


- 首页
- 产品
- 下载
- 学生专享NEW
-
帮助中心
SPSS数据重构—将选定变量重组为个案
发布时间:2020-11-12 13: 57: 37
IBM SPSS Statistics的数据重构功能,也被称为数据重组,包含了将选定变量重组为个案、将选定个案重组为变量与变换所有数据(即数据转置)的功能。
为什么要进行数据重组?这是因为一些分析方法可能需要采用个案组或变量组的数据来分析,因此,需要通过重组的方式转换数据。本文将会重点介绍如何将选定变量重组为个案。
一、打开数据文件
首先,如图1所示,打开变量组类型的数据。该数据记录了每个账号在不同页面的浏览次数。
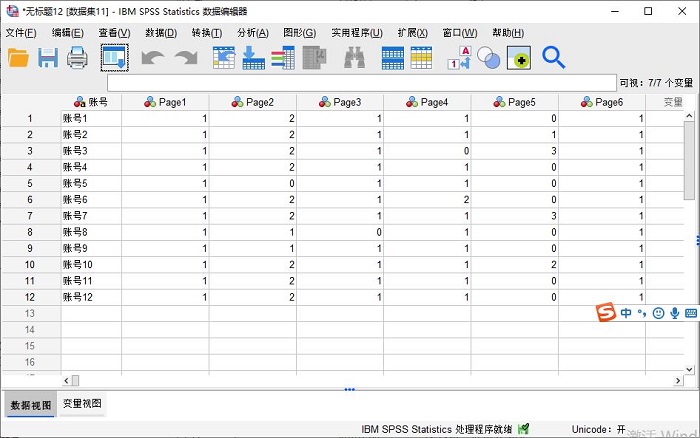
图1:变量组数据 二、使用数据重构功能
接着,如图2所示,打开数据菜单中的重构选项。
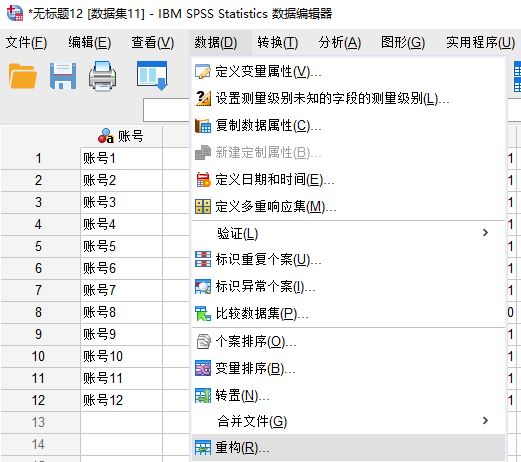
图2:数据重构功能 三、选择将选定变量重构为个案
如图3所示,在打开的重构数据向导中,可以选取数据重构的方法。我们选择“将选定变量重构为个案”选项。
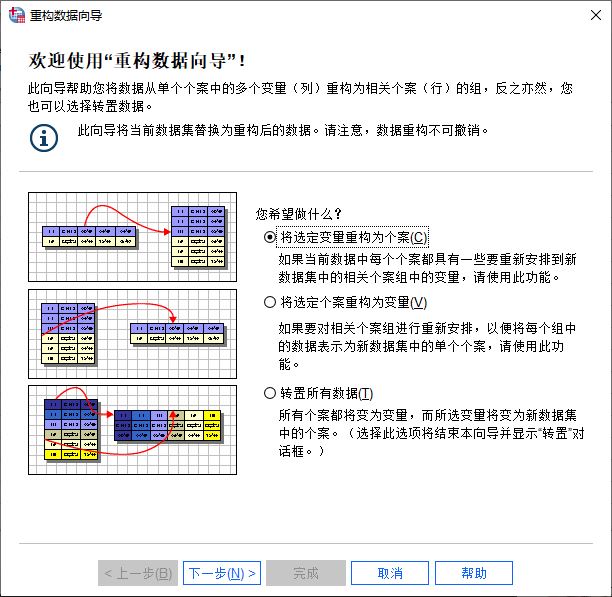
图3:重构数据向导 接着,就会来到比较关键的步骤-选择变量。我们来看看如何进行变量选择:
1.当前文件中的变量,即当前数据集中所包含的变量。
2.个案组标识,即用以识别个案的变量,比如本例中的“账号”变量,可作为个案组标识来识别不同的个案。
3.目标变量,即重构后出现的变量,需要将需重构的变量添加为“要转置的变量”,然后再为这些转置的变量创建一个目标变量,说明这些转置变量的特征。比如在本例中,将“Page1-6”的变量添加为要转置的变量,然后创建一个名为“Page”的目标变量。
4.固定变量,即保持不变的变量,本例中无固定变量。
如图4所示,我们已经按照变量的属性完成了变量的选择。
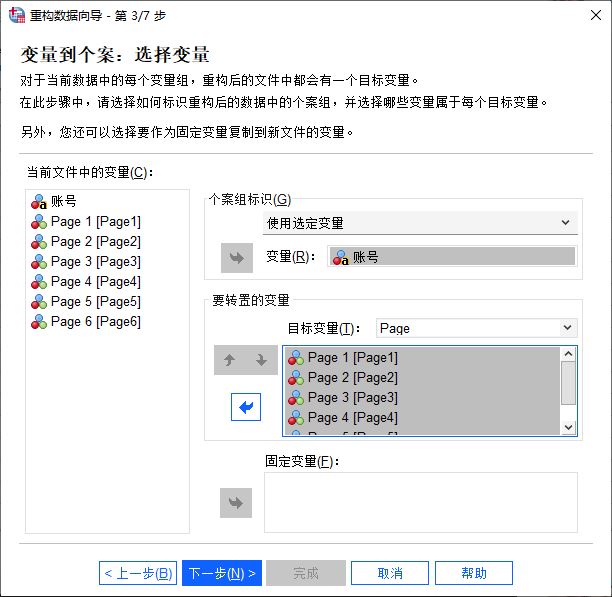
图4:选择变量 接着,需要创建索引变量。
当创建的目标变量的数值在单个个案中会有多个变量出现时,就需要创建索引变量识别。本例中,我们使用的是单因子的目标变量,可以选择创建“一个”索引变量。
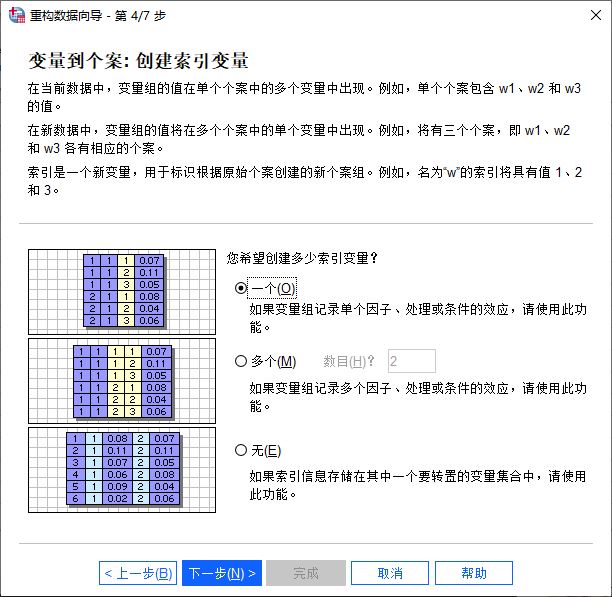
图5:创建索引变量 然后,再设置索引值的类型,方便识别不同个案目标变量对应索引值的含义。如图6所示,可使用连续数字或变量名进行识别。
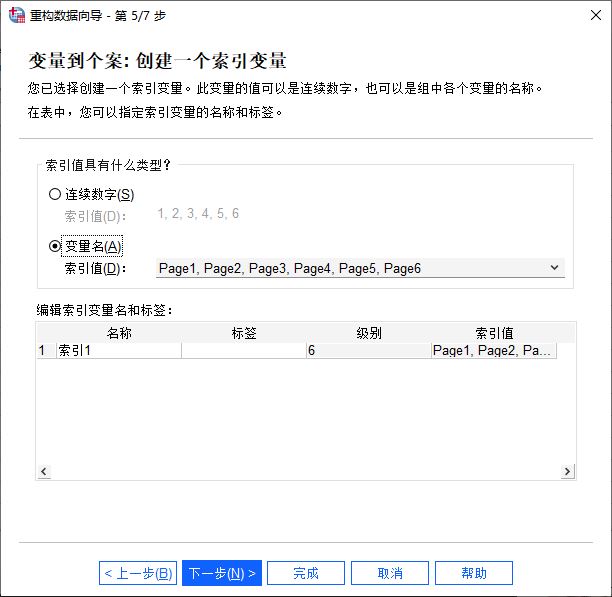
图6:设置索引值类型 最后,对应用于重构的数据文件选项进行设置:
1. 对未选择的变量的处理方式,删除或保留为固定变量
2. 转置后的变量中的系统缺失值或控制,创建新个案或废弃数据
3. 创建计数变量
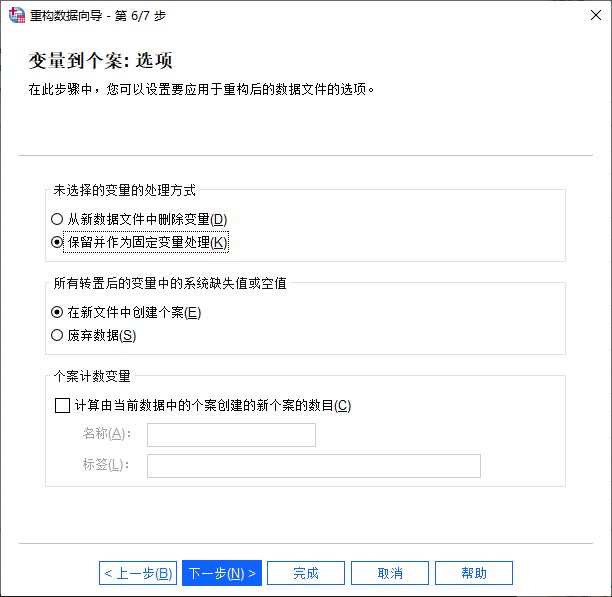
图7:设置重构后的数据文件 完成数据重构设置后,我们可以选择立即重构数据,或保存、修改算法后再重构数据。
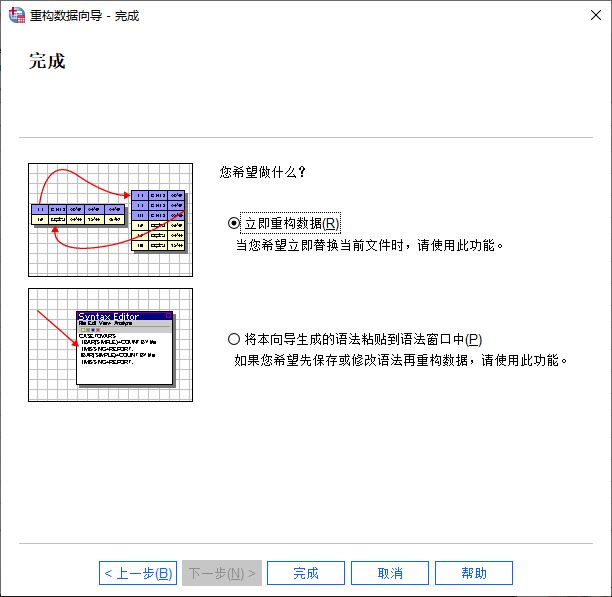
图8:立即重构数据 完成数据重构后,可以看到账号1中包含了6种索引值变量,对应每一个索引值变量,有其对应的“Page”数。
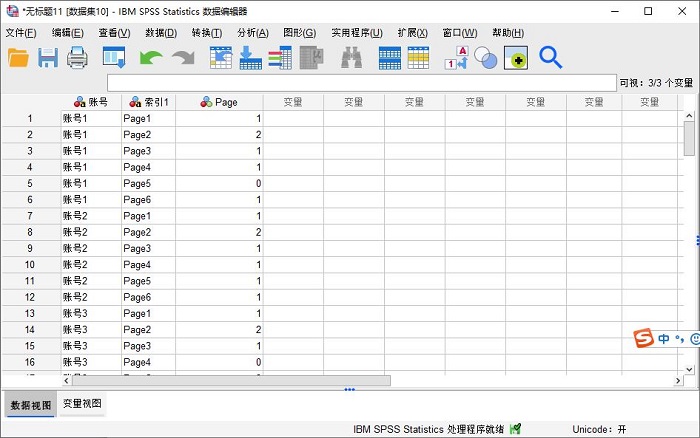
图9:完成数据的重构 以上就是SPSS数据重构中将选定变量重组为个案的方法演示,对于数据重构中的将选定个案重组为变量、数据转置的方法介绍,可前往IBM SPSS Statistics中文网继续学习。
展开阅读全文
︾
标签:SPSS数据重构,变量重组
读者也访问过这里:热门文章SPSS数据分析显著性差异分析步骤 SPSS显著性差异分析结果怎么看数据的显著性差异分析主要有三种方法,分别是卡方检验、T检验和方差分析。这三种方法都有具体的数据要求:卡方检验是对多个类别的数据进行分析,T检验是对两组数据进行分析,方差分析是对多组数据进行检验。下面,小编具体说明一下SPSS数据分析显著性差异分析步骤,SPSS显著性差异分析结果怎么看。2022-01-07实践SPSS单因素方差分析之检验结果解读在《实践SPSS单因素方差分析之变量与检验方法设置》一文中,我们已经详细地演示了IBM SPSS Statistics单因素方差分析方法的变量选择以及相关的选项、对比设置。2021-01-11spss如何做显著性分析 spss显著性差异分析怎么标abc在统计分析中,显著性分析是分析相关因素之间是否存在显著影响关系的关键性指标,通过它可以说明分析结论是否由抽样误差引起还是实际相关的,可论证分析结果的准确性。下面大家一起来看看用spss如何做显著性分析,spss显著性差异分析怎么标abc。2022-03-14SPSS回归分析中的f值是什么 SPSS回归分析F值在什么范围合适回归分析中以R表示相关性程度的高低,以F评价回归分析是否有统计学的意义,使用IBM SPSS Statistics进行回归分析,可以非常快速的完成R,F的计算,并且给出回归曲线方程,那么,SPSS回归分析中f值是什么?SPSS回归分析F值在什么范围合适,本文结合实例向大家作简单的说明。2022-07-22SPSS多元logistic回归分析的使用技巧回归分析是数据处理中较为常用的一类方法,它可以找出数据变量之间的未知关系,得到较为符合变量关系的数学表达式,以帮助用户完成数据分析。2021-04-26SPSS相关性分析结果怎么看相关性分析是对变量或个案之间相关度的测量,在SPSS中可以选择三种方法来进行相关性分析:双变量、偏相关和距离。2021-04-23最新文章SPSS多重线性回归哑变量怎么设置 SPSS多重线性回归结果解读我们在进行多重线性回归分析时,分类变量是没法直接纳入模型的,这时候就需要通过设置哑变量来将其转化为可计算的数值变量。接下来我将为大家介绍:SPSS多重线性回归哑变量怎么设置,SPSS多重线性回归结果解读的相关内容。2026-07-02SPSS多重插补数据怎么分析 SPSS多重插补后用哪个结果在数据分析的领域中,多重插补数据是一项重要的数据分析方法,许多数据分析场景中都可以看到它的影子。多重插补数据并不是简单地对数据的内容进行补充,而是在填补缺失值的基础上对数据进行了再一次的分析和模拟,体现出数据样本的不确定性。所以后续的数据分析需要在多重插补的数据分析基础之上根据结果进行合并,这样才能得到更加准确的结果。下面以SPSS为例,给大家介绍SPSS多重插补数据怎么分析,SPSS多重插补后用哪个结果的具体内容。2026-07-01SPSS如何绘制茎叶图 SPSS茎叶图怎么分析我们在进行数据分析的过程中,可以借助数据分析后绘制的图像来辅助我们解读数据。数据分析图像能够更加直观地表现出数据的变化幅度以及分布状况,而在数据分析的图像中,茎叶图能够在保留数据信息的同时展现数据样本的轮廓。所以茎叶图就可以成为我们数据分析的一个重要工具,但是许多小伙伴对茎叶图的绘制和使用并不熟悉。下面以SPSS为例,给大家介绍SPSS如何绘制茎叶图,SPSS茎叶图怎么分析的具体内容。2026-07-01SPSS怎么对多选题进行频率分析 SPSS频率分析怎么做我们在问卷数据分析过程中,常常会遇到多选题。这时候,常规的频率分析可能就无法适配多选项的计数需求,而SPSS中的多重响应功能可精准完成多选题的频率统计,同时也能通过基础频率分析功能完成单选题的常规统计。接下来我将为大家介绍:SPSS怎么对多选题进行频率分析,SPSS频率分析怎么做的相关内容。2026-07-01SPSS回归分析加入中介变量怎么做 SPSS中介效应分析结果解读相信大家在进行社会科学研究的时候,常常使用到中介效应分析这个方法。中介效应分析能够清晰地揭示自变量对因变量的影响是否通过中介变量进行传递,让变量间的作用路径更明确。接下来我将为大家介绍:SPSS回归分析加入中介变量怎么做,SPSS中介效应分析结果解读的相关内容。2026-06-02SPSS随机性检验步骤分析 SPSS随机性检验结果分析数据序列的随机性是保障后续统计检验有效性的重要前提,如果出现了非随机分布的数据。有可能会导致分析结果出现偏差。在SPSS中,我们通过游程检验可以快速完成数据随机性的判断。接下来我将为大家介绍:SPSS随机性检验步骤分析,SPSS随机性检验结果分析的相关内容。2026-06-02读者也喜欢这些内容:
-
SPSS如何导入日期数据 SPSS导入日期数据后格式不对怎么调整
通过对不同时态下物体的发展状态进行分析,我们可以获得一条明确的发展脉络图,借由这份脉络图,我们可以预测事物未来的发展趋势。今天我就以SPSS如何导入日期数据,SPSS导入日期数据后格式不对怎么调整这两个问题为例,来向大家讲解一下SPSS中关于日期数据的知识。...
阅读全文 >
-
SPSS如何做因子分析 SPSS因子载荷解释不清晰怎么办
每当我们在进行数据分析的工作时,因子分析是绕不开的一个话题。它在一组数据的分析中占据了重要的位置,主要用来检验不同变量之间是否存在共性的因子,而这些因子会影响数据的变量,例如从学生的考试成绩中判断是否存在共有的数据因子,这部分共有的数据因子对学生的成绩好坏会产生影响。下面我们以一款专业的数据分析软件SPSS为例,向大家介绍SPSS如何做因子分析,SPSS因子载荷解释不清晰怎么办的具体内容。...
阅读全文 >
-
SPSS显著性小于0.001的意义 SPSS显著性大于0.05怎么办
在使用SPSS软件进行数据分析工作的过程中,得到的显著性水平分析结果具有极为重要的作用。它能够帮助我们衡量变量之间是否存在真实的关联,或者不同组别数据之间是否存在实质性的差异。今天我们就一起来探讨关于SPSS显著性小于0.001的意义,SPSS显著性大于0.05怎么办的问题。...
阅读全文 >
-
SPSS如何计算z-score SPSS做z-score标准化
作为综合性的数字分析工具,SPSS不仅可以实现数值计算和比对的功能,还能够帮助研究者检验和提取出异常数值,也就是SPSS的检验功能,例如z-score的方法可以将所有数据转化为标准化数据,再依据z值标准筛选出异常数值。本文以SPSS如何计算z-score,SPSS做z-score标准化这两个问题为例,简单介绍一下SPSS的z-score方法如何操作。...
阅读全文 >
-





