


- 首页
- 产品
- 下载
- 学生专享NEW
-
帮助中心
SPSS重新编码之自动编码功能
发布时间:2020-12-08 13: 48: 56
在进行数据录入时,以数值型数据录入会更有利于后续的统计计算。但如果在录入时,采用了字符串值的录入方式,该如何将其转化为可计算的数值呢?在这种情况下,可以使用IBM SPSS Statistics的重新编码功能,将字符串重新编码为数值。
IBM SPSS Statistics自动重新编码功能,可自动为变量创建编码,同时保留变量定义的标签和值标签,对未定义值标签的任何值,将使用原值作为重新编码后的值标签。
一、打开数据文件
首先,打开一组数据,该数据包含了性别、客单价、地区等变量。我们需要对地区与来源进行重新编码,方便后期的数据处理。
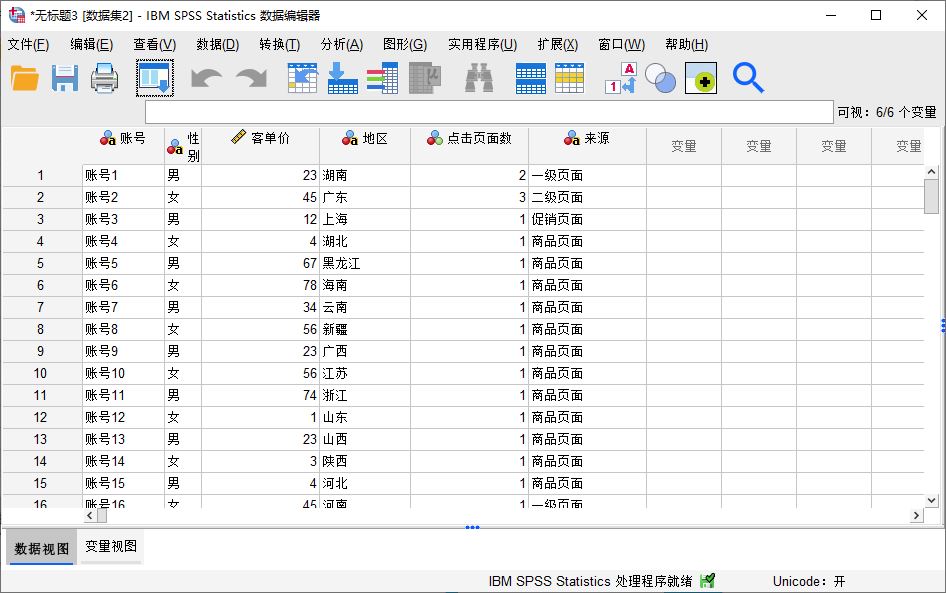
图1:示例数据 二、使用自动编码功能
如图2所示,打开IBM SPSS Statistics转换菜单中的“自动重新编码”功能。
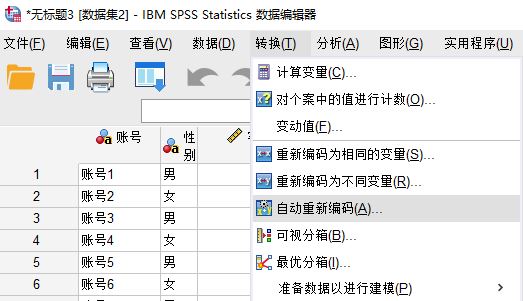
图2:自动编码功能如图3所示,设置面板中包含变量新名称、编码起点、编码模板等选项。接下来,我们使用示例的数据逐步操作。
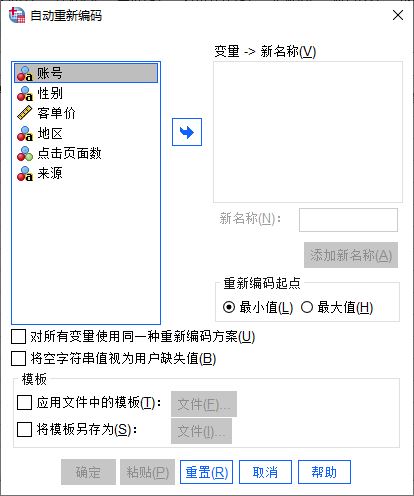
图3:自动编码设置面板 1、选择变量
首先,如图4所示,将需要重新编码的地区变量从左侧添加到右侧方框中。
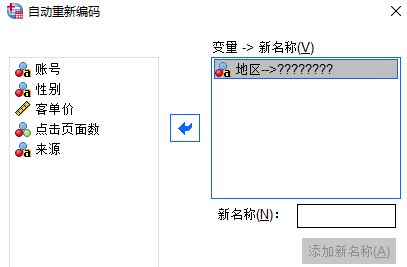
图4:选择变量 2、编辑新名称
然后,如图5所示,选中已添加的地区变量,在新名词处输入重新编码后的变量名称:地区编码,并将其添加为新名称。
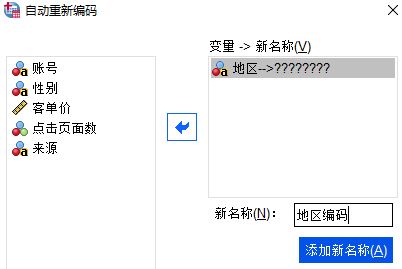
图5:添加新名词 3、设置编码方式
完成变量的设置后,再进一步设置如下选项:
1. 编码起点,设置从最小值或最大值处开始编码
2. 对所有变量使用同一种重新编码方案,即添加的所有重新编码变量都采用同一套编码方案,下文我们会使用实例解释
3. 将空值设为用户缺失值
4. 应用模板或另存为模板(作为码表方便后续使用)
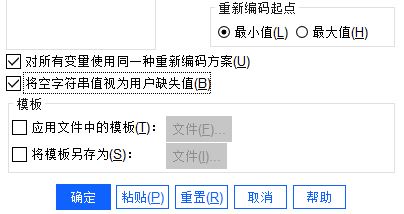
图6:设置编码方式 如果我们添加了两个变量为重新编码的变量,比如地区和来源,同时还勾选了“对所有变量使用同一种重新编码方案”选项的话,就会出现如图7所示的结果,地区与来源的变量会混合起来重新编码。
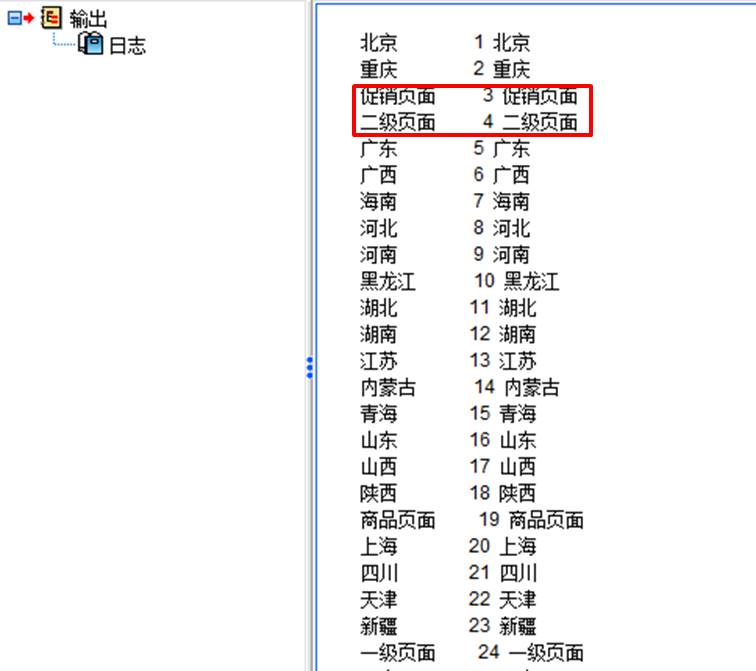
图7:对所有变量执行同一编码方案 但实际上,我们应该要将两个变量的编码值分开,因此,本例不能勾选“对所有变量使用同一种重新编码方案”选项。
取消选项勾选后,再次运行,如图8所示,可以看到,地区与来源的码表已经分开了。
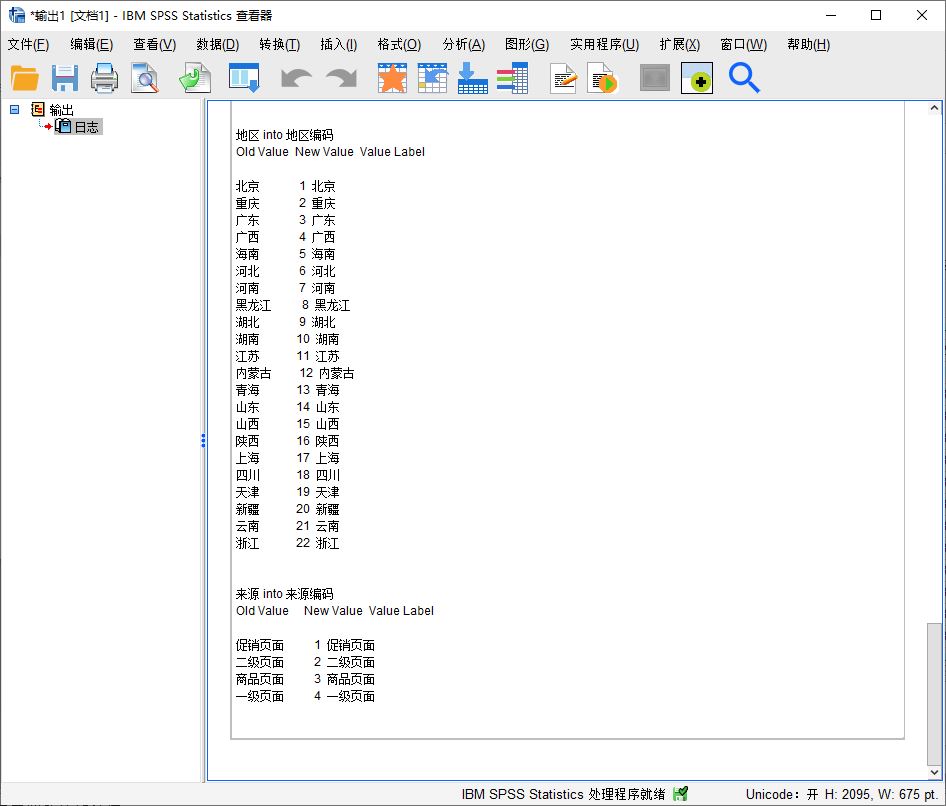
图8:对所有变量执行不同编码方案 返回数据集,如图9所示,可以看到,数据中出现了两个新的变量,分别是“地区编码”与“来源编码”。
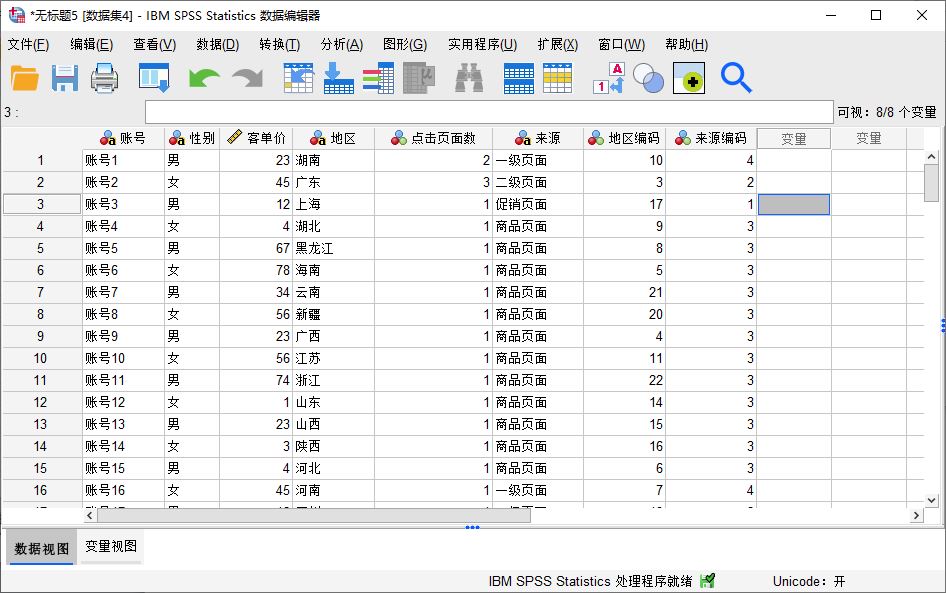
图9:完成重新编码 以上就是IBM SPSS Statistics自动重新编码功能的应用介绍。如果变量中包含较多不同字符串值的话,该功能就能很好地减轻编码的负担,并能自动形成码表供后续使用。
作者:泽洋
展开阅读全文
︾
标签:IBM SPSS Statistics,重新编码功能
读者也访问过这里:热门文章SPSS数据分析显著性差异分析步骤 SPSS显著性差异分析结果怎么看数据的显著性差异分析主要有三种方法,分别是卡方检验、T检验和方差分析。这三种方法都有具体的数据要求:卡方检验是对多个类别的数据进行分析,T检验是对两组数据进行分析,方差分析是对多组数据进行检验。下面,小编具体说明一下SPSS数据分析显著性差异分析步骤,SPSS显著性差异分析结果怎么看。2022-01-07实践SPSS单因素方差分析之检验结果解读在《实践SPSS单因素方差分析之变量与检验方法设置》一文中,我们已经详细地演示了IBM SPSS Statistics单因素方差分析方法的变量选择以及相关的选项、对比设置。2021-01-11spss如何做显著性分析 spss显著性差异分析怎么标abc在统计分析中,显著性分析是分析相关因素之间是否存在显著影响关系的关键性指标,通过它可以说明分析结论是否由抽样误差引起还是实际相关的,可论证分析结果的准确性。下面大家一起来看看用spss如何做显著性分析,spss显著性差异分析怎么标abc。2022-03-14SPSS回归分析中的f值是什么 SPSS回归分析F值在什么范围合适回归分析中以R表示相关性程度的高低,以F评价回归分析是否有统计学的意义,使用IBM SPSS Statistics进行回归分析,可以非常快速的完成R,F的计算,并且给出回归曲线方程,那么,SPSS回归分析中f值是什么?SPSS回归分析F值在什么范围合适,本文结合实例向大家作简单的说明。2022-07-22SPSS多元logistic回归分析的使用技巧回归分析是数据处理中较为常用的一类方法,它可以找出数据变量之间的未知关系,得到较为符合变量关系的数学表达式,以帮助用户完成数据分析。2021-04-26SPSS相关性分析结果怎么看相关性分析是对变量或个案之间相关度的测量,在SPSS中可以选择三种方法来进行相关性分析:双变量、偏相关和距离。2021-04-23最新文章SPSS中如何将字符串变量转换为数值 SPSS字符串数据怎么处理我们在用问卷收集数据的时候,难免要设置一些开放题。由于开放题没有固定的答案,所以比较难事先做好编码,一般都是将答案收集好后再整理。因此,将数据导入SPSS后,可能会有一些字符串的变量,需要进行二次处理。接下来我们会介绍SPSS中如何将字符串变量转换为数值,SPSS字符串数据怎么处理的相关内容。2026-07-02SPSS的检验方法有哪些 SPSS如何做z检验在做研究分析时,我们可能要做各种数据的检验运算,比如看数据是否满足正态性、方差齐性,看各种组别的数值是否有统计学差异等。SPSS提供了很多实用的分析方法、参考图表等功能,可以快速而简单地做好数据的检验,接下来我们会介绍SPSS的检验方法有哪些,SPSS如何做z检验的相关内容。2026-07-02SPSS中的F值是什么 SPSS中P值和F值如何计算在SPSS得出的运算结果中,会出现一些F值、P值等结果,对于初学者来说,这些统计量可能会有点陌生,但它们在数据研究中,有着重要的意义。其实不仅是SPSS,其他同类型的统计软件也会出现这些统计量。接下来我们会介绍SPSS中的F值是什么,SPSS中P值和F值如何计算的相关内容,让大家可以更熟悉这方面的内容。2026-07-02SPSS验证假设需要什么分析 SPSS假设检验模型一模型二模型三是什么意思假设验证,是很多数据研究里面会用到分析方法,可以用来看数据是否有差异、是否满足正态性、方差是不是相等等。验证假设用到的分析方法,会因为不同的数据类型、研究方向等而有所不同,它们会影响到我们要选择的方法,比如t检验、ANOVA等。接下来我们会介绍SPSS验证假设需要什么分析,SPSS假设检验模型一模型二模型三是什么意思的相关内容。2026-07-02SPSS如何做m±sd分析 SPSS如何做验证性因素分析SPSS有很多好用的数据统计分析功能,像日常用到的均值、标准差等统计量,SPSS可以轻松用“描述”等方法快速计算出来。对于比较专业、复杂的分析方法,SPSS也有提供到相关的功能,比如降维、聚类、因子分析等,都可以在SPSS里面使用到。接下来我们会介绍SPSS如何做m±sd分析,SPSS如何做验证性因素分析的相关内容。2026-07-02SPSS数据分析如何确定用哪种方法分析 SPSS怎样验证数据分析结果的准确性面对不同类型的数据,我们要选择不同的分析方法。对于初学者来说,如果没有系统学习过统计相关的知识,会比较难入门。不过,在SPSS软件里面,我们可以根据数据的特点、研究目的等内容,简单而快速地找到合适的功能。接下来我们会介绍SPSS数据分析如何确定用哪种方法分析,SPSS怎样验证数据分析结果的准确性的相关内容。2026-07-02读者也喜欢这些内容:
-
SPSS偏度和峰度的分析步骤 SPSS偏度和峰度的分析结果解读
偏度和峰度是我们在进行数据分析的过程中,判断数据是否符合正态分布的重要标准之一,通过这两个数值可以很清晰地看出数据的整体走势和集中状态。因此这两项数值也经常被用于市场学分析、股市分析中,能够帮忙用户去发现某些潜在的规律。今天我就以SPSS偏度和峰度的分析步骤,SPSS偏度和峰度的分析结果解读这两个问题为例,来向大家讲解一下关于偏度和峰度的相关知识。...
阅读全文 >
-
SPSS显著性小于0.001的意义 SPSS显著性大于0.05怎么办
在使用SPSS软件进行数据分析工作的过程中,得到的显著性水平分析结果具有极为重要的作用。它能够帮助我们衡量变量之间是否存在真实的关联,或者不同组别数据之间是否存在实质性的差异。今天我们就一起来探讨关于SPSS显著性小于0.001的意义,SPSS显著性大于0.05怎么办的问题。...
阅读全文 >
-
SPSS如何计算z-score SPSS做z-score标准化
作为综合性的数字分析工具,SPSS不仅可以实现数值计算和比对的功能,还能够帮助研究者检验和提取出异常数值,也就是SPSS的检验功能,例如z-score的方法可以将所有数据转化为标准化数据,再依据z值标准筛选出异常数值。本文以SPSS如何计算z-score,SPSS做z-score标准化这两个问题为例,简单介绍一下SPSS的z-score方法如何操作。...
阅读全文 >
-
SPSS数据排序如何设置 SPSS数据排序功能最大值和最小值
数据分析作为SPSS的重要主题,包含了数量计算、数据预测、数值对比等方面,在汇总统计各类数值的基础上,我们常常会需要对数据进行排序比较,而排序就是根据数值的大小来进行排列。本文以SPSS数据排序如何设置,SPSS数据排序功能最大值和最小值这两个问题为例,带大家了解一下SPSS数据排序的知识。...
阅读全文 >
-





