




仅剩:

发布时间:2020-11-13 11: 04: 42
IBM SPSS Statistics的数据重构功能,也被称为数据重组,包含了将选定变量重组为个案、将选定个案重组为变量与变换所有数据(即数据转置)的功能。
本文中,会进行“将选定个案重组为变量”的功能讲解。当我们要进行分组变量的分析时,就需要将个案组数据转换为变量组数据,比如一般线性模型分析中的单变量、多变量和方差成分。
一、打开数据文件
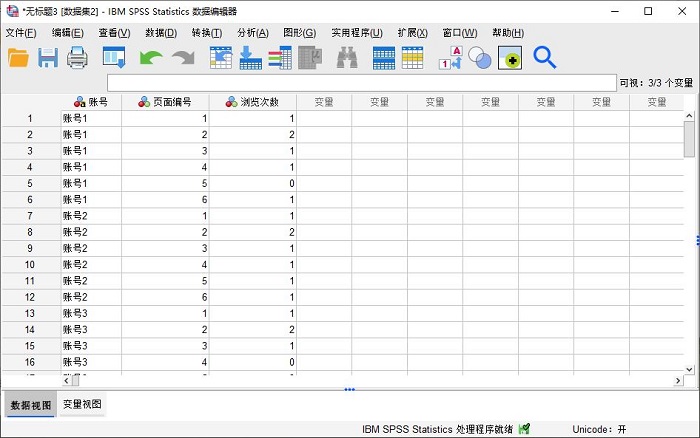
首先,如图1所示,打开个案组类型的数据。当前数据展示了个案在不同页面中的浏览次数,需要将“页面编号”重组为新变量。
二、使用数据重构功能
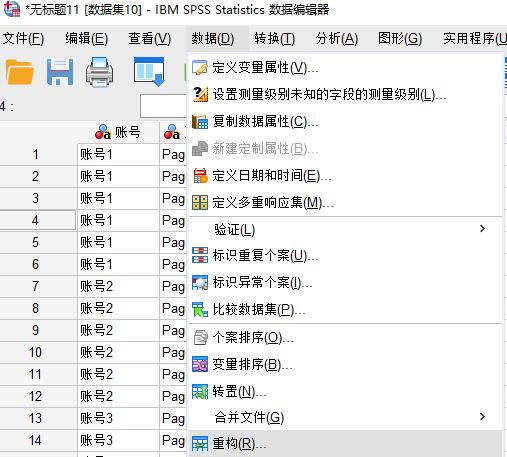
如图2所示,打开数据菜单中的重构数据功能。
三、选择将个案重构为变量
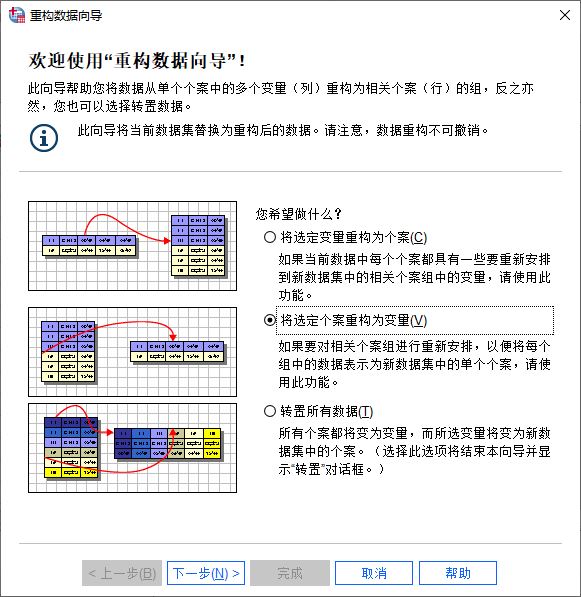
如图3所示,在打开的重构数据向导中,可以选取数据重构的方法。我们选择“将选定个案重构为变量”选项。
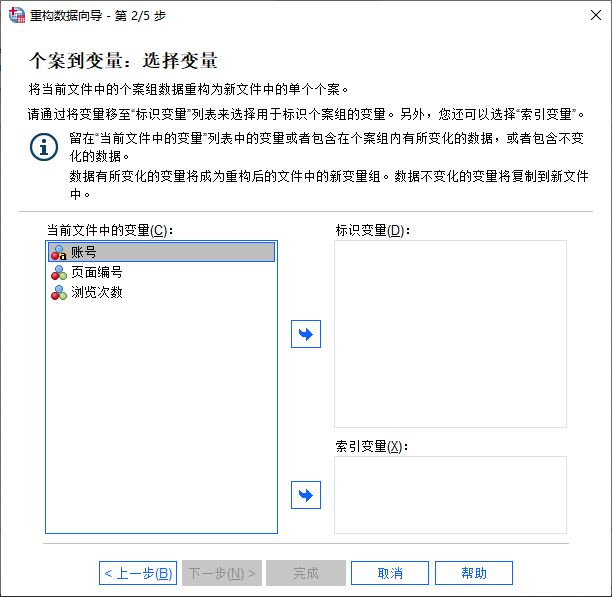
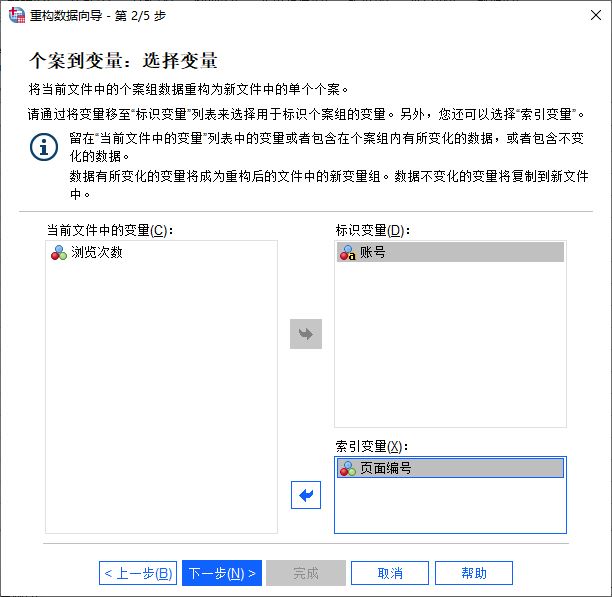
接着,我们需要进行比较关键的一步—选择变量。其中的变量含义如下:
1.标识变量,即用来识别个案的变量,比如本例中的“账号”变量,可用于识别个案。
2.索引变量,当前数据中用于创建新列的的变量。当变量添加为索引变量后,系统会将该变量中的变量值重组为新列变量。比如本例中的“页面编号”变量。
3.当前文件中的变量,不发生变更的变量,该变量的数据可能会因重构而改变。
根据当前数据的重构的目的,即将“账号”的个案组数据重构为单个个案,如图5所示,需将“账号”设置为标识变量,将“页面编号”设置为索引变量,保持“浏览次数”为当前文件中的变量。
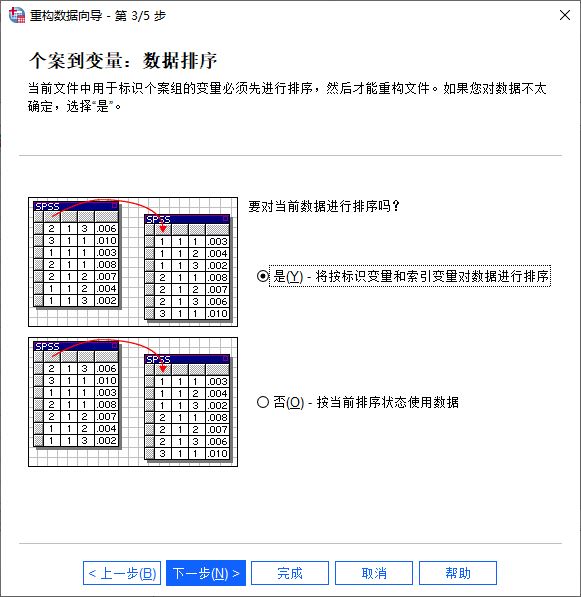
接着,设置数据的排序方式,可按照标识变量与索引变量进行排序,也可选择按照当前排序状态排序。
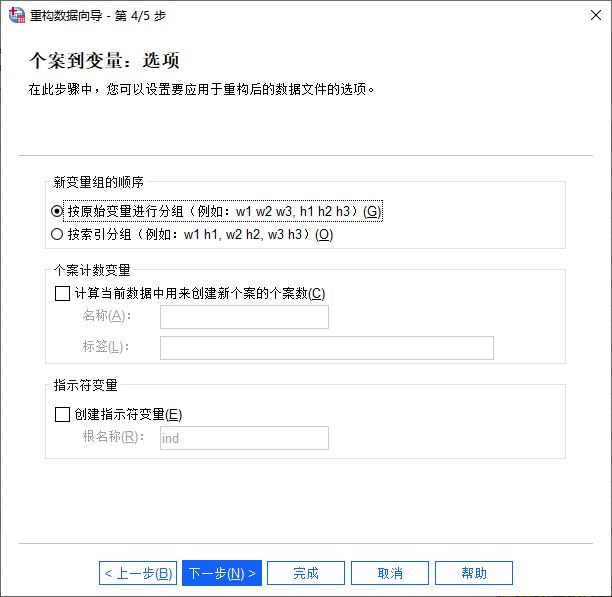
最后,对应用于重构后的数据文件选项进行设置:
1.设置新变量组的顺序,可按原始变量分组(先排序变量1,再排序变量2,如w1 w2 w3,h1 h2 h3)或按索引变量分组(所有变量放在一起排序,如w1 h1,w2 h2,)
2.添加个案计数变量
3.创建指示符变量,可使用索引变量在新的数据文件中创建指示符变量,它为索引变量的每个唯一值创建一个新变量。
完成数据重构设置后,我们可以选择立即重构数据,或保存、修改算法后再重构数据。

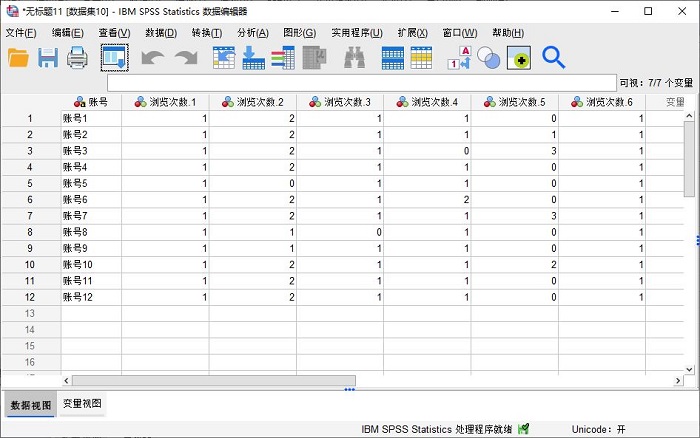
完成数据重后,如图8所示,数据展现了在不同个案下不同索引变量的浏览次数。
以上就是SPSS数据重构中将选定个案重组为变量的方法演示,对于数据重构中的将选定变量重组为个案、数据转置的方法介绍,可前往IBM SPSS Statistics中文网继续学习。
展开阅读全文
︾
读者也喜欢这些内容:

SPSS交叉表卡方与非参数卡方检验有何区别 SPSS交叉表卡方检验结果解读
在SPSS统计分析中,卡方检验是一种我们经常使用到的非参数方法。但是,其实很多人会混淆“交叉表卡方检验”和“非参数卡方检验”。两者虽然名字十分相似,但是针对的是完全不同的分析场景。接下来我将为大家介绍:SPSS交叉表卡方与非参数卡方检验有何区别,SPSS交叉表卡方检验结果解读的相关内容,帮助大家精准区分方法、读懂检验结果。...
阅读全文 >

SPSS软件安装与注册试用教程
IBM SPSS Statistics作为一款全球知名的数据统计分析软件,无论是在学术研究领域,还是商业经营领域,都起着举足轻重的作用。其推出的一系列统计分析方法,可用于数据的分析运算、挖掘、模型预测等多个方面。...
阅读全文 >
SPSS显著性小于0.001的意义 SPSS显著性大于0.05怎么办
在使用SPSS软件进行数据分析工作的过程中,得到的显著性水平分析结果具有极为重要的作用。它能够帮助我们衡量变量之间是否存在真实的关联,或者不同组别数据之间是否存在实质性的差异。今天我们就一起来探讨关于SPSS显著性小于0.001的意义,SPSS显著性大于0.05怎么办的问题。...
阅读全文 >
在SPSS中分类变量可以转换为连续变量吗 SPSS分类变量与连续变量的相关分析怎么做
SPSS是一款比较优秀的数据统计分析软件,很多统计达人都喜欢使用SPSS进行各种数据分析,而SPSS之所以深受大家的喜爱,除了有着强大的数据分析功能,还可以进行数据处理,例如SPSS可以将连续变量和分类变量进行转换,下面给大家详细讲解在SPSS中分类变量可以转换为连续变量吗,SPSS分类变量与连续变量的相关分析怎么做。...
阅读全文 >
