




仅剩:

发布时间:2021-06-01 11: 33: 16
“分箱法”相信学过统计学的小伙伴们都不会陌生,它的主要作用就在于对噪音数据进行剔除,同时将连续型数据进行离散处理。在模型分析开始前,我们经常需要使用到分箱法来处理和清洗数据。
作为一款功能全面、专业性强的统计分析软件,IBM SPSS Statistic同样具备分箱功能,下面我们一起来通过一篇教程了解一下。
图1是我们准备要分箱的数据,我们将对年龄列进行分箱,按照每10岁为一个标准进行分箱。
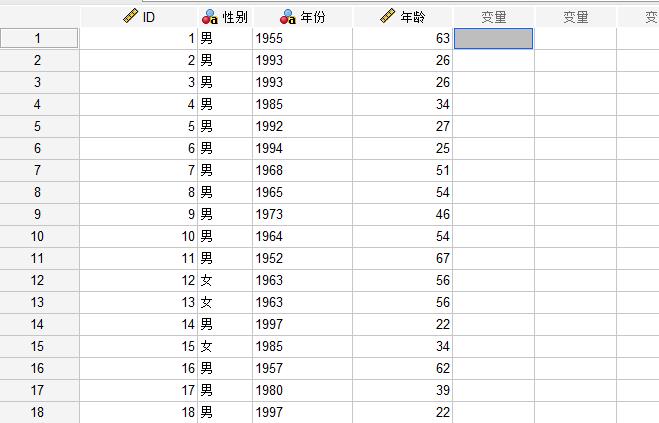
点击“转换”中的“可视分箱”,进入分箱设置界面。
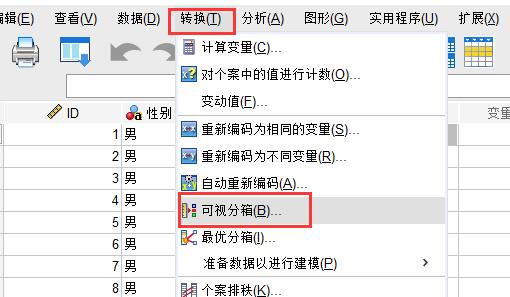
将“年龄”拉入到“要分箱的变量”中,然后点击“继续”。
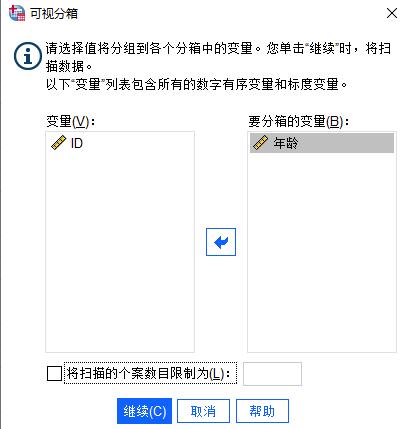
在图4所示界面,我们可以看到要扫描的个案数共34个,其中最大的变量值为67,最小为22,也就是说要分箱的数据年龄段在22到67岁之间。
我们在“分箱化变量”中,填入“年龄段”,作为一个之后新生成的变量,随后点击“生成分割点”按钮。
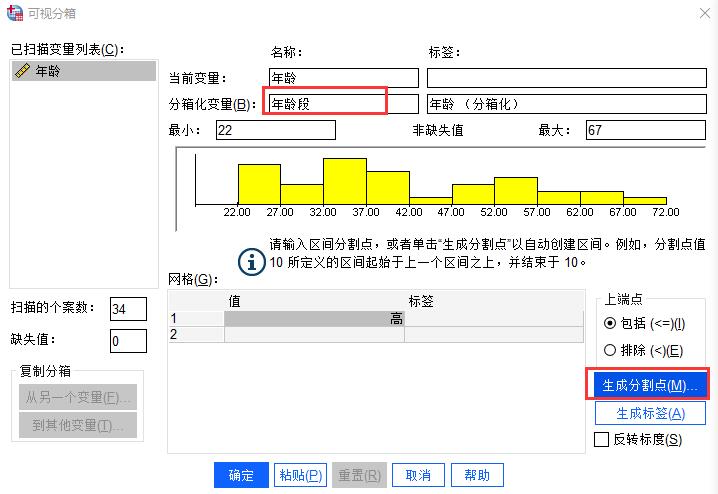
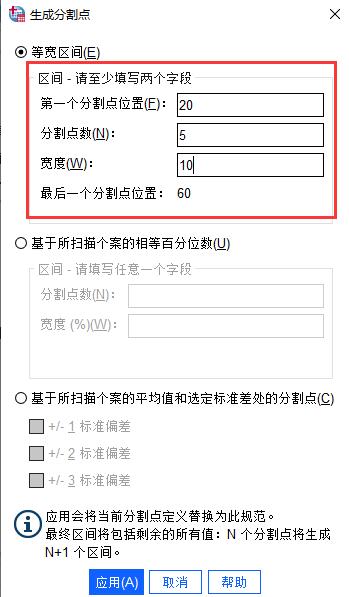
按照我们的分箱目的,我们要每隔10岁分组一次,最小的年龄为22岁,则我们需要在第一个分割点位置填写“20”,然后在宽度填写“10”,此时点击键盘Tap键,SPSS会自动生成分割点数的值为“5”,如图5所示。
这样子SPSS会自动帮我们将20到30、30到40、40到50、50到60、60到70的年龄段进行分组,一共5组。
点击“应用”按钮后,回到“可视分箱”界面中,我们可以在图6红框位置看到后续的分箱值,标签栏默认是空值,我们可以进行自定义填写,如设置20的分箱标签为2。

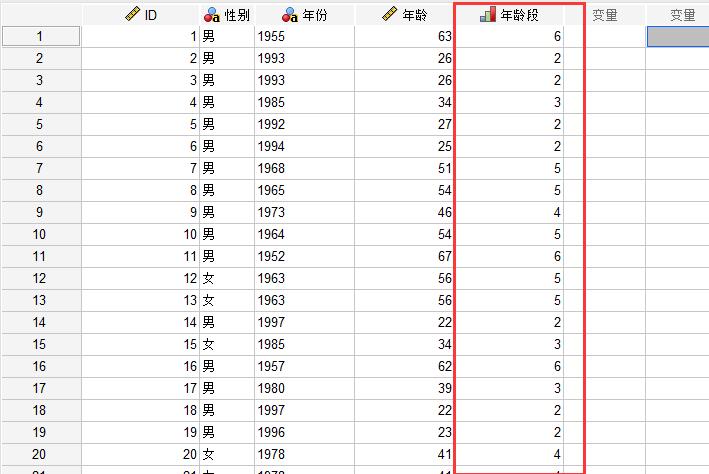
最后点击“确定”按钮,开始进行数据分箱,分箱后的新数据结果如图7所示,生成了新的“年龄段”列,数据也非常正确地进行了分箱,如年龄为27的那行数据,被正确地设置到了标签为2的分箱中。
以上就是使用IBM SPSS Statistic对演示数据中的年龄指标,按照每隔10岁的标准,进行分箱的全部教程,上述演示的是等距分箱,小伙伴也可以自己动手在IBM SPSS Statistic中尝试一下不等距分箱哦。
作者:包纸
展开阅读全文
︾
读者也喜欢这些内容:

SPSS怎么进行数据筛选 SPSS怎么进行数据挖掘
我们在进行数据分析的时候,都会遇到数据筛选的问题。需要从海量数据中精准提取有效的数据,减少分析误差。数据挖掘,则是从清洗后的数据中找到隐藏的规律。接下来,我将选择一个电商数据分析的实际场景,来为大家介绍:SPSS怎么进行数据筛选,SPSS怎么进行数据挖掘的相关内容。...
阅读全文 >
SPSS怎么做回归分析 SPSS回归结果不显著怎么办
在数据分析的领域中,回归分析相当于为数据样本开启了一道未来大门,它可以帮助我们评估和判断数据样本未来的走势和发展方向,同时帮助我们判断不同数据变量之间的关系。如果遇到回归结果不显著的情况,我们也需要对这部分数据进行处理,避免出现无效的分析情况。下面以SPSS为例,给大家介绍SPSS怎么做回归分析, SPSS回归结果不显著怎么办的具体内容。...
阅读全文 >
SPSS数据合并怎么实现 SPSS数据合并个案追加流程
当我们进行数据分析时,不会只分析一组数据源,如果需要将多组数据源进行合并,就必须使用到SPSS中的数据合并工具。今天我就以SPSS数据合并怎么实现,SPSS数据合并个案追加流程这两个问题为例,来向大家讲解一下SPSS中数据合并的相关知识。...
阅读全文 >

SPSS Tukey检验是什么 SPSS Tukey检验怎么做
在数据分析领域,Tukey事后检验经常作为SPSS方差分析的重要结果,也就是被用来分析多组变量在某方面的水平均值是否具有显著差异,例如不同类型药物的治疗效果、不同款式产品的销售量、不同年龄段儿童的智力发育水平等等。本文以SPSS Tukey检验是什么,SPSS Tukey检验怎么做这两个问题为例,简单介绍一下Tukey检验的相关知识。...
阅读全文 >
