




仅剩:

发布时间:2021-06-18 14: 21: 12
说起病例对照研究,相信各位小伙伴们都不陌生。简单来说,就是把患有某种疾病的一组病人作为病例组,不患该疾病但是可进行对比试验的另一组作为对照组,通过两组别进行比较,从而推断出某些因素和疾病之间的关联。
因此本节中,我们将一起学习如何使用SPSS软件,设置病例组与对照组的一比一个案控制匹配。
一、个案控制匹配设置
目前对于是否有吸烟习惯和高血压之间的关系存在着一定的争议,本文搜集了高血压组与正常组共2100条数据,数据如下图1。此时的数据是混合在一起的,并没有进行一一匹配,下面我们将使用此数据,进行病例与对照组的数据匹配。
图1:演示混合数据
选择【数据】中的【个案控制匹配】菜单,进行病例组和对照组的数据匹配,如果我们没有找到此菜单的话,则需要在扩展中心中搜索“Fuzzy”进行扩展安装。
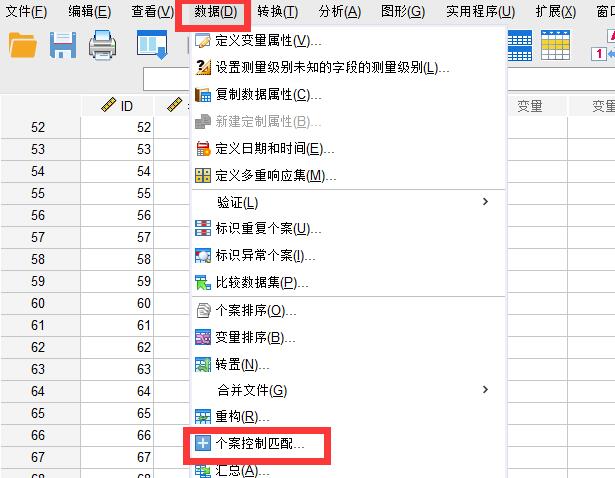
图2:个案控制匹配
接着在“个案控制匹配”界面中,设置匹配依据变量为“年龄”和“性别”,匹配容差为“2 0”,2和0之间注意要用空格隔开。前面的2表示,我们可接受病例组和对照组之间的年龄差为2岁,后面的0,因为性别非连续变量,所以输入0。
随后设置组指示符为“高血压”,个案ID为“ID”;最后再填入匹配ID变量名和匹配组变量名,随意命名即可,如命名为“匹配到的ID”和“匹配到的组别”。
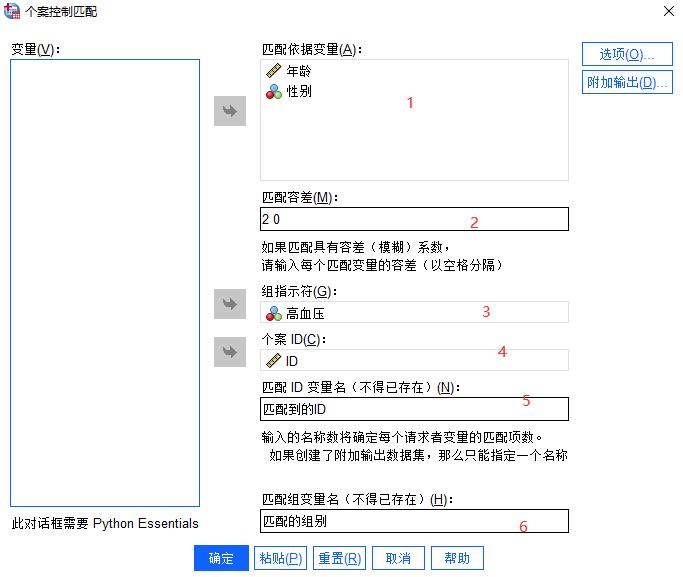
图3:个案控制匹配步骤
点击“选项”按钮,进入个案控制选项设置。我们设置抽样选项为不放回抽样,并勾选“最优化执行性能”,同时还需要勾选上“抽取匹配项时随机排列个案顺序”以及设置一个随机数种子,如123456,具体设置如下图。
设置随机种子是为了使得我们的匹配过程是可复现的,防止每次都产生随机结果,无法再次复现匹配过程。

图4:选项设置
点击“附件输出”按钮,设置将匹配结果输出到一个新的数据集中,数据集名称可任意,如“newdata”。

图5:输出到新数据集中
二、匹配结果
最后生成出来的匹配结果的新数据集如下图6所示,共206条匹配数据。新数据集比原数据集多出了两列,分别是“匹配到的组别”和“匹配到的id”。其中ID为92的与ID为91的就是一个病例组和对照组。
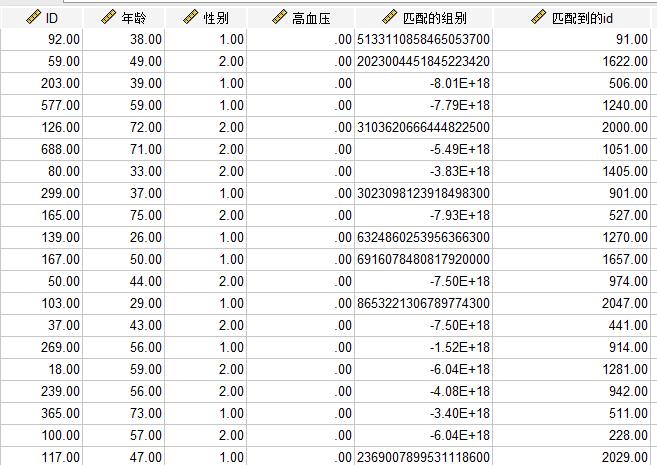
图6: 新数据集展示
在个案控制匹配结果表格中,也非常明确地表示出,完全匹配结果有50条,模糊匹配结果有156条。
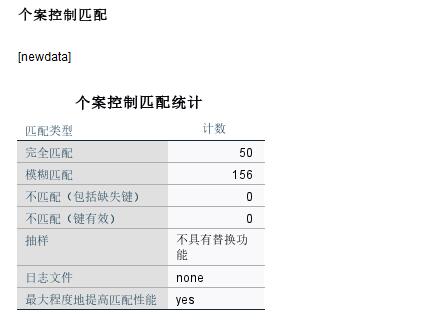
图7:个案控制匹配结果
按照上述几步我们就完成了个案控制匹配,将病例组和对照组一一匹配在一起,且两者的误差符合我们的实验需求。接下去我们就可以用获得的这些比对数据,采用SPSS中的其他模型方法,进行更深入的探索和研究了。
作者署名:包纸
展开阅读全文
︾
读者也喜欢这些内容:

SPSS软件安装与注册试用教程
IBM SPSS Statistics作为一款全球知名的数据统计分析软件,无论是在学术研究领域,还是商业经营领域,都起着举足轻重的作用。其推出的一系列统计分析方法,可用于数据的分析运算、挖掘、模型预测等多个方面。...
阅读全文 >
SPSS怎么计算Z分数 SPSS标准化后原始值怎么还原
假设小明在期末考试中语文考了90分、数学考了85分,我们可以很轻易地比较出小明的语文分数是高于数学的,但是这就能说明他的语文比数学要好吗?显然不能,我们还需要比较小明所在班级的平均分,假如数学平均分为70标准差为10、语文平均分为82标准差为8,那么实际上小明的数学z分数为1.5,语文成绩为1.0,因此小明的数学成绩在班级中的排名是高于语文成绩在班级中的排名的,即实际上小明的数学成绩考得更好。Z分数就是这样帮助我们比较不同维度数据的一种统计工具。接下来我就给大家介绍一下SPSS怎么计算Z分数,SPSS标准化后原始值怎么还原。...
阅读全文 >
SPSS显著性小于0.001的意义 SPSS显著性大于0.05怎么办
在使用SPSS软件进行数据分析工作的过程中,得到的显著性水平分析结果具有极为重要的作用。它能够帮助我们衡量变量之间是否存在真实的关联,或者不同组别数据之间是否存在实质性的差异。今天我们就一起来探讨关于SPSS显著性小于0.001的意义,SPSS显著性大于0.05怎么办的问题。...
阅读全文 >
SPSS合并数据文件的方式有哪些 SPSS合并数据如何配对
作为一名优秀的数据分析师,合并数据是我们需要学习的基础操作之一。通过合并文件命令,我们可以将不同的原始数据整合成一份完整的文档,这样有助于我们进行后续的模型分析和汇总工作。今天我就以SPSS合并数据文件的方式有哪些,SPSS合并数据如何配对这两个问题为例,来为大家讲解一下有关合并数据的相关知识。...
阅读全文 >
