


- 首页
- 产品
- 下载
- 学生专享NEW
-
帮助中心
使用IBM SPSS Statistics的最近邻元素模型进行数据分析!
发布时间:2022-05-06 14: 18: 21
SPSS的最近邻元素分析是一种分类模型,它是根据个案间的相似性来对个案进行分类。简单来说就是相同个案相互靠近,不同个案相互远离。因此,可以通过判断样本距离哪个离中心点更近,进而判断样本数据属于哪个类别。本篇教程将教大家使用SPSS的最近邻元素模型对汽车行业数据进行数据分析,相信通过学习SPSS的最近邻元素模型,你将能够对各个领域数据分析。
一、 数据准备与数据预处理
为了用最近邻元素模型给大家演示数据分析,这里使用Kaggle实验室的car_sales数据集。主要通过添加两款新研制的车型进行数据分析,这两款预研车型技术指标主要包括Model、Priceinthousands、enginesize、horsepower、width、length、curbweight、fuelcapacity、fueleffciency等。
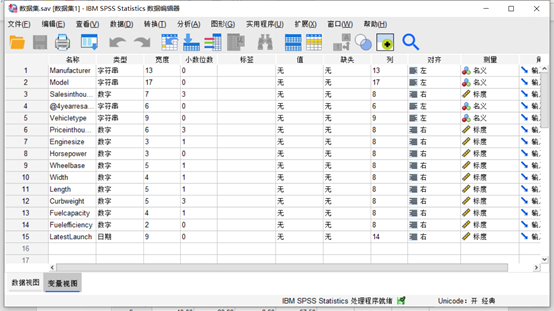
图1数据展示 为了对这款新研发的车型进行分析,这里在原数据添加这两个车型的新记录。
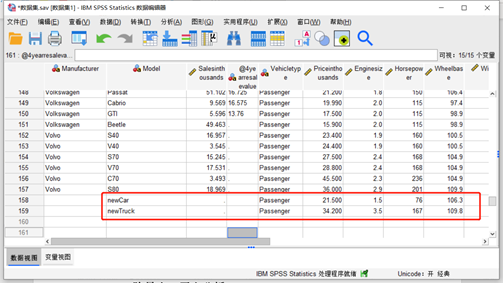
图2新增记录 为了对新记录添加特别关注的标记,因此这里将添加一个名为focal的新变量。点击SPSS顶部菜单栏“转换”-“计算变量”,打开计算变量窗口,目标变量命名为focal,并在数字表达式输入any(Model,'newCar','newTruck')。这个函数表达式意思是Model变量值为'newCar'或者'newTruck',则focal为1,否则为0.
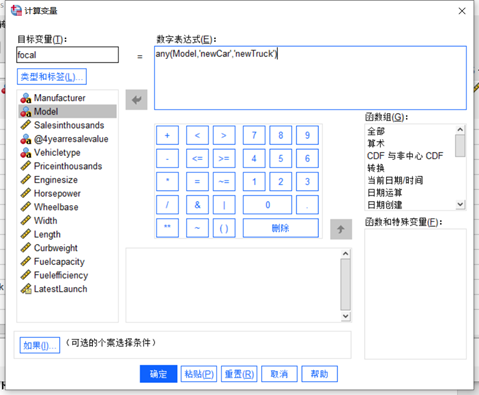
图3新增变量focal 同样通过计算变量方式添加变量partition,用于区分训练数据集和测试数据集,表达式为1-any(Model,'newCar','newTruck')。Partition>0,则为训练数据,否则为测试数据。
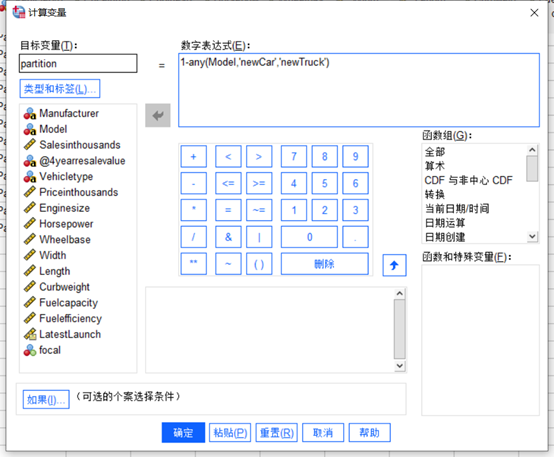
图4新增变量partition 二、最近邻元素模型分析
由于篇幅有限,这里仅展示预估汽车类型。点击SPSS顶部菜单栏“分析”-“分类”-“最小邻元素”。点击顶部“变量”项目进行设置,将vehicletype加载到目标文本框,9个指标加载到特征文本框,focal加载到焦点个案,Model加载到个案标签。
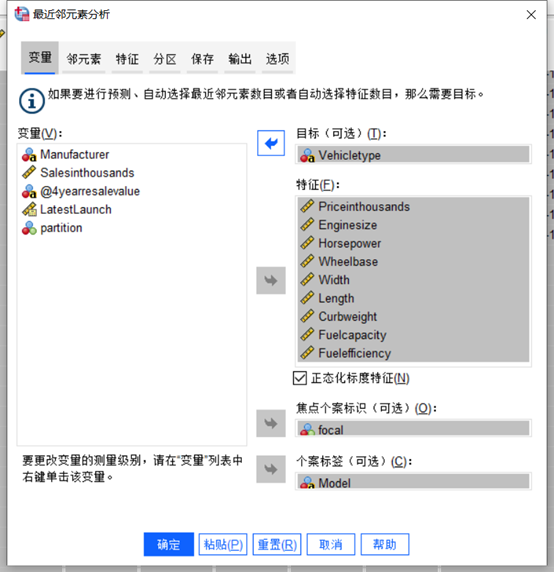
图5最近邻元素分析 点击最近邻元素分析顶部“邻元素”,将k值设置为3,并且勾选计算距离时按重要性对特征进行加权。
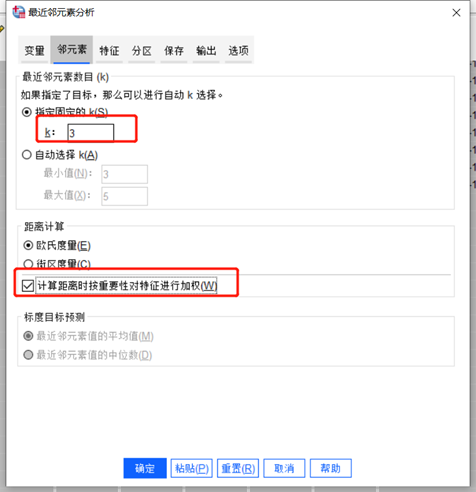
图6邻元素 点击最近邻元素分析顶部“分区”,训练和坚持分区选择使用变量来分配个案,并且将partition加载到分区变量文本框。
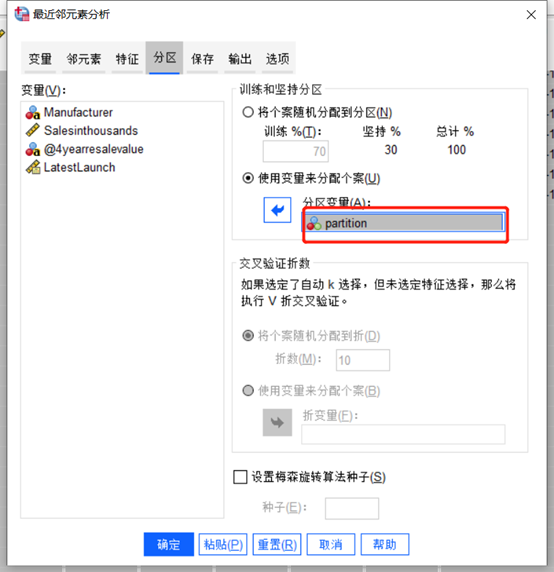
图7分区 三、结果分析
可以看到对于预估汽车类型结果,数据添加了一个预测值的变量,可以看到对新车的预测比较准确,并且生成了一个预估变量空间图型。
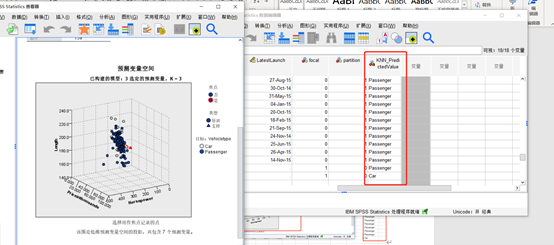
图8预估结果 四、小结
以上是利用SPSS最近邻元素模型对汽车行业数据进行分析,相信通过从数据准备和预处理,再到利用最近邻元素模型分析,最后到结果分析,你已经对该模型有一定了解,并且能够简单使用到各个领域。
作者:独行侠
展开阅读全文
︾
标签:IBM SPSS Statistics,spss,IBM SPSS
读者也访问过这里:热门文章SPSS数据分析显著性差异分析步骤 SPSS显著性差异分析结果怎么看数据的显著性差异分析主要有三种方法,分别是卡方检验、T检验和方差分析。这三种方法都有具体的数据要求:卡方检验是对多个类别的数据进行分析,T检验是对两组数据进行分析,方差分析是对多组数据进行检验。下面,小编具体说明一下SPSS数据分析显著性差异分析步骤,SPSS显著性差异分析结果怎么看。2022-01-07实践SPSS单因素方差分析之检验结果解读在《实践SPSS单因素方差分析之变量与检验方法设置》一文中,我们已经详细地演示了IBM SPSS Statistics单因素方差分析方法的变量选择以及相关的选项、对比设置。2021-01-11spss如何做显著性分析 spss显著性差异分析怎么标abc在统计分析中,显著性分析是分析相关因素之间是否存在显著影响关系的关键性指标,通过它可以说明分析结论是否由抽样误差引起还是实际相关的,可论证分析结果的准确性。下面大家一起来看看用spss如何做显著性分析,spss显著性差异分析怎么标abc。2022-03-14SPSS回归分析中的f值是什么 SPSS回归分析F值在什么范围合适回归分析中以R表示相关性程度的高低,以F评价回归分析是否有统计学的意义,使用IBM SPSS Statistics进行回归分析,可以非常快速的完成R,F的计算,并且给出回归曲线方程,那么,SPSS回归分析中f值是什么?SPSS回归分析F值在什么范围合适,本文结合实例向大家作简单的说明。2022-07-22SPSS多元logistic回归分析的使用技巧回归分析是数据处理中较为常用的一类方法,它可以找出数据变量之间的未知关系,得到较为符合变量关系的数学表达式,以帮助用户完成数据分析。2021-04-26SPSS相关性分析结果怎么看相关性分析是对变量或个案之间相关度的测量,在SPSS中可以选择三种方法来进行相关性分析:双变量、偏相关和距离。2021-04-23最新文章SPSS怎么合并变量为一个因子 SPSS因变量和因子怎么判断我们在使用SPSS进行问卷数据分析的过程中,多个题项往往共同测量同一个潜在维度,直接使用单个题项分析会导致结果零散,将这些相关变量合并为一个因子,能精准提炼数据的核心特征。接下来我将为大家介绍:SPSS怎么合并变量为一个因子,SPSS因变量和因子怎么判断的相关内容。2026-07-02SPSS怎么给数据分等级 SPSS怎么给数据加单位在处理数据的时候,我们可能会想给部分范围数据设置等级,比如分数大于90分的,设置为优秀;分数处于75到90之间的,设置为良好等。在SPSS软件里,我们可以用重新编码的方式,给数据分不同的等级,让其含义更丰富。接下来,本文会给大家介绍SPSS怎么给数据分等级,SPSS怎么给数据加单位的相关内容。2026-07-02SPSS怎么进行简单随机抽样 SPSS怎么进行信效度分析我们在进行问卷调研后,往往需要进行实证的数据分析。在这个过程里,简单随机抽样能够从全量数据中抽取代表性样本,是一种能降低数据分析工作量的核心方法,同时也可以保障样本的随机性与代表性。另外,信度检验验证数据的可靠性,效度分析检验问卷的结构合理性,二者是开展后续统计分析的重要前提。接下来我将为大家介绍:SPSS 怎么进行简单随机抽样,SPSS 怎么进行信效度分析的相关内容。2026-07-02SPSS做频数分布表如何分组 SPSS的频数分布表如何分析数据分析时,连续型变量的原始取值通常较为分散,直接统计频数的话,很难清晰呈现数据的整体分布规律。如果能够分组制作频数分布表,就能将零散的数据整合为有序的组别,直观展现不同区间的样本分布情况。接下来我将为大家介绍:SPSS做频数分布表如何分组,SPSS的频数分布表如何分析的相关内容。2026-07-02SPSS中的f值怎么算 SPSS中的f值显著性数值范围是多少在方差分析、回归分析等统计的方法中,f值多用于判断多组间均值差异是否显著、回归模型是否具有统计学意义。使用SPSS,无需手动计算复杂的f值公式,只需通过对应模块完成变量设置。接下来我将为大家介绍:SPSS中的f值怎么算,SPSS中的f值显著性数值范围是多少的相关内容。2026-07-02SPSS如何将数据转换成二分类 SPSS如何将数据转换成文本原始数据类型往往无法直接满足全部分析与展示需求,所以在数据分析的过程中,我们需要将连续变量或多分类变量转换成二分类变量。而将数值编码转换成文本标签,能让数据结果更直观易懂。接下来我将为大家介绍:SPSS如何将数据转换成二分类,SPSS如何将数据转换成文本的相关内容。2026-07-02读者也喜欢这些内容:
-
SPSS显著性小于0.001的意义 SPSS显著性大于0.05怎么办
在使用SPSS软件进行数据分析工作的过程中,得到的显著性水平分析结果具有极为重要的作用。它能够帮助我们衡量变量之间是否存在真实的关联,或者不同组别数据之间是否存在实质性的差异。今天我们就一起来探讨关于SPSS显著性小于0.001的意义,SPSS显著性大于0.05怎么办的问题。...
阅读全文 >
-
SPSS趋势分析怎么做 SPSS趋势分析时间序列怎么做
当我们想要对一系列有关时间变化的数据进行纵向的分析,推荐使用SPSS趋势分析的方法,这种方法可以应用于多类场景的数据分析,例如旅游景点的淡旺季客流量、农产品的四季变化产量等。本文以SPSS趋势分析怎么做,SPSS趋势分析时间序列怎么做这两个问题为例,给大家介绍一下SPSS趋势分析的相关知识。...
阅读全文 >
-
SPSS数据筛选好用吗 SPSS数据筛选怎么进行
在数据分析领域,如果收集的数据是为了按照一定标准或者类别来进行区分,我们可以尝试去运用SPSS的数据筛选功能,例如进行海量问卷调查的年龄段分层、地区划定、性别划分等等。本文以SPSS数据筛选好用吗,SPSS数据筛选怎么进行这两个问题为例,带大家了解一下SPSS数据筛选的知识。...
阅读全文 >
-

SPSS数据视图都是问号怎么办 SPSS数据视图怎么输入文字
SPSS数据统计分析软件的应用领域很广泛,像是教育学、经济学、社会学、医疗等领域都有涉及,也是因为应用的领域广,所以使用SPSS的统计人员也比较多。不过在使用SPSS的时候,也会遇到一些问题,下面给大家介绍SPSS数据视图都是问号怎么办,SPSS数据视图怎么输入文字的相关内容。...
阅读全文 >
-





