


- 首页
- 产品
- 下载
- 学生专享NEW
-
帮助中心
通过SPSS独立样本T检验,分析两组个案的差异(下)
发布时间:2020-12-11 11: 09: 41
上一节,我们重点讲解了IBM SPSS Statistics独立样本T检验的检验原理、数据要求以及数据转换的方法。这部分的内容相当重要,建议先理解了上一节内容再学习本节的实例操作。
如图1所示,可以看到,独立样本T检验仅包含了检验变量,因此,需要使用个案组数据进行检验,而其分组变量是作为标识两组个案使用的。接下来,我们通过示例数据学习下操作。
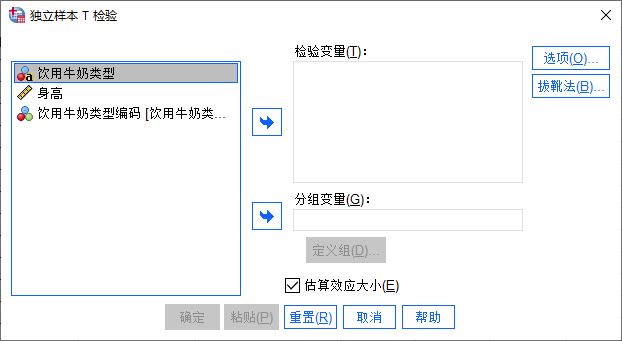
图1:独立样本T检验 一、选择变量
首先,了解下设置面板中的变量概念:
1. 检验变量,即检验均值是否存在显著性差异的变量数值。
2. 分组变量,即用于标识两组个案的变量。
本例中,我们需要检验的是饮用牛奶A组与饮用牛奶B组的平均身高数据是否有差异。因此,需要将身高变量添加为检验变量,将饮用牛奶类型编码添加为分组变量。
然后,单击定义组按钮。
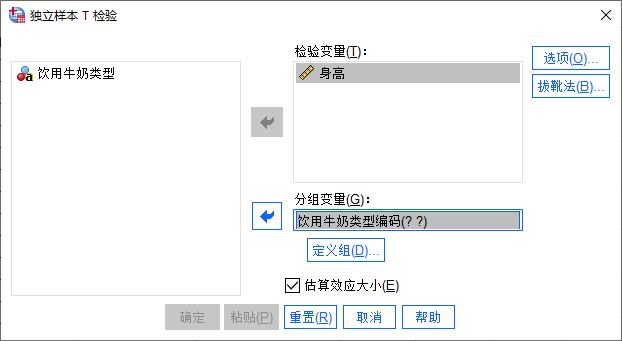
图2:选择变量 二、定义组
如图3所示,在定义组设置面板,需要设置个案组对应的编码数值,必须是数值型值。上一节中,我们已经将饮用牛奶类型变量重新编码为值1、2,因此,可以直接将其与组1、2匹配。
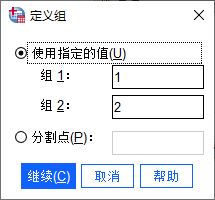
图3:定义组 三、选项设置
接着,打开“选项”按钮,设置检验分析的置信区间,一般情况下,设置为95%能确保较大的准确性。同时,设置“按具体分析排除个案”的缺失值处理方式。
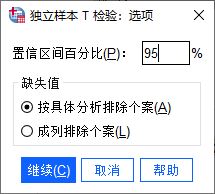
图4:选项设置 四、分析结果解读
完成以上设置后,运行分析,如图5所示,数据中分别包含63个饮用牛奶A与63个饮用牛奶B的身高数据,从其平均值看到,饮用牛奶A组的身高均值高于饮用牛奶B组的身高均值,但其差异是否显著还要看显著性数据。
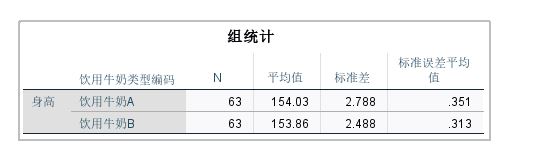
图5:描述统计数值 如图6所示,从独立样本检验图表的数据看到,显著性(双尾)的数值0.711大于0.05(95%置信区间下),不能拒绝原假设,也就是说,饮用牛奶A组的身高均值与饮用牛奶B组的身高均值无显著性差异。

图6:结果不显著 以上就是IBM SPSS Statistics独立样本T检验的应用介绍。该功能用于比较两组个案的均值差异,可用于验证两个对比个案组的均值数值是否有显著性差异,比如用于药物研究领域,验证两种药物有效性是否有差异等。
作者:泽洋
展开阅读全文
︾
标签:SPSS独立样本T检验
读者也访问过这里:热门文章SPSS数据分析显著性差异分析步骤 SPSS显著性差异分析结果怎么看数据的显著性差异分析主要有三种方法,分别是卡方检验、T检验和方差分析。这三种方法都有具体的数据要求:卡方检验是对多个类别的数据进行分析,T检验是对两组数据进行分析,方差分析是对多组数据进行检验。下面,小编具体说明一下SPSS数据分析显著性差异分析步骤,SPSS显著性差异分析结果怎么看。2022-01-07实践SPSS单因素方差分析之检验结果解读在《实践SPSS单因素方差分析之变量与检验方法设置》一文中,我们已经详细地演示了IBM SPSS Statistics单因素方差分析方法的变量选择以及相关的选项、对比设置。2021-01-11spss如何做显著性分析 spss显著性差异分析怎么标abc在统计分析中,显著性分析是分析相关因素之间是否存在显著影响关系的关键性指标,通过它可以说明分析结论是否由抽样误差引起还是实际相关的,可论证分析结果的准确性。下面大家一起来看看用spss如何做显著性分析,spss显著性差异分析怎么标abc。2022-03-14SPSS回归分析中的f值是什么 SPSS回归分析F值在什么范围合适回归分析中以R表示相关性程度的高低,以F评价回归分析是否有统计学的意义,使用IBM SPSS Statistics进行回归分析,可以非常快速的完成R,F的计算,并且给出回归曲线方程,那么,SPSS回归分析中f值是什么?SPSS回归分析F值在什么范围合适,本文结合实例向大家作简单的说明。2022-07-22SPSS多元logistic回归分析的使用技巧回归分析是数据处理中较为常用的一类方法,它可以找出数据变量之间的未知关系,得到较为符合变量关系的数学表达式,以帮助用户完成数据分析。2021-04-26SPSS相关性分析结果怎么看相关性分析是对变量或个案之间相关度的测量,在SPSS中可以选择三种方法来进行相关性分析:双变量、偏相关和距离。2021-04-23最新文章SPSS怎么合并变量为一个因子 SPSS因变量和因子怎么判断我们在使用SPSS进行问卷数据分析的过程中,多个题项往往共同测量同一个潜在维度,直接使用单个题项分析会导致结果零散,将这些相关变量合并为一个因子,能精准提炼数据的核心特征。接下来我将为大家介绍:SPSS怎么合并变量为一个因子,SPSS因变量和因子怎么判断的相关内容。2026-07-02SPSS怎么给数据分等级 SPSS怎么给数据加单位在处理数据的时候,我们可能会想给部分范围数据设置等级,比如分数大于90分的,设置为优秀;分数处于75到90之间的,设置为良好等。在SPSS软件里,我们可以用重新编码的方式,给数据分不同的等级,让其含义更丰富。接下来,本文会给大家介绍SPSS怎么给数据分等级,SPSS怎么给数据加单位的相关内容。2026-07-02SPSS怎么进行简单随机抽样 SPSS怎么进行信效度分析我们在进行问卷调研后,往往需要进行实证的数据分析。在这个过程里,简单随机抽样能够从全量数据中抽取代表性样本,是一种能降低数据分析工作量的核心方法,同时也可以保障样本的随机性与代表性。另外,信度检验验证数据的可靠性,效度分析检验问卷的结构合理性,二者是开展后续统计分析的重要前提。接下来我将为大家介绍:SPSS 怎么进行简单随机抽样,SPSS 怎么进行信效度分析的相关内容。2026-07-02SPSS做频数分布表如何分组 SPSS的频数分布表如何分析数据分析时,连续型变量的原始取值通常较为分散,直接统计频数的话,很难清晰呈现数据的整体分布规律。如果能够分组制作频数分布表,就能将零散的数据整合为有序的组别,直观展现不同区间的样本分布情况。接下来我将为大家介绍:SPSS做频数分布表如何分组,SPSS的频数分布表如何分析的相关内容。2026-07-02SPSS中的f值怎么算 SPSS中的f值显著性数值范围是多少在方差分析、回归分析等统计的方法中,f值多用于判断多组间均值差异是否显著、回归模型是否具有统计学意义。使用SPSS,无需手动计算复杂的f值公式,只需通过对应模块完成变量设置。接下来我将为大家介绍:SPSS中的f值怎么算,SPSS中的f值显著性数值范围是多少的相关内容。2026-07-02SPSS如何将数据转换成二分类 SPSS如何将数据转换成文本原始数据类型往往无法直接满足全部分析与展示需求,所以在数据分析的过程中,我们需要将连续变量或多分类变量转换成二分类变量。而将数值编码转换成文本标签,能让数据结果更直观易懂。接下来我将为大家介绍:SPSS如何将数据转换成二分类,SPSS如何将数据转换成文本的相关内容。2026-07-02读者也喜欢这些内容:
-
SPSS偏度和峰度的分析步骤 SPSS偏度和峰度的分析结果解读
偏度和峰度是我们在进行数据分析的过程中,判断数据是否符合正态分布的重要标准之一,通过这两个数值可以很清晰地看出数据的整体走势和集中状态。因此这两项数值也经常被用于市场学分析、股市分析中,能够帮忙用户去发现某些潜在的规律。今天我就以SPSS偏度和峰度的分析步骤,SPSS偏度和峰度的分析结果解读这两个问题为例,来向大家讲解一下关于偏度和峰度的相关知识。...
阅读全文 >
-
SPSS数据排序如何设置 SPSS数据排序功能最大值和最小值
数据分析作为SPSS的重要主题,包含了数量计算、数据预测、数值对比等方面,在汇总统计各类数值的基础上,我们常常会需要对数据进行排序比较,而排序就是根据数值的大小来进行排列。本文以SPSS数据排序如何设置,SPSS数据排序功能最大值和最小值这两个问题为例,带大家了解一下SPSS数据排序的知识。...
阅读全文 >
-

SPSS临床应用案例
在医疗科研领域,临床数据的统计分析是验证研究假设、得出科学结论的关键环节。某大型三甲医院作为大学医学院附属医院,其肿瘤科医生兼具临床诊疗与科研教学双重职责,在开展多项临床研究项目时积累了大量数据,亟需高效准确的统计分析工具。SPSS Statistics 凭借操作简便、功能全面的优势,成为该医院处理临床科研数据的首选工具。本文将以该医院肿瘤科的临床研究数据为例,详细阐述 SPSS 在统计描述、统计推断及统计建模中的具体应用,为医疗科研工作者提供参考。...
阅读全文 >
-

SPSS数据透视表好用吗 SPSS数据透视表变量两个值怎么做
从名称上我们就能看出,数据透视表是一种表格形式的数据分析工具。设定完整的数据透视表,不仅能够分析已有数据,还支持数据的动态更新和汇总运算,功能十分强大。今天我就以SPSS数据透视表好用吗,SPSS数据透视表变量两个值怎么做这两个问题为例,来向大家讲解一下SPSS中关于数据透视表的相关知识。...
阅读全文 >
-




