




仅剩:

发布时间:2023-03-20 11: 40: 14
品牌型号:联想
系统:win7 64位旗舰版
软件版本:IBM SPSS Statistics 29
有时候导入SPSS中的数据资料,会因为人为原因或者设备原因出现缺失数据,遇到这种情况如果是一些调研数据资料,想再重新进行调研收集数据资料,显然是不可能的,所以需要对缺失的数据进行处理。本文就和大家详细介绍一下,SPSS缺失值怎么输入,以及SPSS缺失值怎么自动填充。
一、SPSS缺失值怎么输入
在对数据资料进行统计分析时,如果存在的缺失值不多,对数据分析结果影响不大,这种情况下可以对缺失值进行定义输入处理,下面就和大家详细介绍一下。
1.启动SPSS,点击“变量视图”按钮进入变量视图页面,找到变量缺失值所在单元格,点击单元格中的方格按钮。
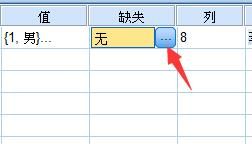
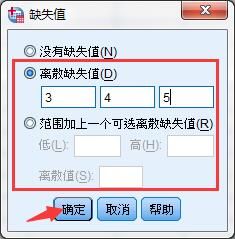
2.在“缺失值”窗口有两种缺失值输入方案,一种是离散缺失值方案,这种缺失值输入比较适用于缺失值比较分散,而且缺失值数量比较不多的情况;另一种是范围加上一个可选离散缺失值方案,这种缺失值输入适用于缺失值比较多,而且在一定的数值范围内,根据具体情况来选择输入方案,点击“确定”按钮即可。
二、SPSS缺失值怎么自动填充
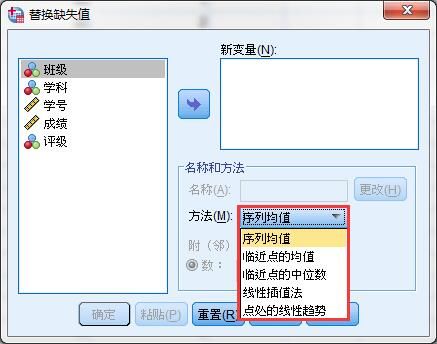
在SPSS中有很多缺失值自动填充方法,包括序列均值、临近点的均值、临近点的中位数、线性插值法以及点处的线性趋势,下面就给大家介绍一下这几种缺失值自动填充方法。
1.序列均值
序列均值填充方法其实很简单,就是将计算得出的缺失值变量序列的平均值数值,作为缺失值进行填充。
2.临近点的均值
临近点的均值填充方法是对缺失值上下有效的数据进行平均值计算,将得到的平均值作为缺失值进行填充。
3.临近点的中位数
临近点的中位数填充方法是将缺失值上下有效数据范围内的中位数作为缺失值进行填充。
4.线性插值法
线性插值法填充方法是使用连接两个已知量的直线来确定这个两个已知量之间一个未知量值的方法,这个未知量值就可以作为缺失值进行填充。
5.点处的线性趋势
点处的线性趋势填充方法是将数据资料中的除缺失值变量作为自变量,缺失值变量作为因变量,进行建模预测缺失值,最终将预测出来的数值作为缺失值进行填充。
下面将分别使用序列均值、临近点的均值以及点处的线性趋势方法,给大家演示一下缺失值自动填充操作步骤。
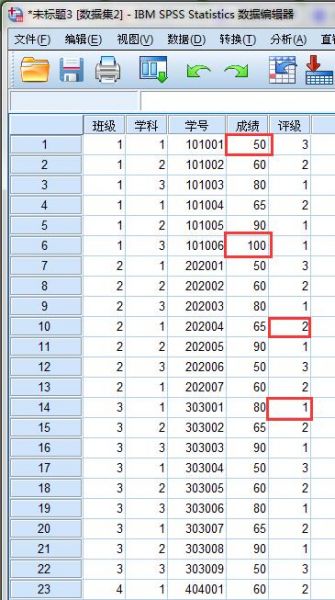
1.如下图所示是一个成绩统计表格,现在分别在“成绩”和“评级”变量中删除两个数值,造成缺失值现象,删除的数值分别是100、50、2、1。
2.序列均值填充方法:在菜单栏中点击“替换”-“替换缺失值”,在“替换缺失值”窗口将“成绩”和“评级”变量通过箭头按钮移动到“新变量”框内,方法选择“序列均值”,点击确定按钮。
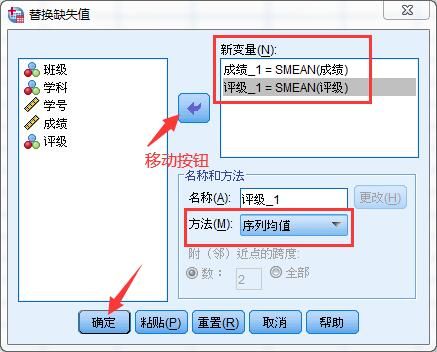
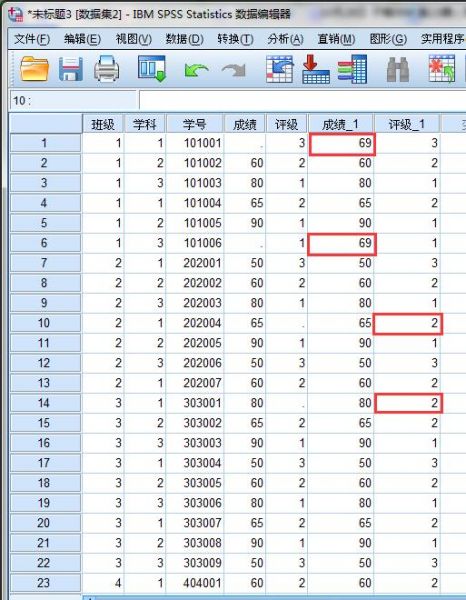
完成后,会在数据视图表格中生成“成绩-1”和“评级-1”新变量,其中缺失的数据已经自动填充完成。
3.临近点的均值填充方法:在“替换缺失值”窗口将“成绩”和“评级”变量通过箭头按钮移动到“新变量”框内,方法选择“临近点的均值”,附临近点的跨度选择“全部”,点击确定按钮。
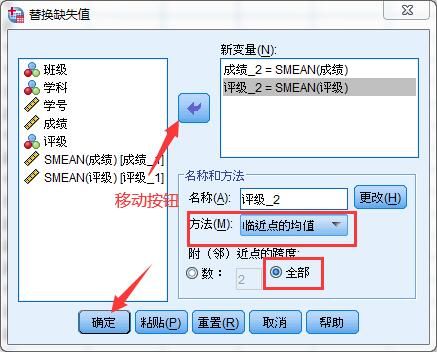
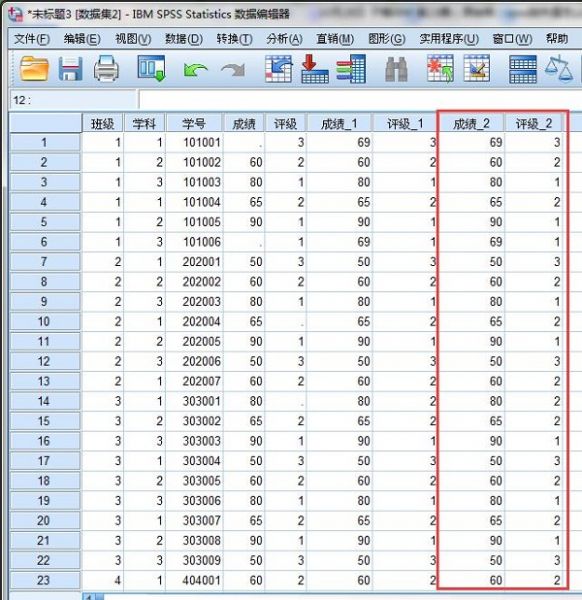
完成后,在数据视图表格中会生成“成绩-2”和“评级-2”新变量,其中缺失的数据已经自动填充完成。
4.点处的线性趋势填充方法:在“替换缺失值”窗口将“成绩”和“评级”变量通过箭头按钮移动到“新变量”框内,方法选择“点处的线性趋势”,点击确定按钮。
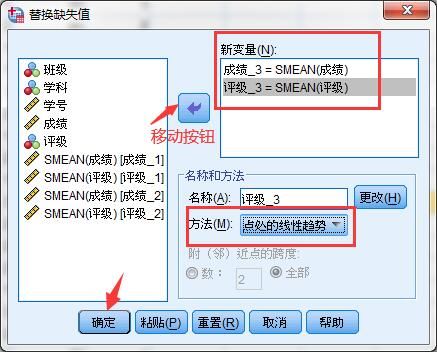
完成后,在数据视图表格中会生成“成绩-2”和“评级-2”新变量,其中缺失的数据已经自动填充完成。
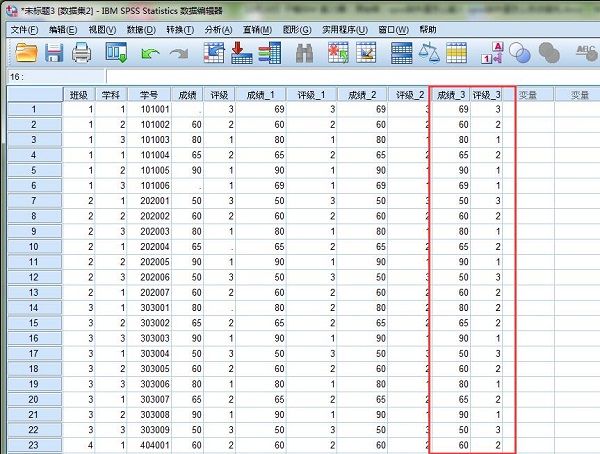
对比三种缺失值填充方法可以看到,自动填充的数据没有什么差别。

总结:以上就是SPSS缺失值怎么输入,SPSS缺失值怎么自动填充的全部内容。本文不仅给大家介绍了SPSS缺失值输入方法,还给大家演示了三种SPSS缺失值自动填充的操作过程,希望通过上文所述能够帮助到有需要的小伙伴。
作者:子楠
展开阅读全文
︾
读者也喜欢这些内容:
SPSS随机分组的优缺点 SPSS随机分组的注意事项
什么是随机分组呢?我们可以将它理解为公平的“抽签”,具体而言就是保证每个受试者被分到任何一组的概率已知且相等的分组方法。随机分组的方法经常被应用于实验研究过程中,尤其是临床试验中,在临床试验中,受试者将会完全凭借“偶然性”机会被分配到不同的分组——如实验组和对照组,而不根据研究对象的年龄、病情或其他任何因素。本文中我们就介绍一下关于SPSS随机分组的优缺点,SPSS随机分组的注意事项的相关内容。...
阅读全文 >
SPSS随机抽取30%的样本 SPSS随机抽取30%的研究对象
在社会统计学或加工生产领域,我们为了了解某批次数据的整体状态,常常会使用随机取样的方式进行分析,以小批次数据的分析结果为蓝本,来判断整组数据的合理性。今天我就以SPSS随机抽取30%的样本,SPSS随机抽取30%的研究对象这两个问题为例,来向大家演示一下在SPSS中执行随机抽取的详细步骤。...
阅读全文 >
SPSS怎么做回归分析 SPSS回归结果不显著怎么办
在数据分析的领域中,回归分析相当于为数据样本开启了一道未来大门,它可以帮助我们评估和判断数据样本未来的走势和发展方向,同时帮助我们判断不同数据变量之间的关系。如果遇到回归结果不显著的情况,我们也需要对这部分数据进行处理,避免出现无效的分析情况。下面以SPSS为例,给大家介绍SPSS怎么做回归分析, SPSS回归结果不显著怎么办的具体内容。...
阅读全文 >
SPSS如何随机抽取样本数据 SPSS如何随机选取70%的数据
我们在进行数据分析的工作时,有时为了减少人为误差,避免样本集中在某些特定群体上,所以需要随机抽取样本数据。SPSS既能帮助我们处理不同的数据样本,还可以指定选取相关的数据内容,做到更加精准的数据匹配。接下来给大家介绍SPSS如何随机抽取样本数据,SPSS如何随机选取70%的数据的具体内容。...
阅读全文 >
