


- 首页
- 产品
- 下载
- 学生专享NEW
-
帮助中心
回归分析SPSS步骤 回归分析SPSS结果解读
发布时间:2022-05-11 14: 12: 11
品牌型号:联想GeekPro 2020
系统: Windows 10 64位专业版
软件版本: IBM SPSS Statistics
回归分析SPSS步骤,本文会以研究客流量对销售额影响的问题为例具体演示SPSS操作步骤,同时,也会具体进行回归分析SPSS结果解读,并进一步讲解回归分析的其他类型,以帮助加深对回归分析的认识。
一、回归分析SPSS步骤
本文使用的是一组客流量和销售额的数据,用于构建客流量与销售额的线性回归分析,以研究客流量的变化对销售额的影响。
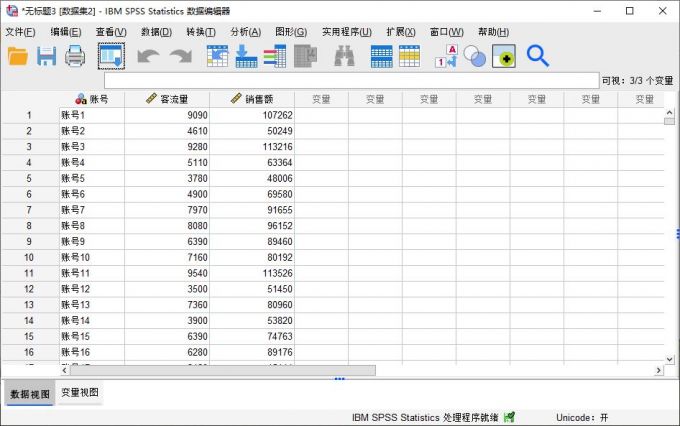
图1:示例数据 本例数据仅包含一个自变量与一个因变量,因此可构建简单的一元线性回归方程,依次单击SPSS的分析-回归-线性选项,进行线性回归分析。
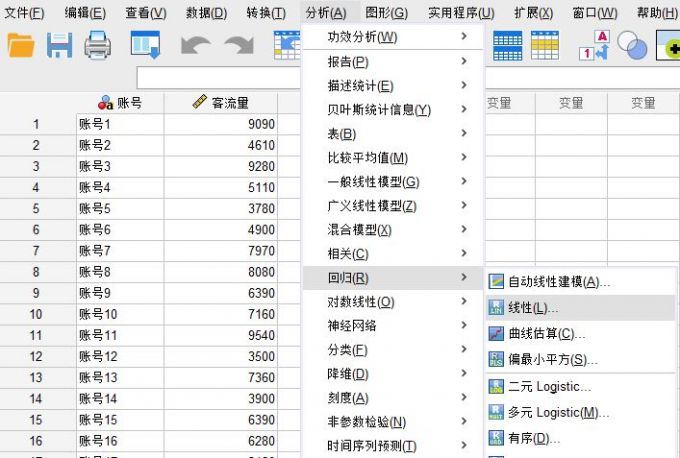
图2:线性回归分析 第一步选择变量,分别将销售额、客流量添加到因变量、自变量选项中,以研究自变量客流量对因变量销售额的影响。
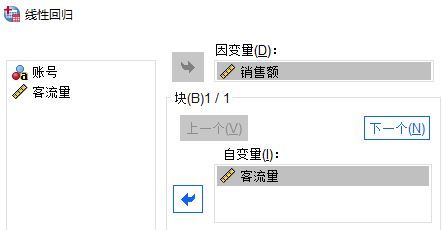
图3:选择变量 第二步,指定线性回归进入的方式,包括输入(自变量全部放进回归模型)、步进(按自变量贡献度、剔除与否等决定自变量是否放入回归模型)、除去(建立自变量模型后,根据条件剔除自变量)、后退(与除去相似,但后退采用逐次剔除自变量的方法)与前进(逐次添加自变量)五种方法。
由于本例分析的是简单的一元线性回归方程,可以按照默认选择“输入”。
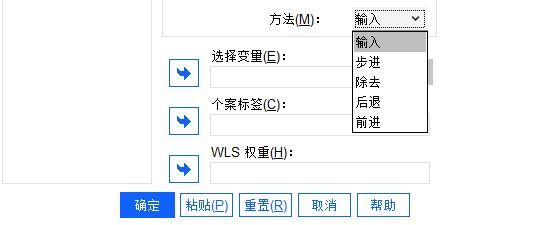
图4:进入方法 第三步设置统计量,分别指定以下统计量:
1.回归系数,进行线性回归方程系数的计算,勾选“估算值”,可获得参数估计量。
2.模型拟合,了解模型的拟合度以及预测的准确度,可同时勾选“描述”统计数值,查看平均值、方差等。
3.残差,勾选“德宾-沃森(D-W)”检验,以了解残差是否存在自相关,检验模型是否具有统计学意义。
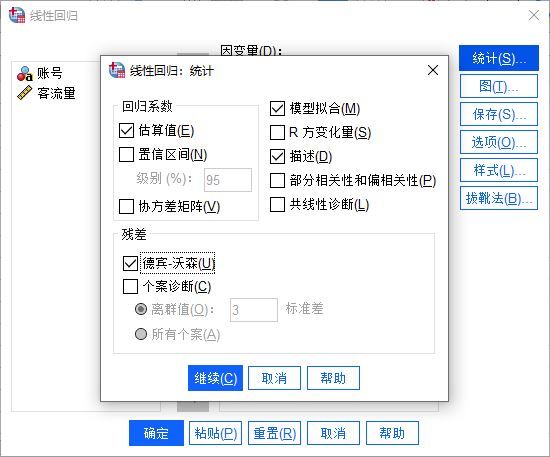
图5:统计方法 第四步,设置参考图表,比如标准化残差图中的“直方图”、“正态概览图”,用于辅助分析残差的自相关性、正态性,检验模型是否具有统计学意义。
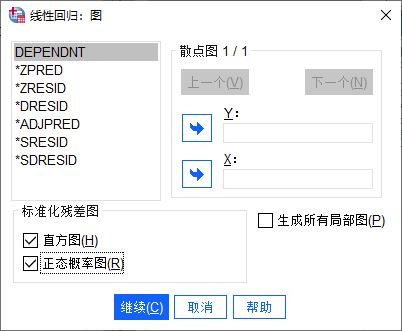
图6:标准化残差图 第五步,如果在回归方程中需要设置常数项,需在“选项”设置中勾选“在方程中包括常量”。
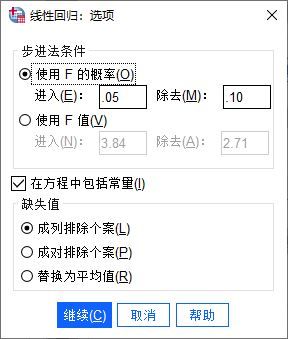
图7:选项设置 二、回归分析SPSS结果解读
完成以上SPSS的设置后,即可进行运算获取结果,我们需要从模型拟合度、残差是否具有自相关来检验回归方程是否具有统计学意义,以及判断其预测的准确度。
a.模型拟合效果
模型摘要,求得的回归方程R方为0.839,R方数值越接近于1,说明方程的拟合优度越好,一般需要大于0.6。本例回归方程R方为0.839,说明本例分析所得的回归方程拟合效果良好。
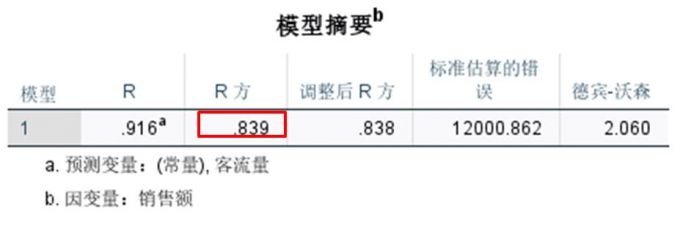
图8:模型摘要 ANOVA分析,回归模型的显著性值为0.00,小于0.05的置信空间,即说明有95%的概率拒绝原假设(原假设为客流量与销售额之间无回归关系),也就是说,客流量与销售额之间存在着显著的回归关系。
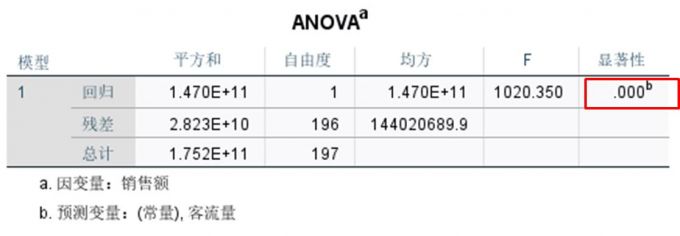
图9:ANOVA检验 b.残差相关性分析
通过回归方程R方、ANOVA分析,可得知回归方程具有统计学意义,但模型是否具有准确的预测性,还需要通过残差相关性分析进一步确认。如果残差存在自相关的话,模型的预测准确度就不高。
查看模型摘要中的德宾-沃森值为2.060,查阅德宾-沃森表得到,样本量n=198(采用200样本量D-W值),控制变量数量k=1,其下临界值LD=1.664、上临界值UD=1.684。
而本例的德宾-沃森值为2.060,根据判定规则,本例回归方程符合“如果UD
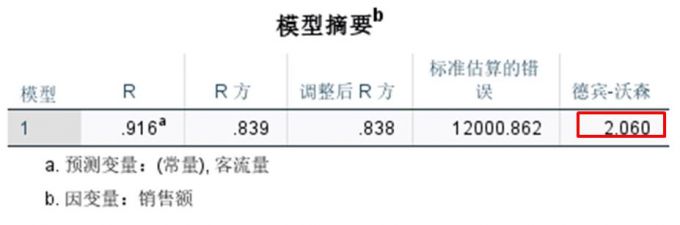
图10:D-W检验 残差直方图,可查看到残差的分布趋近于正态曲线的分布。
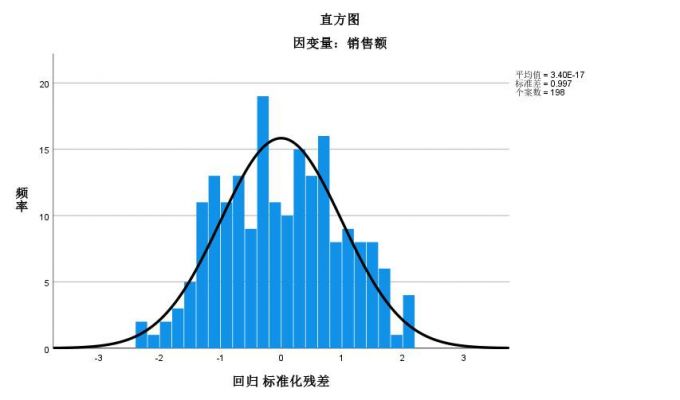
图11:残差直方图 再结合正态P-P图分析,数值的分布近似与直线,说明残差的正态性良好。
在满足残差无自相关性、服从正态分布的前提下,说明该回归方程具有良好的预测性。
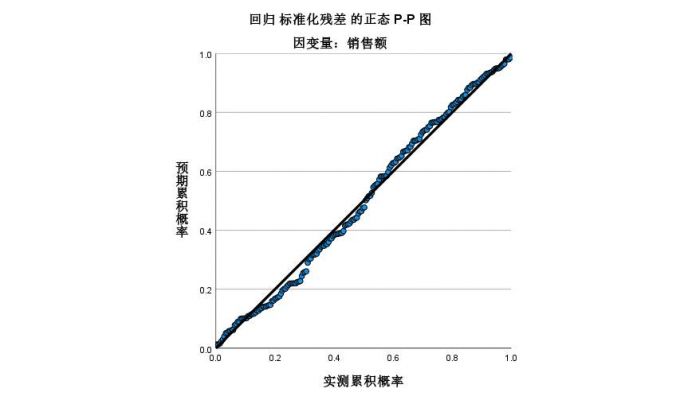
图12:残差P-P图 c.构建模型表达式
在判定回归模型统计学意义、残差无自相关性、残差满足正态分布的前提下,可求得回归方程的回归系数,从而构建回归方程。
系数分析表,客流量回归系数的显著性数值为0.00<0.05,有95%概率拒绝原假设;而常量系数的显著性为0.4,无法拒绝原假设。说明自变量回归系数具有统计学意义,而常量系数不具有统计学意义,可构建y=12.821x的一元线性回归方程。
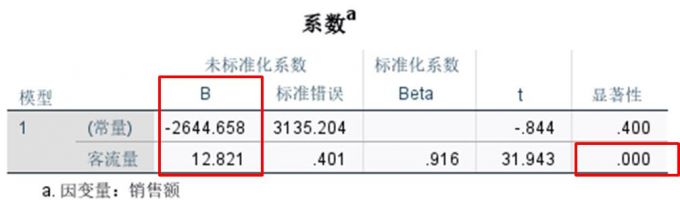
图13:选择变量 三、回归分析有哪些类型
在上文的示例中,我们演示了简单的一元线性回归分析,那么,除此以外,回归分析还包含哪些类型呢?
回归分析包含了线性回归与非线性回归分析,其中:
1.线性回归分析,可分为一元线性回归分析(一个自变量X与因变量Y的关系)与多元线性回归分析(多个自变量与因变量Y的关系)
2.非线性回归分析,也称为曲线回归,根据因变量是定量变量或定性变量可分为Logistic回归、有序回归、Probit回归等。非线性回归分析由于模型未知,其分析情况会更为复杂,常需要借助图表归纳,或简化为多元线性回归来分析。
四、小结
以上就是回归分析SPSS步骤,回归分析SPSS结果解读的相关内容。本文重点演示了SPSS中的一元线性回归分析的步骤,其中会涉及到回归方程的共线性、残差相关性、残差正态性、方程拟合优度等指标的使用。
作者:泽洋
展开阅读全文
︾
标签:一元线性回归分析,回归分析,二元回归分析,有序回归分析
读者也访问过这里:热门文章SPSS数据分析显著性差异分析步骤 SPSS显著性差异分析结果怎么看数据的显著性差异分析主要有三种方法,分别是卡方检验、T检验和方差分析。这三种方法都有具体的数据要求:卡方检验是对多个类别的数据进行分析,T检验是对两组数据进行分析,方差分析是对多组数据进行检验。下面,小编具体说明一下SPSS数据分析显著性差异分析步骤,SPSS显著性差异分析结果怎么看。2022-01-07实践SPSS单因素方差分析之检验结果解读在《实践SPSS单因素方差分析之变量与检验方法设置》一文中,我们已经详细地演示了IBM SPSS Statistics单因素方差分析方法的变量选择以及相关的选项、对比设置。2021-01-11spss如何做显著性分析 spss显著性差异分析怎么标abc在统计分析中,显著性分析是分析相关因素之间是否存在显著影响关系的关键性指标,通过它可以说明分析结论是否由抽样误差引起还是实际相关的,可论证分析结果的准确性。下面大家一起来看看用spss如何做显著性分析,spss显著性差异分析怎么标abc。2022-03-14SPSS回归分析中的f值是什么 SPSS回归分析F值在什么范围合适回归分析中以R表示相关性程度的高低,以F评价回归分析是否有统计学的意义,使用IBM SPSS Statistics进行回归分析,可以非常快速的完成R,F的计算,并且给出回归曲线方程,那么,SPSS回归分析中f值是什么?SPSS回归分析F值在什么范围合适,本文结合实例向大家作简单的说明。2022-07-22SPSS多元logistic回归分析的使用技巧回归分析是数据处理中较为常用的一类方法,它可以找出数据变量之间的未知关系,得到较为符合变量关系的数学表达式,以帮助用户完成数据分析。2021-04-26SPSS相关性分析结果怎么看相关性分析是对变量或个案之间相关度的测量,在SPSS中可以选择三种方法来进行相关性分析:双变量、偏相关和距离。2021-04-23最新文章SPSS如何绘制茎叶图 SPSS茎叶图怎么分析我们在进行数据分析的过程中,可以借助数据分析后绘制的图像来辅助我们解读数据。数据分析图像能够更加直观地表现出数据的变化幅度以及分布状况,而在数据分析的图像中,茎叶图能够在保留数据信息的同时展现数据样本的轮廓。所以茎叶图就可以成为我们数据分析的一个重要工具,但是许多小伙伴对茎叶图的绘制和使用并不熟悉。下面以SPSS为例,给大家介绍SPSS如何绘制茎叶图,SPSS茎叶图怎么分析的具体内容。2026-07-01SPSS怎么对多选题进行频率分析 SPSS频率分析怎么做我们在问卷数据分析过程中,常常会遇到多选题。这时候,常规的频率分析可能就无法适配多选项的计数需求,而SPSS中的多重响应功能可精准完成多选题的频率统计,同时也能通过基础频率分析功能完成单选题的常规统计。接下来我将为大家介绍:SPSS怎么对多选题进行频率分析,SPSS频率分析怎么做的相关内容。2026-07-01SPSS回归分析加入中介变量怎么做 SPSS中介效应分析结果解读相信大家在进行社会科学研究的时候,常常使用到中介效应分析这个方法。中介效应分析能够清晰地揭示自变量对因变量的影响是否通过中介变量进行传递,让变量间的作用路径更明确。接下来我将为大家介绍:SPSS回归分析加入中介变量怎么做,SPSS中介效应分析结果解读的相关内容。2026-06-02SPSS随机性检验步骤分析 SPSS随机性检验结果分析数据序列的随机性是保障后续统计检验有效性的重要前提,如果出现了非随机分布的数据。有可能会导致分析结果出现偏差。在SPSS中,我们通过游程检验可以快速完成数据随机性的判断。接下来我将为大家介绍:SPSS随机性检验步骤分析,SPSS随机性检验结果分析的相关内容。2026-06-02SPSS绘制箱线图步骤 SPSS箱线图怎么分析SPSS作为一款功能比较齐全的数据统计分析软件,其绘图功能是很全面的,除了常规的条形图、饼形图、折线图外,还有在各种调研报告中常用到的箱线图,可能有些读者朋友不知道怎么用SPSS绘制箱线图,下面将以实际数据给大家在SPSS中演示SPSS绘制箱线图步骤,SPSS箱线图怎么分析。2026-06-022026-06-02读者也喜欢这些内容:
-
SPSS 安装激活流程
...
阅读全文 >
-
SPSS反向计分怎么转换 SPSS反向计分会影响结果吗
在数据分析的领域中,反向计分是我们用来统一变量方向的一种数据分析方式,它不仅可以转换变量的方向,还能够用来对数据样本进行清洗,达成前面说到的统一变量的情况。反向计分在许多数据分析场景中都有应用,例如我们在进行访问调查的时候提出两个问题,一个是“我今天开心”,另一个是“我今天难过”,针对不同问题的同一回答却会导向不同的结果。所以我们需要用到反向计分的统计方法统一变量的方向。下面以SPSS为例,给大家介绍SPSS反向计分怎么转换,SPSS反向计分会影响结果吗的具体内容。...
阅读全文 >
-
SPSS随机抽取30%的样本 SPSS随机抽取30%的研究对象
在社会统计学或加工生产领域,我们为了了解某批次数据的整体状态,常常会使用随机取样的方式进行分析,以小批次数据的分析结果为蓝本,来判断整组数据的合理性。今天我就以SPSS随机抽取30%的样本,SPSS随机抽取30%的研究对象这两个问题为例,来向大家演示一下在SPSS中执行随机抽取的详细步骤。...
阅读全文 >
-
SPSS怎么算中位数和四分位数 SPSS如何计算平均数和标准差的差值
SPSS功能强大且丰富多样,不仅能完成数值计算与比对,还具备多种检验功能,可帮助我们精准识别和提取异常数值。同时,SPSS还能高效分析各类数据,比如计算中位数、四分位数、平均数和标准差等等。今天我们将详细介绍SPSS怎么算中位数和四分位数,SPSS如何计算平均数和标准差的差值的相关内容。...
阅读全文 >
-




