


- 首页
- 产品
- 下载
- 学生专享NEW
-
帮助中心
spssk均值聚类分析步骤 spssk均值聚类分析结果解读
发布时间:2022-06-28 10: 04: 40
品牌型号:联想GeekPro 2020
系统: Windows 10 64位专业版
软件版本: IBM SPSS Statistics
spssk均值聚类分析步骤,spssk均值聚类分析需事先指定聚类数目k,然后再依照该聚类数目进行迭代运算,本文会应用例子演示分析步骤,同时也会进行spssk均值聚类分析结果解读,以加深理解。
一、spssk均值聚类分析步骤
spssk均值聚类分析,与系统聚类、二阶聚类等同属spss的分类分析,目的是将相似的个案归纳总结、分类,以找到个案间的相似点。spssk均值聚类是一种确定性的聚类分析,需事先指定聚类的数量,适用于有指定分类、分类数目固定的情况。
以一组店铺数据为例,目的是应用一些标准指标对店铺进行分类,需要注意的是,k均值聚类只能分析数值型变量,对于字符串变量需重新编码成数值。
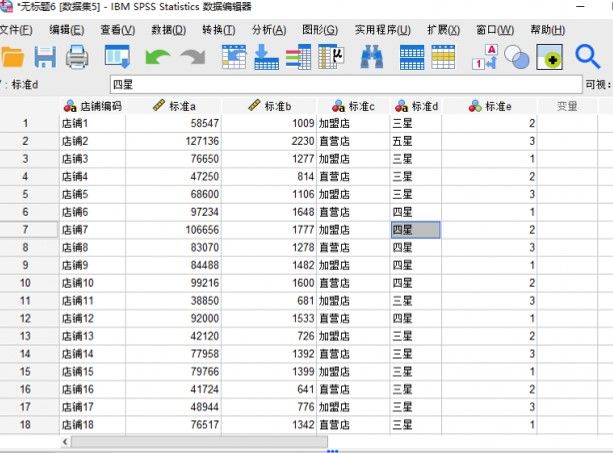
示例数据 打开spss的分析菜单,选择分类中的“K-均值聚类分析”功能。
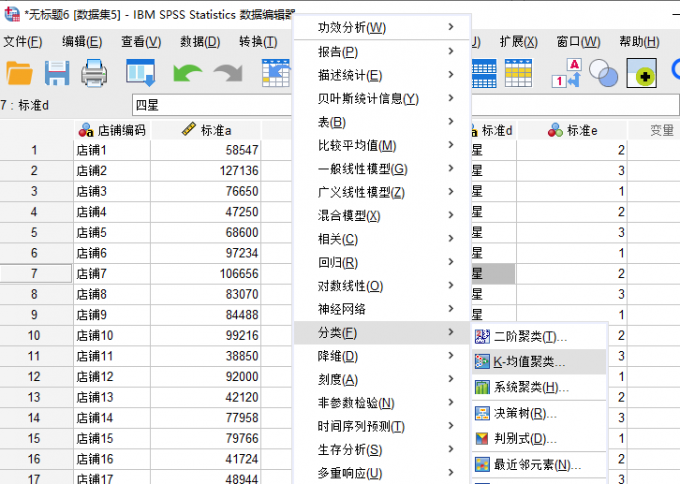
k均值聚类 第一步:设置变量
本例将会使用标准a、标准b与标准e三个指标进行聚类分析,其中原字符串变量“标准e”已重新编码为数值型变量。
将标准a、标准b与标准e三个变量选入“变量”列表框,将“店铺编码”选入个案标注依据,以区别不同的个案。
第二步:设置聚类数
在左侧变量下方进行“聚类数”设置,该数值需要分析者自定,无固定规则。本例设为2,即运算得出2个聚类。
其他方法、聚类中心等,如无特殊需求,可保持默认设置。
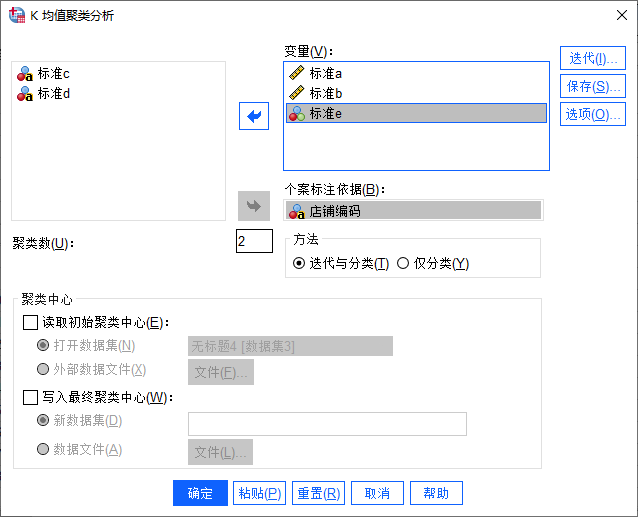
变量设置 第三步:设置保存新变量
“聚类成员”,是在聚类数目事先设定的情况下(本例为2个聚类),运算每个聚类所包含的个案,而从“与聚类中心的距离”,可看出聚类间的相似度,距离越远就越不相似。
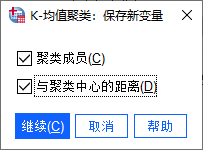
保存新变量 第四步:设置统计量
可选择“初始聚类中心”、“每个个案的聚类信息(所属分类、与中心的距离)”,了解初始聚类与最终聚类的差别(如有的话)。

统计值 二、spssk均值聚类分析结果解读
完成以上设置后进行spss运算分析,并进行最后的步骤,解读数据。
如图6所示,根据初始聚类中心与迭代历史记录,以及实现设定的聚类数据2,数据在第二次迭代后,聚类中心不再变动,以此确认2次迭代。
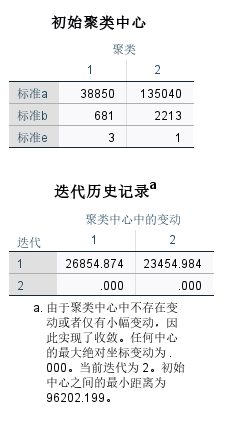
初始聚类中心 在聚类数目为2的情况下,可将店铺个案归类为图7的“聚类成员”列表。
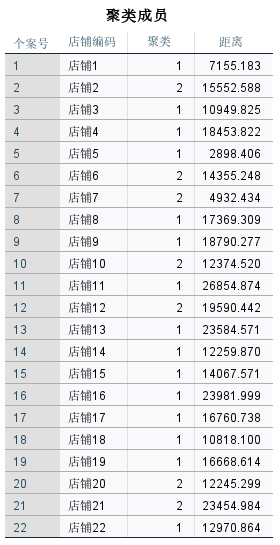
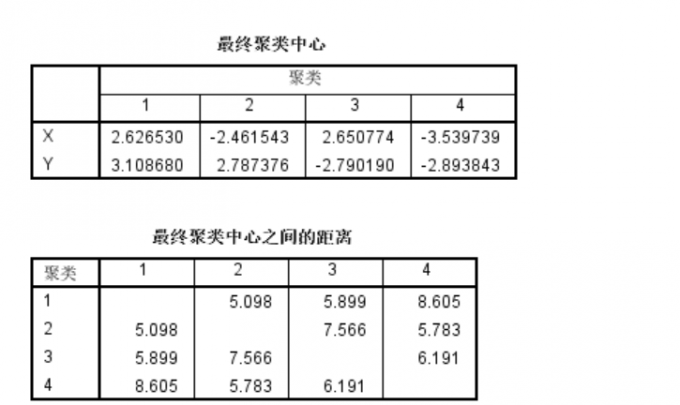
聚类结果 最终运算后,确定最终聚类中心为2,并得到最终聚类中心之间的距离。
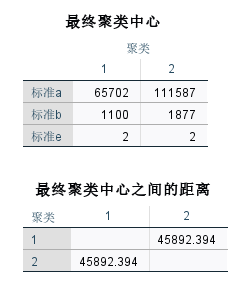
最终聚类中心 其中,聚类1中包含了15个个案,聚类2中包含了7个个案。
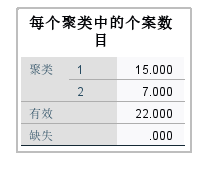
每个聚类中的个案数 三、spssk均值聚类分析的优缺点
spssk均值聚类分析是一种确定性强的聚类分析方法,相对于系统聚类的模糊性,k均值聚类可在指定聚类数目k基础上进行聚类分析,因此可提供确定性的分类信息,但这也决定了k均值聚类不太适合用于模糊性的研究问题。
spssk均值聚类分析优缺点如下:
优点:
1.运算快速、简单
2.可处理大量的个案,相对于系统聚类来说,运算更有效率
3.有确定的聚类数目,结果清晰,无须分析者自行判断
缺点:
1.需要事先设定聚类数目,不适合模糊性研究问题
2.容易受到初值和离群点的影响,可能会造成大量个案归属同一类,而少量极端值归属同一类的情况
3.聚类结果可能无法解释,无法运用分析者经验修正结果
k均值聚类 四、小结
以上就是关于spssk均值聚类分析步骤,spssk均值聚类分析结果解读的相关内容。spssk均值聚类分析适用于确定性分类结果的研究问题,如果是模糊性的研究问题,可采用spss的系统聚类分析,进行探索性的聚类分析。无论是确定性分类,还是模糊性分类,spss都能进行有效地分析。
作者:泽洋
展开阅读全文
︾
标签:IBM SPSS Statistics,均值过程分析,SPSS教程,聚类分析,K均值聚类,SPSS聚类分析,SPSS系统聚类分析,SPSS聚类分析步骤,SPSS软件应用
读者也访问过这里:热门文章SPSS数据分析显著性差异分析步骤 SPSS显著性差异分析结果怎么看数据的显著性差异分析主要有三种方法,分别是卡方检验、T检验和方差分析。这三种方法都有具体的数据要求:卡方检验是对多个类别的数据进行分析,T检验是对两组数据进行分析,方差分析是对多组数据进行检验。下面,小编具体说明一下SPSS数据分析显著性差异分析步骤,SPSS显著性差异分析结果怎么看。2022-01-07实践SPSS单因素方差分析之检验结果解读在《实践SPSS单因素方差分析之变量与检验方法设置》一文中,我们已经详细地演示了IBM SPSS Statistics单因素方差分析方法的变量选择以及相关的选项、对比设置。2021-01-11spss如何做显著性分析 spss显著性差异分析怎么标abc在统计分析中,显著性分析是分析相关因素之间是否存在显著影响关系的关键性指标,通过它可以说明分析结论是否由抽样误差引起还是实际相关的,可论证分析结果的准确性。下面大家一起来看看用spss如何做显著性分析,spss显著性差异分析怎么标abc。2022-03-14SPSS回归分析中的f值是什么 SPSS回归分析F值在什么范围合适回归分析中以R表示相关性程度的高低,以F评价回归分析是否有统计学的意义,使用IBM SPSS Statistics进行回归分析,可以非常快速的完成R,F的计算,并且给出回归曲线方程,那么,SPSS回归分析中f值是什么?SPSS回归分析F值在什么范围合适,本文结合实例向大家作简单的说明。2022-07-22SPSS多元logistic回归分析的使用技巧回归分析是数据处理中较为常用的一类方法,它可以找出数据变量之间的未知关系,得到较为符合变量关系的数学表达式,以帮助用户完成数据分析。2021-04-26SPSS相关性分析结果怎么看相关性分析是对变量或个案之间相关度的测量,在SPSS中可以选择三种方法来进行相关性分析:双变量、偏相关和距离。2021-04-23最新文章SPSS如何验证数据是否符合正态分布 SPSS数据验证怎么用函数计算正态分布,是很多常用的分析方法比如ANOVA方差分析、t检验等,要求数据需要满足的条件。因为满足正态分布的数据,能更加准确地捕捉到差异性,而且它们的总体参数也会更加稳定。在SPSS里面,我们可以通过几种方法来检验数据的分布是否满足需求。接下来我们会介绍SPSS如何验证数据是否符合正态分布,SPSS数据验证怎么用函数计算的相关内容。2026-07-02SPSS变量值设定为0却变成00 SPSS计算变量为什么有空值我们在处理数据样本的过程中,有时候会遇到变量设定错误的问题。就是在设置变量值的时候把变量设定为0,但是实际在数据分析运算的过程中却变成了00,并且在计算变量过程中又出现了空值。出现这种情况可能会直接影响数据分析结果的精准度,因此需通过调整变量类型修正数据。下面以SPSS为例,给大家介绍SPSS变量值设定为0却变成00,SPSS计算变量为什么有空值的具体内容。2026-07-02SPSS中如何将年龄分段筛选出来 SPSS如何将年龄从字符串改为数字在进行社会科学研究时,往往会需要进行调研。在调研之后,我们做调研数据处理时,可能会遇到格式不整齐的情况,例如变量并非单纯的数字,而是包含了“岁”等单位。这样的字符串格式的年龄不能直接用于数据分析,而是必须先转换成纯数字。接下来我将为大家介绍:SPSS 中如何将年龄分段筛选出来,SPSS如何将年龄从字符串改为数字的相关内容。2026-07-02SPSS中如何将字符串变量转换为数值 SPSS字符串数据怎么处理我们在用问卷收集数据的时候,难免要设置一些开放题。由于开放题没有固定的答案,所以比较难事先做好编码,一般都是将答案收集好后再整理。因此,将数据导入SPSS后,可能会有一些字符串的变量,需要进行二次处理。接下来我们会介绍SPSS中如何将字符串变量转换为数值,SPSS字符串数据怎么处理的相关内容。2026-07-02SPSS的检验方法有哪些 SPSS如何做z检验在做研究分析时,我们可能要做各种数据的检验运算,比如看数据是否满足正态性、方差齐性,看各种组别的数值是否有统计学差异等。SPSS提供了很多实用的分析方法、参考图表等功能,可以快速而简单地做好数据的检验,接下来我们会介绍SPSS的检验方法有哪些,SPSS如何做z检验的相关内容。2026-07-02SPSS中的F值是什么 SPSS中P值和F值如何计算在SPSS得出的运算结果中,会出现一些F值、P值等结果,对于初学者来说,这些统计量可能会有点陌生,但它们在数据研究中,有着重要的意义。其实不仅是SPSS,其他同类型的统计软件也会出现这些统计量。接下来我们会介绍SPSS中的F值是什么,SPSS中P值和F值如何计算的相关内容,让大家可以更熟悉这方面的内容。2026-07-02读者也喜欢这些内容:
-
SPSS偏度和峰度的分析步骤 SPSS偏度和峰度的分析结果解读
偏度和峰度是我们在进行数据分析的过程中,判断数据是否符合正态分布的重要标准之一,通过这两个数值可以很清晰地看出数据的整体走势和集中状态。因此这两项数值也经常被用于市场学分析、股市分析中,能够帮忙用户去发现某些潜在的规律。今天我就以SPSS偏度和峰度的分析步骤,SPSS偏度和峰度的分析结果解读这两个问题为例,来向大家讲解一下关于偏度和峰度的相关知识。...
阅读全文 >
-
SPSS怎么处理缺失值 SPSS缺失数据过多如何填补
在临床收集数据时,由于每个患者做的指标不同,影像学检查也存在差异,所以经常会遇到数据缺失的情况。SPSS作为一款专业的数据分析软件,它可以帮助我们分析出哪些指标有缺失值和大概占比多少,以及针对这些缺失数据,利用不同的方法进行填补。今天我们一起来探讨SPSS怎么处理缺失值,SPSS缺失数据过多如何填补的问题。...
阅读全文 >
-
SPSS如何导入日期数据 SPSS导入日期数据后格式不对怎么调整
通过对不同时态下物体的发展状态进行分析,我们可以获得一条明确的发展脉络图,借由这份脉络图,我们可以预测事物未来的发展趋势。今天我就以SPSS如何导入日期数据,SPSS导入日期数据后格式不对怎么调整这两个问题为例,来向大家讲解一下SPSS中关于日期数据的知识。...
阅读全文 >
-
SPSS怎样进行聚类分析 SPSS聚类中心不稳定怎么解决
对于经常需要与数据分析打交道的小伙伴来说,想必对聚类分析这一分析操作肯定是不陌生的。聚类分析指的是收集相似的数据样本,并在相似数据样本的基础之上收集信息来进行分类,下面以SPSS为例,向大家介绍SPSS怎样进行聚类分析,SPSS聚类中心不稳定怎么解决的具体内容。...
阅读全文 >
-





