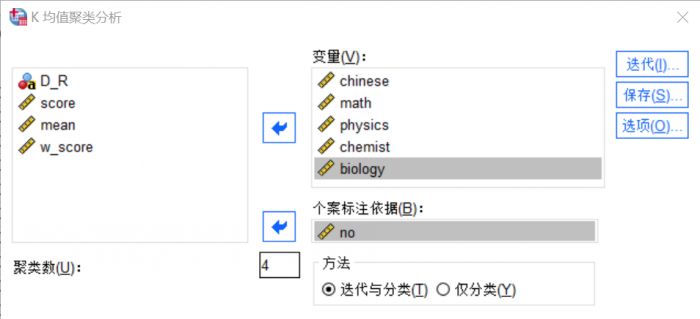
图3:变量设置 我们将学生的所有单科成绩作为分析变量,移入到“变量”窗口中,将学生的编号变量移入到下侧的“个案标记依据”窗口。
聚类数设置的是分类的数目,这个需要根据数据样本的特点来设置,我们这里设置为4类。
聚类方法有两类,即迭代和分类,前者较为复杂,会在分析过程中不断移动凝聚点,后者则始终使用初始凝聚点,我们选择两类都有的第一种分析方法。
3.聚类中心
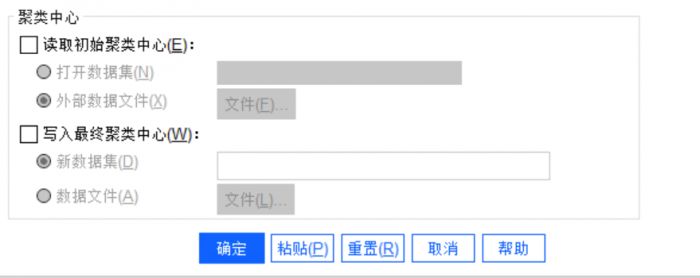
图4:聚类中心 用户可以选择从外部文件或数据文件中写入或读取聚类中心,本案例中我们不使用这个功能。
4.迭代设置
图5:迭代设置 我们可以设置迭代的终止条件,即到达设定的最大值后将停止迭代分析,输出聚类分析结果。
收敛性标准设置的是凝聚点改变的最大距离小于初始凝聚点的比例,小于设定值时,也会停止迭代,输出结果。
使用运行均值表示每次观测后都重新计算凝聚点,这些设置保持默认即可。
5.保存
图6:保存新变量 这是用来设置保存形式的,勾选“聚类成员”将保存SPSS的分类结果,勾选“与聚类中心的距离”将保存观测值和所属类别的欧氏距离,我们不做设置。
6.选项
图7:选项设置 这个对话框设置的是输出的统计量和个案缺失处理方法,勾选“初始聚类中心”和“每个个案的聚类信息”。
7.结果输出
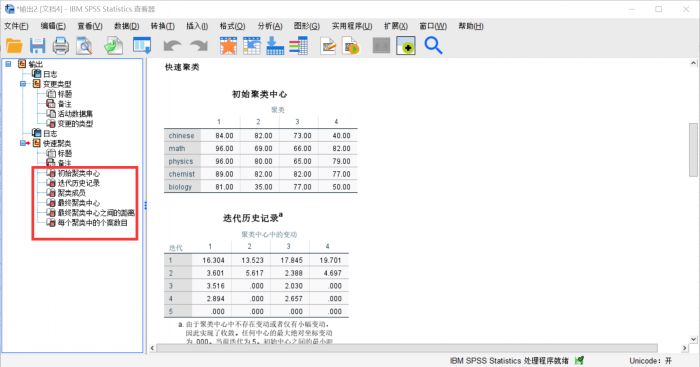
图8:聚类结果 在输出日志中可以看到,这些学生根据他们的单科成绩被分成了四类,SPSS输出了多个表格,包括初始聚类中心、迭代历史记录、聚类成员、最终聚类中心、最终聚类中心之间的距离和每个聚类中的个案数目,完整详细,可信度较高。
三、小结
使用IBM SPSS Statistics进行快速聚类的方法和案例分享就是这么多啦,这是一个较为常用的分类分析法,适用程度很高,希望可以对大家有所帮助!
如果您对SPSS也有兴趣,欢迎进入IBM SPSS Statistics中文网站下载试用!
作者:参商
展开阅读全文
︾
标签:IBM SPSS Statistics,快速聚类分析
- 上一篇:SPSS的系统聚类分析该怎么用
- 下一篇:SPSS二阶聚类分析教程
热门文章SPSS数据分析显著性差异分析步骤 SPSS显著性差异分析结果怎么看数据的显著性差异分析主要有三种方法,分别是卡方检验、T检验和方差分析。这三种方法都有具体的数据要求:卡方检验是对多个类别的数据进行分析,T检验是对两组数据进行分析,方差分析是对多组数据进行检验。下面,小编具体说明一下SPSS数据分析显著性差异分析步骤,SPSS显著性差异分析结果怎么看。2022-01-07实践SPSS单因素方差分析之检验结果解读在《实践SPSS单因素方差分析之变量与检验方法设置》一文中,我们已经详细地演示了IBM SPSS Statistics单因素方差分析方法的变量选择以及相关的选项、对比设置。2021-01-11spss如何做显著性分析 spss显著性差异分析怎么标abc在统计分析中,显著性分析是分析相关因素之间是否存在显著影响关系的关键性指标,通过它可以说明分析结论是否由抽样误差引起还是实际相关的,可论证分析结果的准确性。下面大家一起来看看用spss如何做显著性分析,spss显著性差异分析怎么标abc。2022-03-14SPSS回归分析中的f值是什么 SPSS回归分析F值在什么范围合适回归分析中以R表示相关性程度的高低,以F评价回归分析是否有统计学的意义,使用IBM SPSS Statistics进行回归分析,可以非常快速的完成R,F的计算,并且给出回归曲线方程,那么,SPSS回归分析中f值是什么?SPSS回归分析F值在什么范围合适,本文结合实例向大家作简单的说明。2022-07-22SPSS多元logistic回归分析的使用技巧回归分析是数据处理中较为常用的一类方法,它可以找出数据变量之间的未知关系,得到较为符合变量关系的数学表达式,以帮助用户完成数据分析。2021-04-26SPSS相关性分析结果怎么看相关性分析是对变量或个案之间相关度的测量,在SPSS中可以选择三种方法来进行相关性分析:双变量、偏相关和距离。2021-04-23最新文章SPSS如何验证数据是否符合正态分布 SPSS数据验证怎么用函数计算正态分布,是很多常用的分析方法比如ANOVA方差分析、t检验等,要求数据需要满足的条件。因为满足正态分布的数据,能更加准确地捕捉到差异性,而且它们的总体参数也会更加稳定。在SPSS里面,我们可以通过几种方法来检验数据的分布是否满足需求。接下来我们会介绍SPSS如何验证数据是否符合正态分布,SPSS数据验证怎么用函数计算的相关内容。2026-07-02SPSS变量值设定为0却变成00 SPSS计算变量为什么有空值我们在处理数据样本的过程中,有时候会遇到变量设定错误的问题。就是在设置变量值的时候把变量设定为0,但是实际在数据分析运算的过程中却变成了00,并且在计算变量过程中又出现了空值。出现这种情况可能会直接影响数据分析结果的精准度,因此需通过调整变量类型修正数据。下面以SPSS为例,给大家介绍SPSS变量值设定为0却变成00,SPSS计算变量为什么有空值的具体内容。2026-07-02SPSS中如何将年龄分段筛选出来 SPSS如何将年龄从字符串改为数字在进行社会科学研究时,往往会需要进行调研。在调研之后,我们做调研数据处理时,可能会遇到格式不整齐的情况,例如变量并非单纯的数字,而是包含了“岁”等单位。这样的字符串格式的年龄不能直接用于数据分析,而是必须先转换成纯数字。接下来我将为大家介绍:SPSS 中如何将年龄分段筛选出来,SPSS如何将年龄从字符串改为数字的相关内容。2026-07-02SPSS中如何将字符串变量转换为数值 SPSS字符串数据怎么处理我们在用问卷收集数据的时候,难免要设置一些开放题。由于开放题没有固定的答案,所以比较难事先做好编码,一般都是将答案收集好后再整理。因此,将数据导入SPSS后,可能会有一些字符串的变量,需要进行二次处理。接下来我们会介绍SPSS中如何将字符串变量转换为数值,SPSS字符串数据怎么处理的相关内容。2026-07-02SPSS的检验方法有哪些 SPSS如何做z检验在做研究分析时,我们可能要做各种数据的检验运算,比如看数据是否满足正态性、方差齐性,看各种组别的数值是否有统计学差异等。SPSS提供了很多实用的分析方法、参考图表等功能,可以快速而简单地做好数据的检验,接下来我们会介绍SPSS的检验方法有哪些,SPSS如何做z检验的相关内容。2026-07-02SPSS中的F值是什么 SPSS中P值和F值如何计算在SPSS得出的运算结果中,会出现一些F值、P值等结果,对于初学者来说,这些统计量可能会有点陌生,但它们在数据研究中,有着重要的意义。其实不仅是SPSS,其他同类型的统计软件也会出现这些统计量。接下来我们会介绍SPSS中的F值是什么,SPSS中P值和F值如何计算的相关内容,让大家可以更熟悉这方面的内容。2026-07-02读者也喜欢这些内容:
-
SPSS怎么进行Logistic回归 SPSS Logistic回归分类结果不准确怎么办
在数据分析中,Logistic回归常常作为处理二分类因变量的方法,应用场景广泛。使用SPSS进行Logistic回归时,很多朋友常面临分类结果不准确的问题。今天我们将会详细介绍关于SPSS怎么进行Logistic回归,SPSS Logistic回归分类结果不准确怎么办的相关问题。...
阅读全文 >
-
SPSS多层线性模型如何构建 SPSS多层线性模型层级变量设置
每当在进行数据分析时,许多小伙伴可能都会遇到构建多层线性模型的情况。构建多层线性模型能扩大已测量的数据样本,使数据涵盖更多内容,进而更加有说服力。而在进行多层线性模型构建时,一款好用的数据分析软件是不可缺少的,这里给大家介绍我自己常用的SPSS数据分析软件,同时以它为例向大家介绍SPSS多层线性模型如何构建,SPSS多层线性模型层级变量设置的具体内容。...
阅读全文 >
-
SPSS显著性小于0.001的意义 SPSS显著性大于0.05怎么办
在使用SPSS软件进行数据分析工作的过程中,得到的显著性水平分析结果具有极为重要的作用。它能够帮助我们衡量变量之间是否存在真实的关联,或者不同组别数据之间是否存在实质性的差异。今天我们就一起来探讨关于SPSS显著性小于0.001的意义,SPSS显著性大于0.05怎么办的问题。...
阅读全文 >
-
SPSS假设检验P值怎么算 SPSS假设检验结果怎么看
很多时候人们无法分辨两组数据间的差异是来自于抽样不均匀,还是来自数据总体的差异,这时候可以通过假设检验的方法予以判别。假设检验先假定一个结论,然后使用统计学方法推测是否接受该结论,判别两组数据之间是否存在差异。人工进行假设检验,需要进行大量计算,还需要查表,非常繁琐。借助统计学软件,如SPSS,可以高效的进行假设检验。SPSS假设检验P值怎么算,SPSS假设检验结果怎么看,本文借助实例,向大家作简单介绍。...
阅读全文 >





