


- 首页
- 产品
- 下载
- 学生专享NEW
-
帮助中心
IBM SPSS Statistics中分层聚类法的实际应用
发布时间:2021-09-22 16: 08: 52
IBM SPSS Statistics中的分层聚类法,也称作系统聚类法,是按照度量数据距离的远近,对预先设定的分类范围进行聚类的分析方法。其优点是可设定分类的范围、可处理分类变量与连续变量、可选择的数据距离计算方法多等。
但需要注意的是,分层聚类法无法同时处理两种变量类型,即单次分析只能在同一种变量类型中进行。接下来,我们通过实例具体演示下操作方法。
一、数据准备
本文使用到的是一组包含连续变量(销售额、销售量等)与分类变量(店铺类型、星级等)的店铺数据。
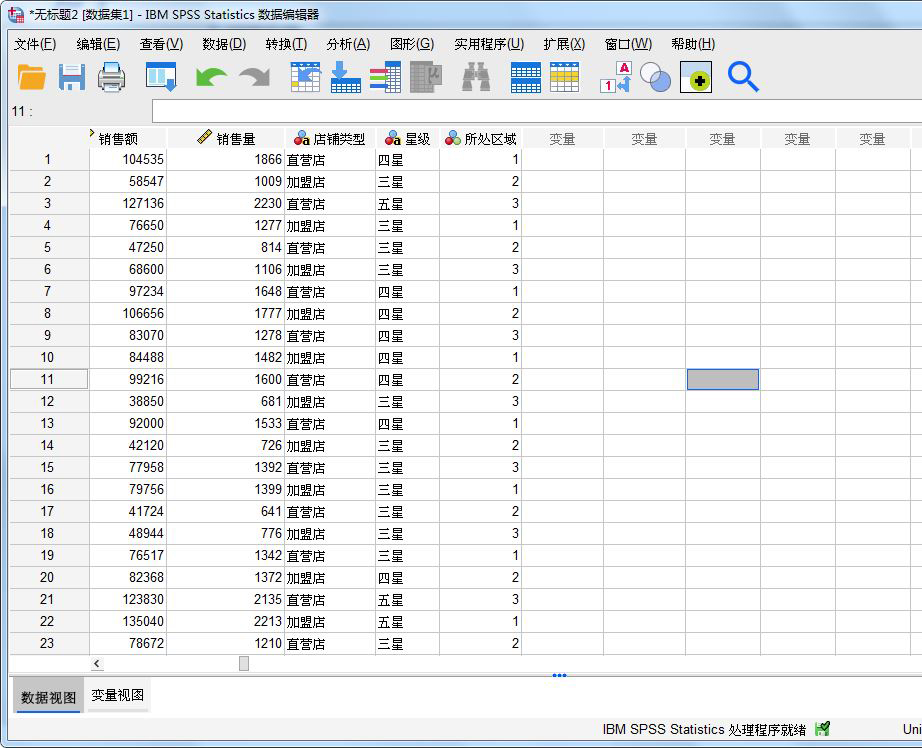
图1:店铺数据 二、系统聚类参数设置
如图2所示,依次打开SPSS的分类-系统聚类分析。
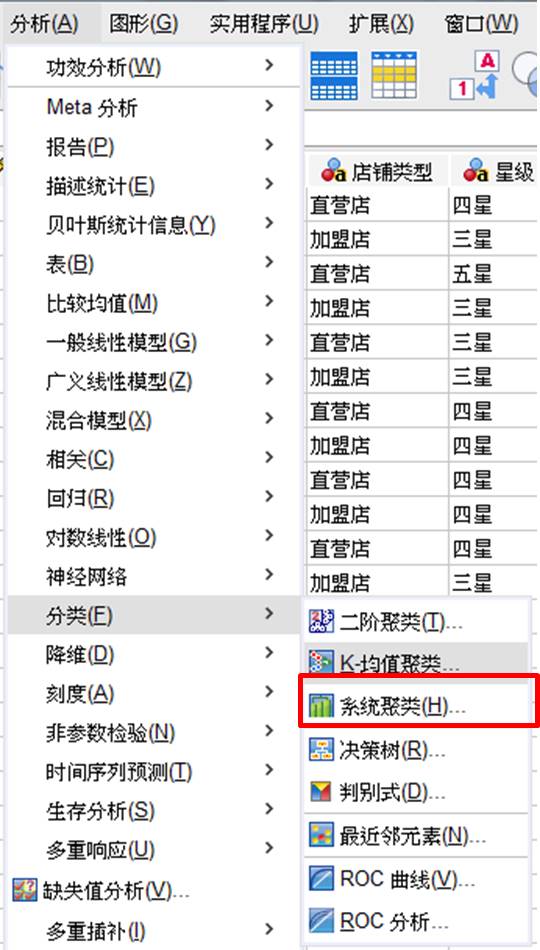
图2:系统聚类 如图3所示,SPSS的系统聚类可进行个案与变量的聚类分析。本例选择个案的系统聚类分析。
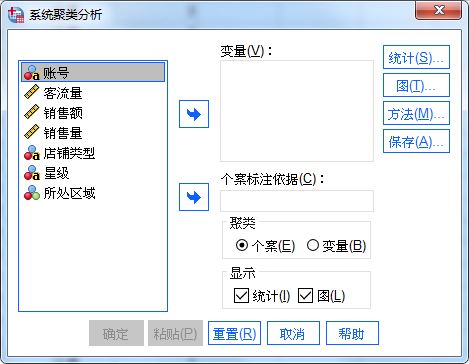
图3:设置面板 系统聚类单次只可分析一种变量类型,如图4所示,本例进行的是客流量、销售额、销售量的连续型变量系统聚类分析,以账号作为标注依据。
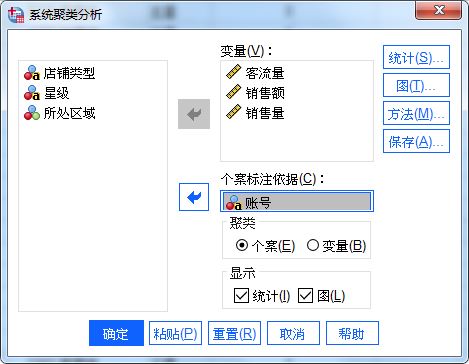
图4:变量设置 在统计设置中,如图5所示,勾选“解的范围”,并将范围设定为2-5。
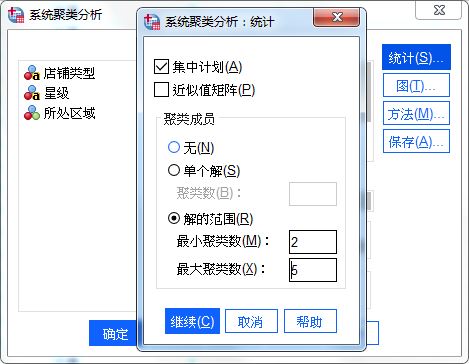
图5:统计设置 在图设置中,勾选“谱系图”选项,以观察聚类的过程。
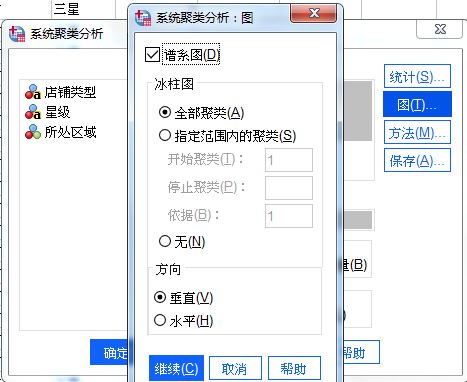
图6:图设置 在计算方法中,根据连续变量使用欧氏距离法,分类变量使用计数型卡方测量法的原则,设置区间的平方欧式距离法。
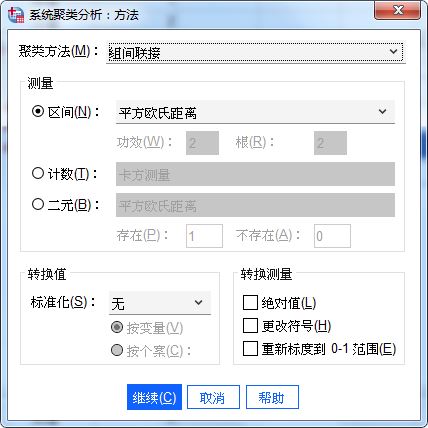
图7:方法设置 最后,在保存设置中,保存“解的范围”,以在数据表中生成解范围的新变量。
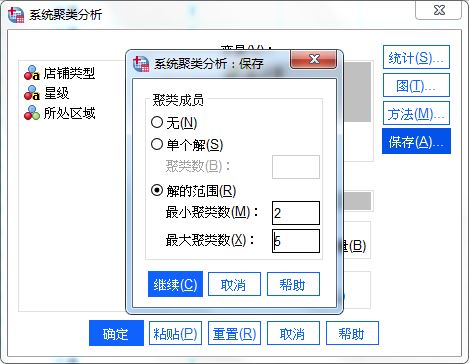
图8:解的范围 三、结果解读
运行分析后,返回到数据集,如图9所示,在原数据集的末端生成了新的变量,分别展示的是解在2-5范围时,个案所属的聚类。
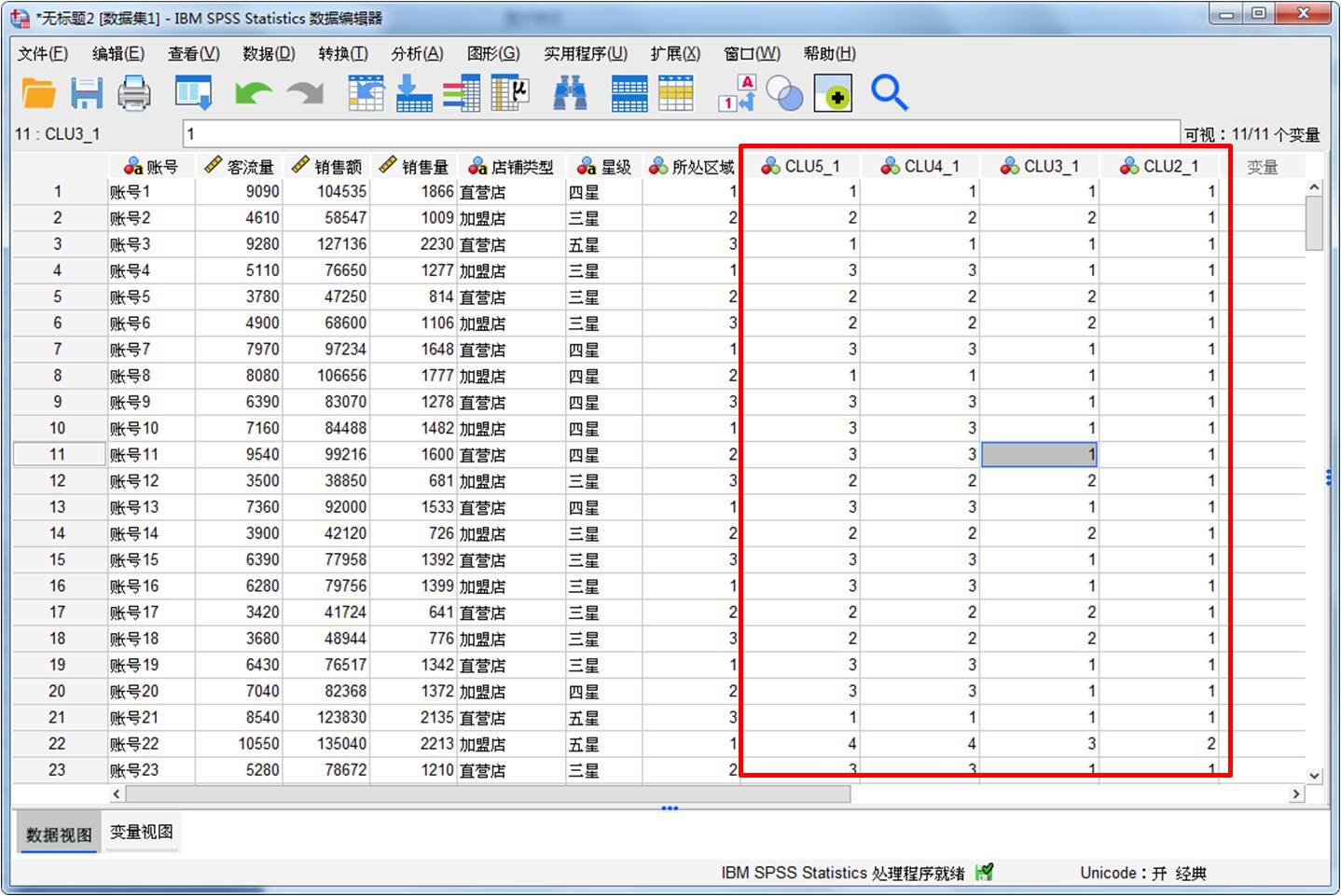
图9:生成新变量 本次系统聚类分析了23个个案,从集中计划表看到,在第5阶段,15与16聚合为一类,15在第4个阶段中出现了,16则是第一次出现,因此在聚类中分别记为“4”与“0”。
在进行22个阶段后,所有个案完成聚类。
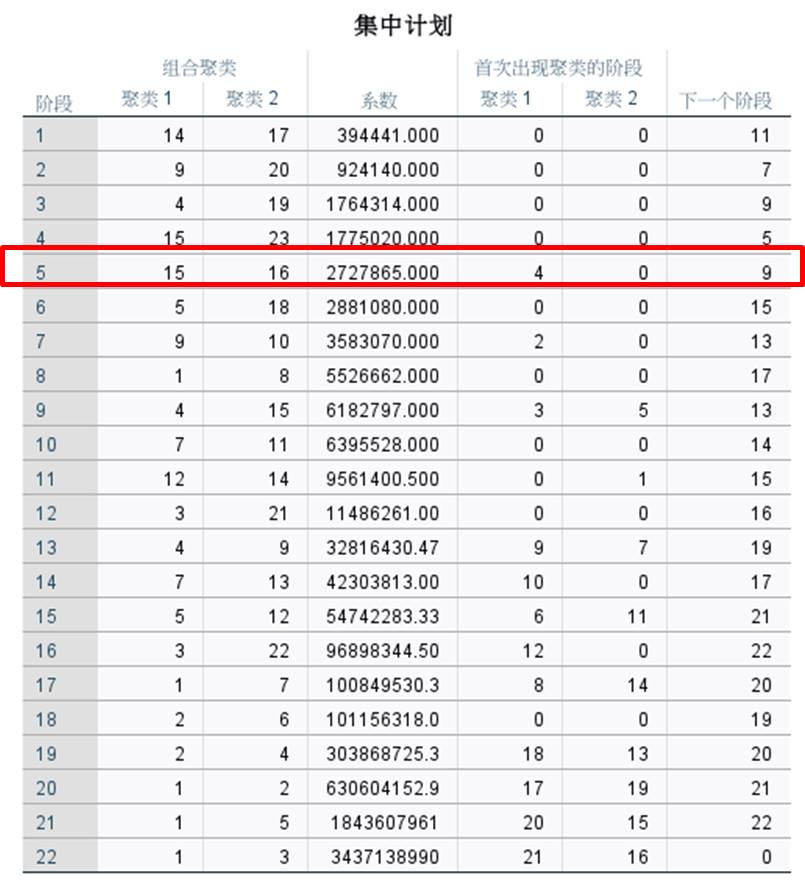
图10:集中计划 如图11所示,在谱系图中画红色竖线并向左观察,可将个案分为三大类。当然,也可以移动红色竖线,将个案分为两大类、四大类、五大类,并观察其个案的组成。
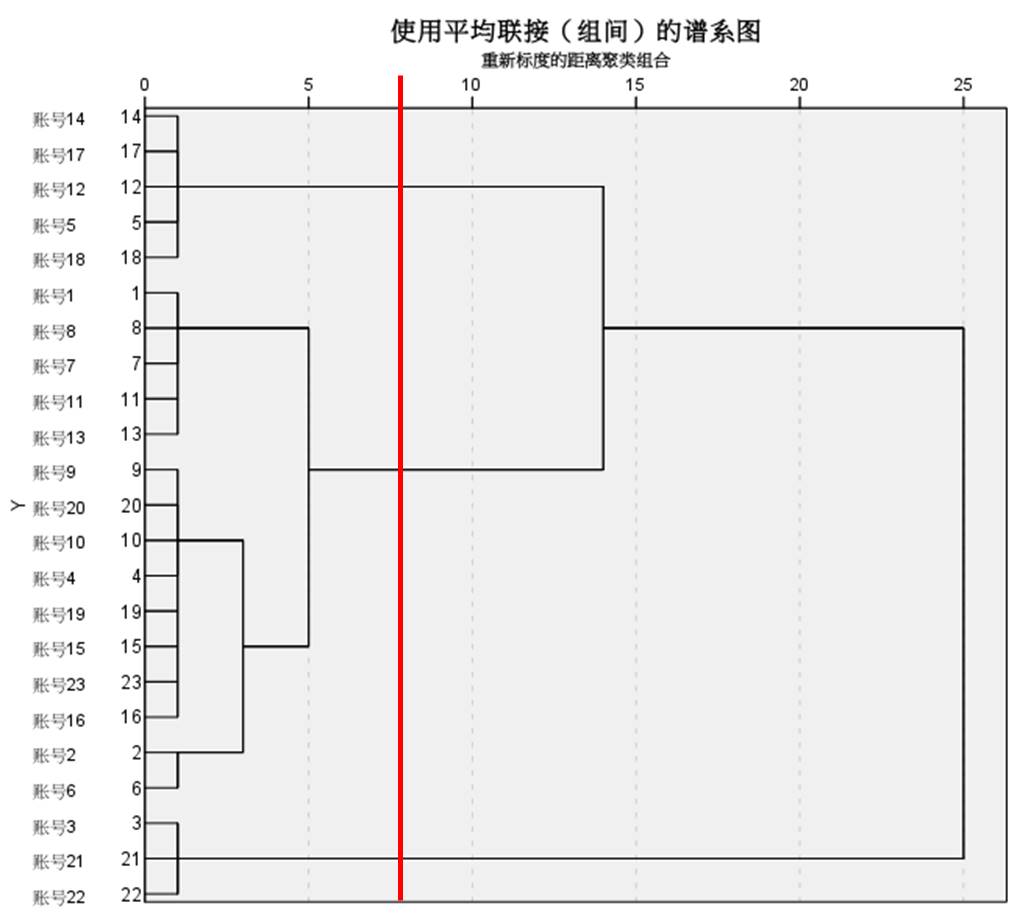
图11:谱系图 四、小结
综上所述,SPSS分层聚类分析可进行连续型与分类型变量的聚类分析,并设定解的范围,使得数据在预设的范围内进行聚类。
但另一方面来说,分层聚类主要是依靠图形,如谱系图进行聚类结果的输出,因此,如果个案数目过大,将不利于结果的观察。
作者:泽洋
展开阅读全文
︾
标签:IBM SPSS Statistics,分层聚类法
读者也访问过这里:热门文章SPSS数据分析显著性差异分析步骤 SPSS显著性差异分析结果怎么看数据的显著性差异分析主要有三种方法,分别是卡方检验、T检验和方差分析。这三种方法都有具体的数据要求:卡方检验是对多个类别的数据进行分析,T检验是对两组数据进行分析,方差分析是对多组数据进行检验。下面,小编具体说明一下SPSS数据分析显著性差异分析步骤,SPSS显著性差异分析结果怎么看。2022-01-07实践SPSS单因素方差分析之检验结果解读在《实践SPSS单因素方差分析之变量与检验方法设置》一文中,我们已经详细地演示了IBM SPSS Statistics单因素方差分析方法的变量选择以及相关的选项、对比设置。2021-01-11spss如何做显著性分析 spss显著性差异分析怎么标abc在统计分析中,显著性分析是分析相关因素之间是否存在显著影响关系的关键性指标,通过它可以说明分析结论是否由抽样误差引起还是实际相关的,可论证分析结果的准确性。下面大家一起来看看用spss如何做显著性分析,spss显著性差异分析怎么标abc。2022-03-14SPSS回归分析中的f值是什么 SPSS回归分析F值在什么范围合适回归分析中以R表示相关性程度的高低,以F评价回归分析是否有统计学的意义,使用IBM SPSS Statistics进行回归分析,可以非常快速的完成R,F的计算,并且给出回归曲线方程,那么,SPSS回归分析中f值是什么?SPSS回归分析F值在什么范围合适,本文结合实例向大家作简单的说明。2022-07-22SPSS多元logistic回归分析的使用技巧回归分析是数据处理中较为常用的一类方法,它可以找出数据变量之间的未知关系,得到较为符合变量关系的数学表达式,以帮助用户完成数据分析。2021-04-26SPSS相关性分析结果怎么看相关性分析是对变量或个案之间相关度的测量,在SPSS中可以选择三种方法来进行相关性分析:双变量、偏相关和距离。2021-04-23最新文章SPSS中如何将年龄分段筛选出来 SPSS如何将年龄从字符串改为数字在进行社会科学研究时,往往会需要进行调研。在调研之后,我们做调研数据处理时,可能会遇到格式不整齐的情况,例如变量并非单纯的数字,而是包含了“岁”等单位。这样的字符串格式的年龄不能直接用于数据分析,而是必须先转换成纯数字。接下来我将为大家介绍:SPSS 中如何将年龄分段筛选出来,SPSS如何将年龄从字符串改为数字的相关内容。2026-07-02SPSS中如何将字符串变量转换为数值 SPSS字符串数据怎么处理我们在用问卷收集数据的时候,难免要设置一些开放题。由于开放题没有固定的答案,所以比较难事先做好编码,一般都是将答案收集好后再整理。因此,将数据导入SPSS后,可能会有一些字符串的变量,需要进行二次处理。接下来我们会介绍SPSS中如何将字符串变量转换为数值,SPSS字符串数据怎么处理的相关内容。2026-07-02SPSS的检验方法有哪些 SPSS如何做z检验在做研究分析时,我们可能要做各种数据的检验运算,比如看数据是否满足正态性、方差齐性,看各种组别的数值是否有统计学差异等。SPSS提供了很多实用的分析方法、参考图表等功能,可以快速而简单地做好数据的检验,接下来我们会介绍SPSS的检验方法有哪些,SPSS如何做z检验的相关内容。2026-07-02SPSS中的F值是什么 SPSS中P值和F值如何计算在SPSS得出的运算结果中,会出现一些F值、P值等结果,对于初学者来说,这些统计量可能会有点陌生,但它们在数据研究中,有着重要的意义。其实不仅是SPSS,其他同类型的统计软件也会出现这些统计量。接下来我们会介绍SPSS中的F值是什么,SPSS中P值和F值如何计算的相关内容,让大家可以更熟悉这方面的内容。2026-07-02SPSS验证假设需要什么分析 SPSS假设检验模型一模型二模型三是什么意思假设验证,是很多数据研究里面会用到分析方法,可以用来看数据是否有差异、是否满足正态性、方差是不是相等等。验证假设用到的分析方法,会因为不同的数据类型、研究方向等而有所不同,它们会影响到我们要选择的方法,比如t检验、ANOVA等。接下来我们会介绍SPSS验证假设需要什么分析,SPSS假设检验模型一模型二模型三是什么意思的相关内容。2026-07-02SPSS如何做m±sd分析 SPSS如何做验证性因素分析SPSS有很多好用的数据统计分析功能,像日常用到的均值、标准差等统计量,SPSS可以轻松用“描述”等方法快速计算出来。对于比较专业、复杂的分析方法,SPSS也有提供到相关的功能,比如降维、聚类、因子分析等,都可以在SPSS里面使用到。接下来我们会介绍SPSS如何做m±sd分析,SPSS如何做验证性因素分析的相关内容。2026-07-02读者也喜欢这些内容:
-
SPSS数据转置什么意思 SPSS数据转置怎么操作
在进行SPSS数据计算和分析之前,研究者通常运用SPSS数据转置的方法,借此对繁杂数据进行行列互换,适用于EXCEL、CSV、文本数据、SAS等各类形式的数据文本,便于研究者清晰全面地了解数据信息。本文以SPSS数据转置什么意思,SPSS数据转置怎么操作这两个问题为例,带大家了解一下SPSS数据转置的相关知识。...
阅读全文 >
-

SPSS协方差分析操作步骤 SPSS协方差分析变量怎么选择
在数据统计中,我们可能会遇到多个变量存在相关关系的情况,可以运用SPSS协方差的方法来分析庞杂数据组的多类自变量以及因变量之间的关系,有助于减弱变量共线性等问题。今天,我们以SPSS协方差分析操作步骤,SPSS协方差分析变量怎么选择这两个问题为例,带大家了解一下SPSS协方差分析的相关知识。...
阅读全文 >
-

SPSS怎么排除无效数据 SPSS怎么排除无效问卷
在做调查问卷时,如果用户遇到不想回答问卷而又不得不回答的情况时,他们可能就会重复选择某个选项,这种重复选择的问卷就是无效样本。所以我们在做问卷调查结果分析时,首先需要对数据进行预处理,检查数据中是不是存在无效样本,那在SPSS中怎么排除无效数据,SPSS怎么排除无效问卷呢?我们一起来看下。...
阅读全文 >
-
SPSS数据输入百分数怎么输入 SPSS百分比数据如何进行处理
SPSS不仅是一款功能比较强大的数据统计分析软件,还应用于很多研究领域,像是社会学科、教育学科、医疗研究等领域,都会使用SPSS进行数据统计分析。为了让大家对SPSS有更进一步的了解,下面给大家详细讲解,SPSS数据输入百分数怎么输入,以及SPSS百分比数据如何进行处理。...
阅读全文 >
-





