


- 首页
- 产品
- 下载
- 学生专享NEW
-
帮助中心
如何通过IBM SPSS Statistics完成客户细分
发布时间:2021-09-30 12: 14: 33
客户细分在营销行业中发挥着重要作用,通过客户细分,营销人员能够为特定的客户提供针对性的产品与服务,提高客户满意度的同时也能提高营销的效果。客户细分非常有用,但究竟如何才能实现客户细分?
在这个问题上,IBM SPSS Statistics(win)即可派上用场。作为一款强大的统计软件,SPSS中的聚类分析功能可以帮助营销人员完成客户细分。
一、什么是聚类分析
聚类分析指将研究对象按照某些标准或某些特征进行分类的分析过程。比如若以年龄为标准将人群进行分类,那么可将人群分为年轻人与老年人。
聚类分析的方法主要有快速聚类分析法与系统聚类分析法。客户分类主要是要求根据客户的特性将客户分成不同的群体,因此使用快速(K-Mean)聚类分析法即可。
如图1,在IBM SPSS Statistics中按照分析-分类-K均值聚类的顺序即可打开快速聚类分析的窗口。
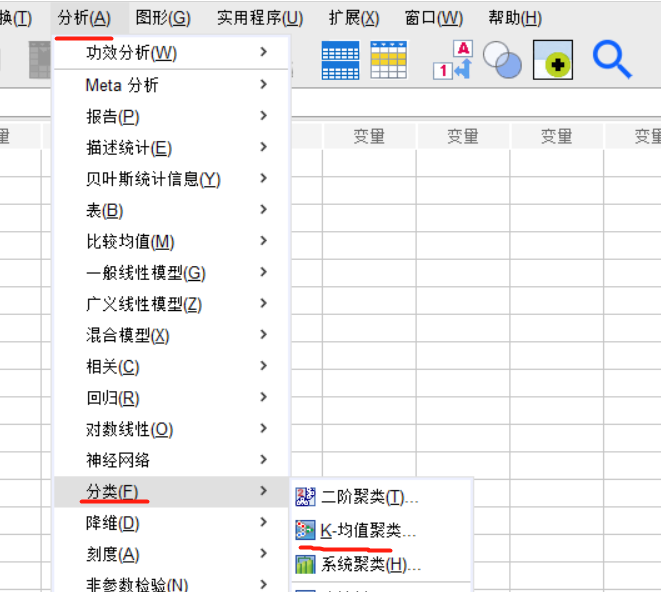
图1:快速聚类功能 二、应用快速聚类完成客户细分
本文将以一组通讯客户的数据为例,在IBM SPSS Statistics通过快速聚类的功能对这组客户进行细分。
图2: 数据录入 打开快速聚类分析的窗口后,我们需要将客户的通讯数据置入右侧的变量框,将客户编号置入个案标注依据框。
聚类数指的是根据录入的数据最终分成的类别数,需要根据数据的特点及需要进行设置,在这里我们设置为5。
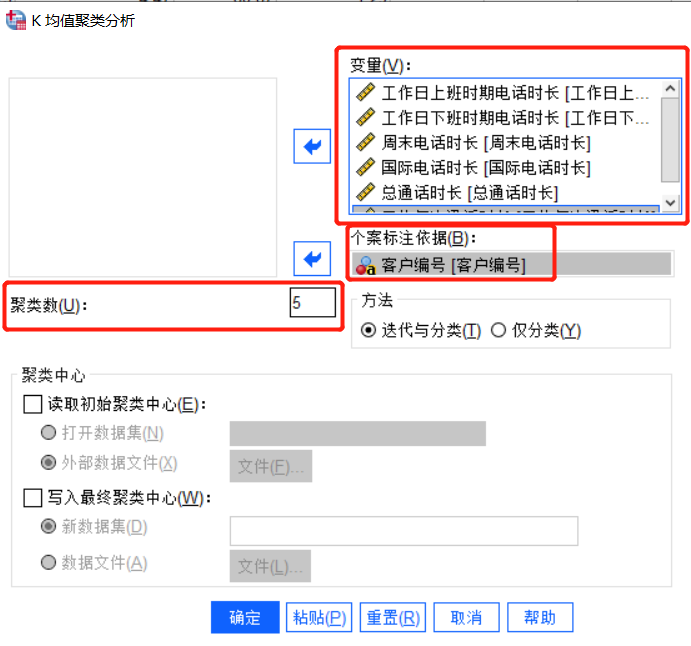
图3:快速聚类设置 在快速聚类分析窗口的右上角的点开迭代窗口,对最大迭代次数进行设置,若最大迭代次数太少,那么会导致聚类分析的失败。由于这个案例的样本较多,需要迭代的次数也会相应增多,因此本次的迭代次数设置为100。
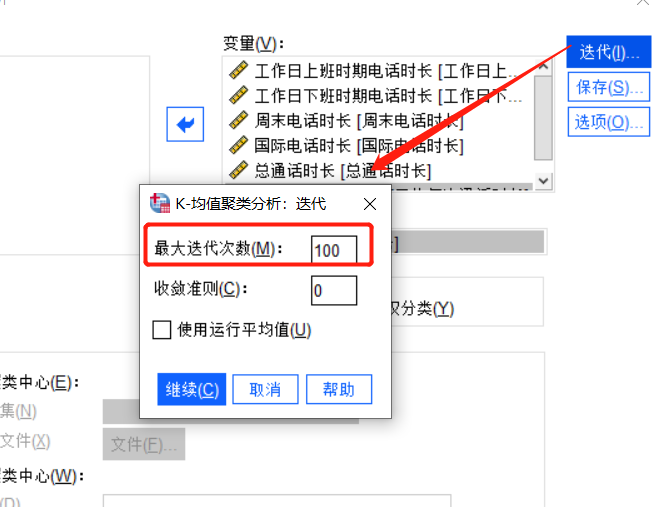
图4:最大迭代次数设置 三、输出分析结果
设置完成后点击确定,即可输出分析结果。在分析结果中,根据聚类中心,可知分类后每个类别的中心数据,对客户的分类即是通过计算其它客户数据与中心数据的距离,距离中心数据最近的客户数据就与该中心数据归为一类。
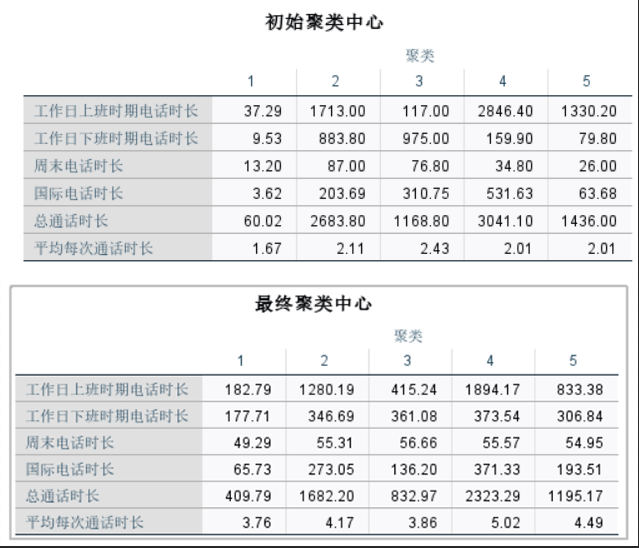
图5:聚类中心 根据每个聚类中的个案数目可知每类别包含的客户数量。
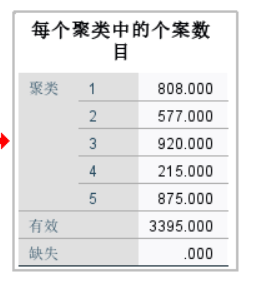
图6:客户数量 通过迭代历史记录可知进行的快速聚类分析是否成功,若最终迭代数归于0则说明此次快速聚类分析成功,若没有全部归于0,则失败,需要重新设置最大迭代次数。此次迭代了54次后所有聚类归于0,所以本次分析成功。
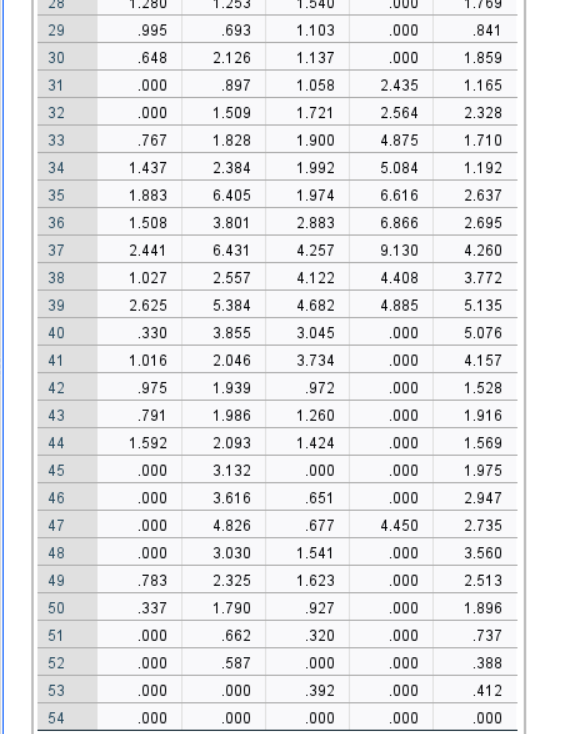
图7:迭代历史记录 根据SPSS快速聚类分析的结果,可知分成了5类的客户的具体情况,根据这一情况营销人员可以精确找到目标客户。
聚类分析除了可用于营销的客户细分外,在生物、地理等方面也能发挥巨大作用。更多的聚类分析功能以及SPSS的功能可以访问IBM SPSS Statistics中文网站。
作者:刘白
展开阅读全文
︾
标签:spss
- 上一篇:SPSS如何进行卡方检验
- 下一篇:如何在SPSS中进行数据文件合并
热门文章SPSS数据分析显著性差异分析步骤 SPSS显著性差异分析结果怎么看数据的显著性差异分析主要有三种方法,分别是卡方检验、T检验和方差分析。这三种方法都有具体的数据要求:卡方检验是对多个类别的数据进行分析,T检验是对两组数据进行分析,方差分析是对多组数据进行检验。下面,小编具体说明一下SPSS数据分析显著性差异分析步骤,SPSS显著性差异分析结果怎么看。2022-01-07实践SPSS单因素方差分析之检验结果解读在《实践SPSS单因素方差分析之变量与检验方法设置》一文中,我们已经详细地演示了IBM SPSS Statistics单因素方差分析方法的变量选择以及相关的选项、对比设置。2021-01-11spss如何做显著性分析 spss显著性差异分析怎么标abc在统计分析中,显著性分析是分析相关因素之间是否存在显著影响关系的关键性指标,通过它可以说明分析结论是否由抽样误差引起还是实际相关的,可论证分析结果的准确性。下面大家一起来看看用spss如何做显著性分析,spss显著性差异分析怎么标abc。2022-03-14SPSS回归分析中的f值是什么 SPSS回归分析F值在什么范围合适回归分析中以R表示相关性程度的高低,以F评价回归分析是否有统计学的意义,使用IBM SPSS Statistics进行回归分析,可以非常快速的完成R,F的计算,并且给出回归曲线方程,那么,SPSS回归分析中f值是什么?SPSS回归分析F值在什么范围合适,本文结合实例向大家作简单的说明。2022-07-22SPSS多元logistic回归分析的使用技巧回归分析是数据处理中较为常用的一类方法,它可以找出数据变量之间的未知关系,得到较为符合变量关系的数学表达式,以帮助用户完成数据分析。2021-04-26SPSS相关性分析结果怎么看相关性分析是对变量或个案之间相关度的测量,在SPSS中可以选择三种方法来进行相关性分析:双变量、偏相关和距离。2021-04-23最新文章SPSS怎么合并变量为一个因子 SPSS因变量和因子怎么判断我们在使用SPSS进行问卷数据分析的过程中,多个题项往往共同测量同一个潜在维度,直接使用单个题项分析会导致结果零散,将这些相关变量合并为一个因子,能精准提炼数据的核心特征。接下来我将为大家介绍:SPSS怎么合并变量为一个因子,SPSS因变量和因子怎么判断的相关内容。2026-07-02SPSS怎么给数据分等级 SPSS怎么给数据加单位在处理数据的时候,我们可能会想给部分范围数据设置等级,比如分数大于90分的,设置为优秀;分数处于75到90之间的,设置为良好等。在SPSS软件里,我们可以用重新编码的方式,给数据分不同的等级,让其含义更丰富。接下来,本文会给大家介绍SPSS怎么给数据分等级,SPSS怎么给数据加单位的相关内容。2026-07-02SPSS怎么进行简单随机抽样 SPSS怎么进行信效度分析我们在进行问卷调研后,往往需要进行实证的数据分析。在这个过程里,简单随机抽样能够从全量数据中抽取代表性样本,是一种能降低数据分析工作量的核心方法,同时也可以保障样本的随机性与代表性。另外,信度检验验证数据的可靠性,效度分析检验问卷的结构合理性,二者是开展后续统计分析的重要前提。接下来我将为大家介绍:SPSS 怎么进行简单随机抽样,SPSS 怎么进行信效度分析的相关内容。2026-07-02SPSS做频数分布表如何分组 SPSS的频数分布表如何分析数据分析时,连续型变量的原始取值通常较为分散,直接统计频数的话,很难清晰呈现数据的整体分布规律。如果能够分组制作频数分布表,就能将零散的数据整合为有序的组别,直观展现不同区间的样本分布情况。接下来我将为大家介绍:SPSS做频数分布表如何分组,SPSS的频数分布表如何分析的相关内容。2026-07-02SPSS中的f值怎么算 SPSS中的f值显著性数值范围是多少在方差分析、回归分析等统计的方法中,f值多用于判断多组间均值差异是否显著、回归模型是否具有统计学意义。使用SPSS,无需手动计算复杂的f值公式,只需通过对应模块完成变量设置。接下来我将为大家介绍:SPSS中的f值怎么算,SPSS中的f值显著性数值范围是多少的相关内容。2026-07-02SPSS如何将数据转换成二分类 SPSS如何将数据转换成文本原始数据类型往往无法直接满足全部分析与展示需求,所以在数据分析的过程中,我们需要将连续变量或多分类变量转换成二分类变量。而将数值编码转换成文本标签,能让数据结果更直观易懂。接下来我将为大家介绍:SPSS如何将数据转换成二分类,SPSS如何将数据转换成文本的相关内容。2026-07-02读者也喜欢这些内容:
-
SPSS怎样进行聚类分析 SPSS聚类中心不稳定怎么解决
对于经常需要与数据分析打交道的小伙伴来说,想必对聚类分析这一分析操作肯定是不陌生的。聚类分析指的是收集相似的数据样本,并在相似数据样本的基础之上收集信息来进行分类,下面以SPSS为例,向大家介绍SPSS怎样进行聚类分析,SPSS聚类中心不稳定怎么解决的具体内容。...
阅读全文 >
-
在SPSS中分类变量可以转换为连续变量吗 SPSS分类变量与连续变量的相关分析怎么做
SPSS是一款比较优秀的数据统计分析软件,很多统计达人都喜欢使用SPSS进行各种数据分析,而SPSS之所以深受大家的喜爱,除了有着强大的数据分析功能,还可以进行数据处理,例如SPSS可以将连续变量和分类变量进行转换,下面给大家详细讲解在SPSS中分类变量可以转换为连续变量吗,SPSS分类变量与连续变量的相关分析怎么做。...
阅读全文 >
-
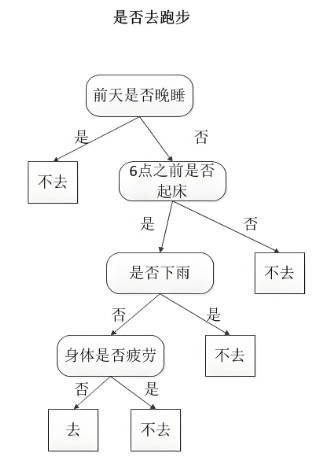
SPSS决策树是什么 SPSS决策树分类规则生成步骤
决策树是非常经典的一种数据分析模型,它以树状结构来呈现决策结果,从而实现数据的分类和预测。今天我就以SPSS决策树是什么,SPSS决策树分类规则生成步骤这两个问题为例,来向大家讲解一下SPSS中有关于决策树的相关知识。...
阅读全文 >
-

SPSS数据分析方法包括哪些 SPSS数据分析软件怎么使用
数据分析的主要研究内容是数据的收集、分析、解释和可视化,通过概率理论和严格的数学描述产生统计推断,使我们能够从样本数据中推断总体特性。在调查研究、实验设计,药物效果评估,临床试验等等学科,数据分析都发挥着不可替代的作用。数据分析工作涉及的数学概念广泛,计算量大,人工计算需要相当的数学基础和工作量,但借助专业的统计分析软件IBM SPSS Statistics,可以高效的完成数据分析工作,并且可以对数据进行可视化。SPSS数据分析方法包括哪些,SPSS数据分析软件怎么使用,本文向大家作简单介绍。...
阅读全文 >





