


- 首页
- 产品
- 下载
- 学生专享NEW
-
帮助中心
如何利用加权Kappa对有序分类变量进行一致性检验
发布时间:2021-06-15 15: 09: 59
在上节《在SPSS中安装加权kappa计算插件》中,我们已经成功地在SPSS软件中安装了加权Kappa插件,本文将带大家继续深入了解这一插件的使用场景和使用方式。
一、生成交叉表
我们下面要进行使用的数据如图1所示,该数据共50条记录,表示了两名医生对疾病严重程度的判断分数,分数范围从1到5,其中1表示轻度,5表示严重,两名医生之间的判断结果互不影响、互相独立。
图1:演示数据展示
对于这类有序分类的变量一致性检验,我们就需要采用到加权Kappa系数进行计算分析。第一步:点击【分析】中的【描述统计】项,在右侧展开栏中选择【交叉表】。
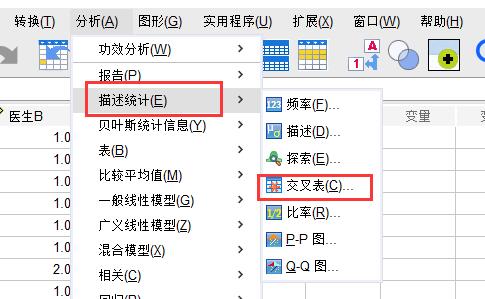
图2:交叉表
第二步:在交叉表中,我们在行中填入医生A,在列中填入医生B,然后点击“确定”,让SPSS为我们生成这2组数据的交叉表。
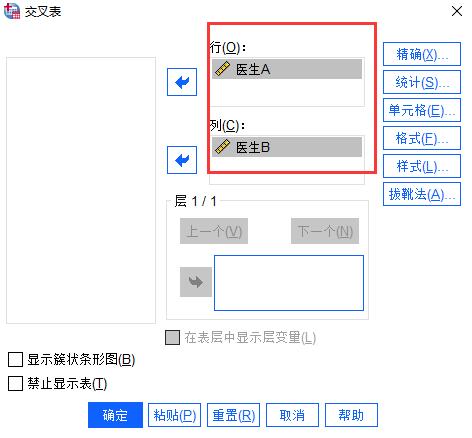
图3:交叉表填入行和列
生成的交叉表如图4所示,我们直接看图4红框标出来的位置,即对角线上的数据,这表示两位医生对于疾病严重程度的诊断还是比较一致的;当然,诊断结果也不是完全一致,因为在非对角线位置,还是有一些不为0的地方。
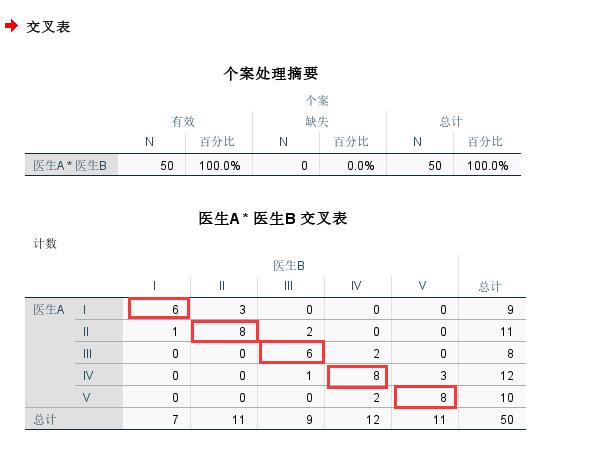
图4:交叉表结果分析
二、加权Kappa
接下来我们使用加权Kappa系统来对数据一致性进行分析,点击【分析】--【刻度】--【加权Kappa】,如图5。
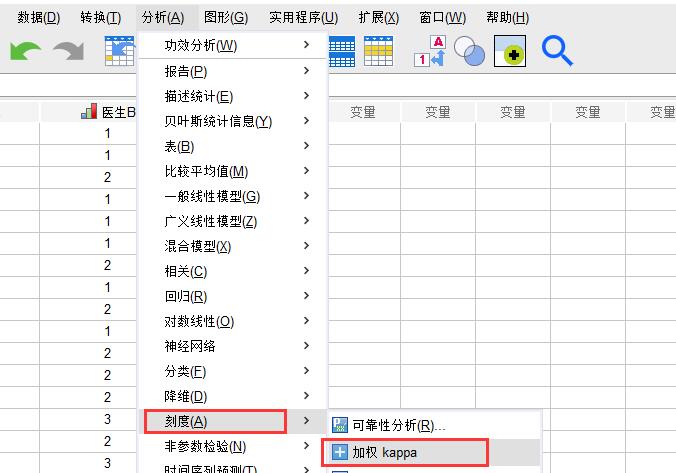
图5:加权Kappa
随后在评分1中填入医生A,在评分2中填入医生B,权重类型采用默认的线性类型即可,下方的CI覆盖水平默认为95%,意思就是获取加权Kappa系统的95%的置信区间,我们也可以按需调整为常用的99%置信区间或其他置信区间。
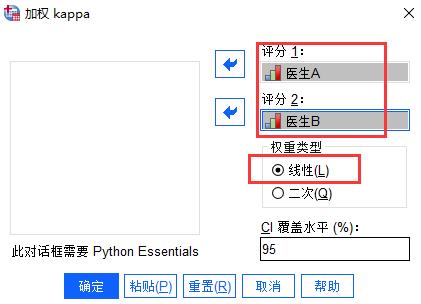
图6:加权Kappa设置
上述的权重类型,线性类型表示每个级别之间的差异是相等的,即1到2和2到3之间的差异是一致的;而二次类型,则表示1到2和2到3之间的差异是不同的,2到3之间的差异相比于1到2要更严重。因此,综上我们采用线性权重类型。
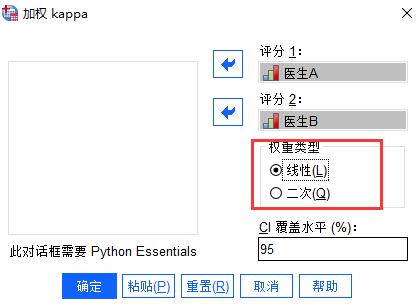
图7:权重类型
最终得出的加权Kappa结果如下图8,Kappa系数为0.822,我们认为,Kappa系数越接近1,则一致性就越强,因此本组数据两位医生之间的结果一致性是强一致性,也符合上述交叉表得到的结果。另外,从结果中我们还可以得出加权Kappa系数的95%置信区间为0.739到0.904。
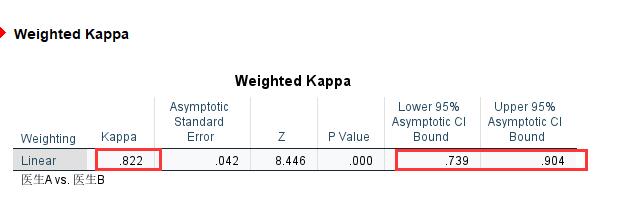
图8:结果展示
本文中采用了交叉表和加权Kappa两种不同的方法,探索两位医生对疾病严重的程度结果判断的一致性,最终都认为它们之间具有强一致性。这就是关于IBM SPSS Statistic软件使用加权Kappa插件进行一致性分析的全部教程,希望能给大家带来帮助。
作者署名:包纸
展开阅读全文
︾
标签:spss,Kappa
读者也访问过这里:热门文章SPSS数据分析显著性差异分析步骤 SPSS显著性差异分析结果怎么看数据的显著性差异分析主要有三种方法,分别是卡方检验、T检验和方差分析。这三种方法都有具体的数据要求:卡方检验是对多个类别的数据进行分析,T检验是对两组数据进行分析,方差分析是对多组数据进行检验。下面,小编具体说明一下SPSS数据分析显著性差异分析步骤,SPSS显著性差异分析结果怎么看。2022-01-07实践SPSS单因素方差分析之检验结果解读在《实践SPSS单因素方差分析之变量与检验方法设置》一文中,我们已经详细地演示了IBM SPSS Statistics单因素方差分析方法的变量选择以及相关的选项、对比设置。2021-01-11spss如何做显著性分析 spss显著性差异分析怎么标abc在统计分析中,显著性分析是分析相关因素之间是否存在显著影响关系的关键性指标,通过它可以说明分析结论是否由抽样误差引起还是实际相关的,可论证分析结果的准确性。下面大家一起来看看用spss如何做显著性分析,spss显著性差异分析怎么标abc。2022-03-14SPSS回归分析中的f值是什么 SPSS回归分析F值在什么范围合适回归分析中以R表示相关性程度的高低,以F评价回归分析是否有统计学的意义,使用IBM SPSS Statistics进行回归分析,可以非常快速的完成R,F的计算,并且给出回归曲线方程,那么,SPSS回归分析中f值是什么?SPSS回归分析F值在什么范围合适,本文结合实例向大家作简单的说明。2022-07-22SPSS多元logistic回归分析的使用技巧回归分析是数据处理中较为常用的一类方法,它可以找出数据变量之间的未知关系,得到较为符合变量关系的数学表达式,以帮助用户完成数据分析。2021-04-26SPSS相关性分析结果怎么看相关性分析是对变量或个案之间相关度的测量,在SPSS中可以选择三种方法来进行相关性分析:双变量、偏相关和距离。2021-04-23最新文章SPSS中如何将年龄分段筛选出来 SPSS如何将年龄从字符串改为数字在进行社会科学研究时,往往会需要进行调研。在调研之后,我们做调研数据处理时,可能会遇到格式不整齐的情况,例如变量并非单纯的数字,而是包含了“岁”等单位。这样的字符串格式的年龄不能直接用于数据分析,而是必须先转换成纯数字。接下来我将为大家介绍:SPSS 中如何将年龄分段筛选出来,SPSS如何将年龄从字符串改为数字的相关内容。2026-07-02SPSS中如何将字符串变量转换为数值 SPSS字符串数据怎么处理我们在用问卷收集数据的时候,难免要设置一些开放题。由于开放题没有固定的答案,所以比较难事先做好编码,一般都是将答案收集好后再整理。因此,将数据导入SPSS后,可能会有一些字符串的变量,需要进行二次处理。接下来我们会介绍SPSS中如何将字符串变量转换为数值,SPSS字符串数据怎么处理的相关内容。2026-07-02SPSS的检验方法有哪些 SPSS如何做z检验在做研究分析时,我们可能要做各种数据的检验运算,比如看数据是否满足正态性、方差齐性,看各种组别的数值是否有统计学差异等。SPSS提供了很多实用的分析方法、参考图表等功能,可以快速而简单地做好数据的检验,接下来我们会介绍SPSS的检验方法有哪些,SPSS如何做z检验的相关内容。2026-07-02SPSS中的F值是什么 SPSS中P值和F值如何计算在SPSS得出的运算结果中,会出现一些F值、P值等结果,对于初学者来说,这些统计量可能会有点陌生,但它们在数据研究中,有着重要的意义。其实不仅是SPSS,其他同类型的统计软件也会出现这些统计量。接下来我们会介绍SPSS中的F值是什么,SPSS中P值和F值如何计算的相关内容,让大家可以更熟悉这方面的内容。2026-07-02SPSS验证假设需要什么分析 SPSS假设检验模型一模型二模型三是什么意思假设验证,是很多数据研究里面会用到分析方法,可以用来看数据是否有差异、是否满足正态性、方差是不是相等等。验证假设用到的分析方法,会因为不同的数据类型、研究方向等而有所不同,它们会影响到我们要选择的方法,比如t检验、ANOVA等。接下来我们会介绍SPSS验证假设需要什么分析,SPSS假设检验模型一模型二模型三是什么意思的相关内容。2026-07-02SPSS如何做m±sd分析 SPSS如何做验证性因素分析SPSS有很多好用的数据统计分析功能,像日常用到的均值、标准差等统计量,SPSS可以轻松用“描述”等方法快速计算出来。对于比较专业、复杂的分析方法,SPSS也有提供到相关的功能,比如降维、聚类、因子分析等,都可以在SPSS里面使用到。接下来我们会介绍SPSS如何做m±sd分析,SPSS如何做验证性因素分析的相关内容。2026-07-02读者也喜欢这些内容:
-
SPSS 安装激活流程
...
阅读全文 >
-
SPSS软件购买大概花多少钱 SPSS软件版本有什么区别
市面上的数据分析软件有很多,如SPSS、Graphpad和Stata等等,这些软件帮助我们进行许多领域的数据分析,例如临床医学中的药品效果验证、农业中的农药防治病虫害效果和社会科学的人口数据调查等等。SPSS是其中应用十分广泛的一款软件,接下来我就介绍一下SPSS软件购买大概花多少钱,SPSS软件版本有什么区别。...
阅读全文 >
-
什么是SPSS精确检验 SPSS Fisher精确检验和Pearson卡方检验有什么区别
在数据分析中,分类变量的关联性检验是找到数据内在规律的重要方法。SPSS作为常用到的统计软件,针对不同的数据模型,提供了Pearson卡方检验与Fisher精确检验两种不同的检验方法。下面我们将为大家介绍什么是SPSS精确检验,以及SPSS Fisher精确检验和Pearson卡方检验有什么区别的相关内容。...
阅读全文 >
-
SPSS数据编码如何操作 SPSS数据编码数值替换方法
数据编码,从字面上解释就是将原始的数据转化为软件代码,使软件能够更好地进行数据分析工作,而使用SPSS就能实现不同类型的数据编码程序。接下来,我就以SPSS数据编码如何操作,SPSS数据编码数值替换方法这两个问题为例,来向大家讲解一下数据编码的相关知识。...
阅读全文 >
-




