


- 首页
- 产品
- 下载
- 学生专享NEW
-
帮助中心
用SPSS对数据进行分类汇总
发布时间:2021-05-11 11: 07: 15
在日常办公和学习研究中,经常需要对数据进行分类汇总。比如在统计公司员工的工资和年龄的时候,要求根据员工的性别求出员工的平均工资和平均年龄。就会用到分类汇总的功能,本文我会用IBM SPSS Statistics进行数据的分类汇总的演示。
1、数据展示
如图所示,是一个公司的员工信息数据集。我将在此基础上,展示如何用IBM SPSS Statistics中的分类汇总功能求男女员工的平均工资和平均年龄。
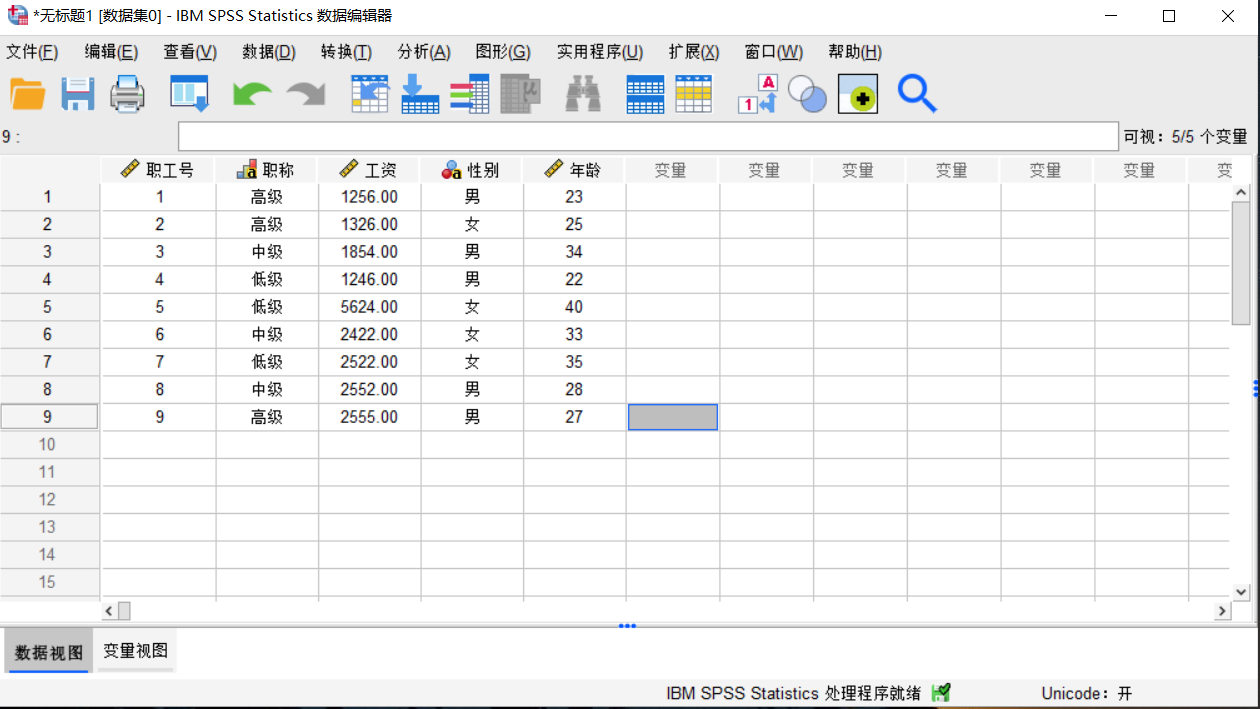
图1:数据界面 2、菜单位置
第一步点击菜单栏的“数据”按钮,第二步点击下级菜单的“汇总”选项。
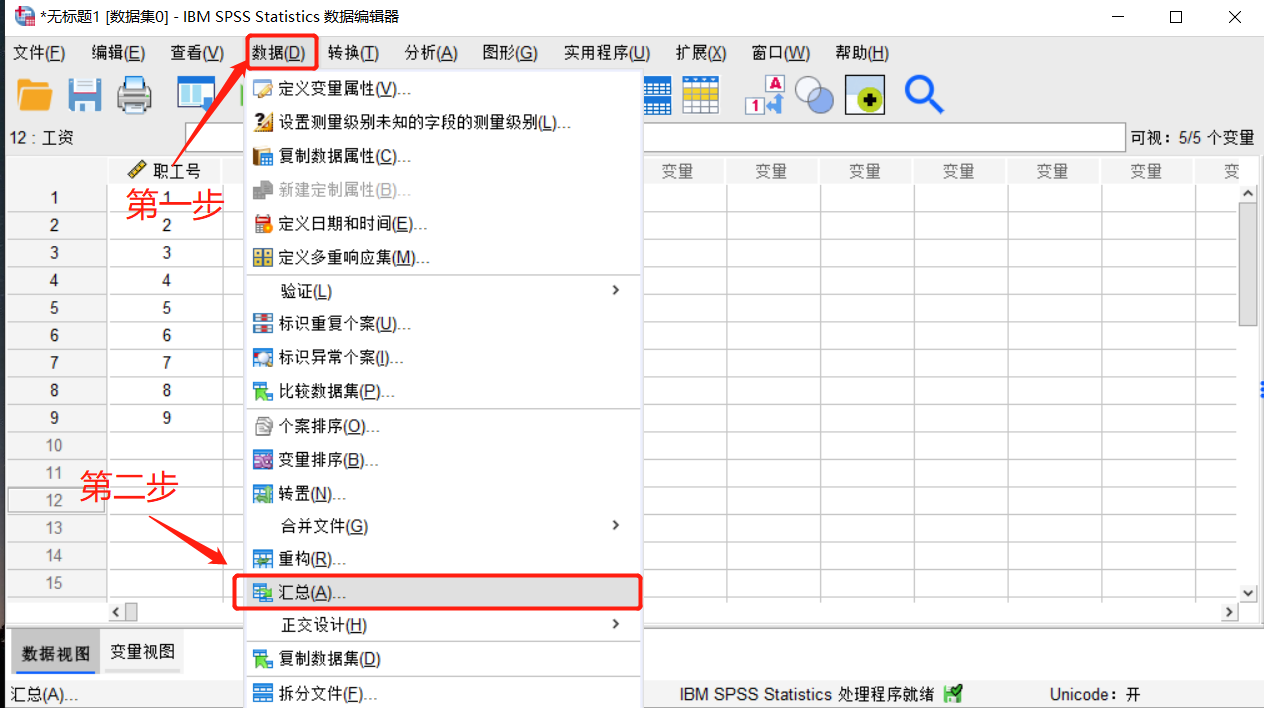
图2:菜单位置 3、选择分界变量和变量摘要
数据分类汇总的定义是:按指定的分类变量对观测值进行分组,对每组记录的各变量求指定的描述统计量。根据定义我们不难发现,选择分界变量就是分类的过程,选择变量摘要就是汇总的过程。
如图所示,我们先选中性别将性别加入到分界变量中,这一步的目的是用性别作为分类标准。然后我们将工资和年龄选中依次加入到变量摘要中,这样我们在接下来的步骤中就可以用函数对工资和年龄进行操作。
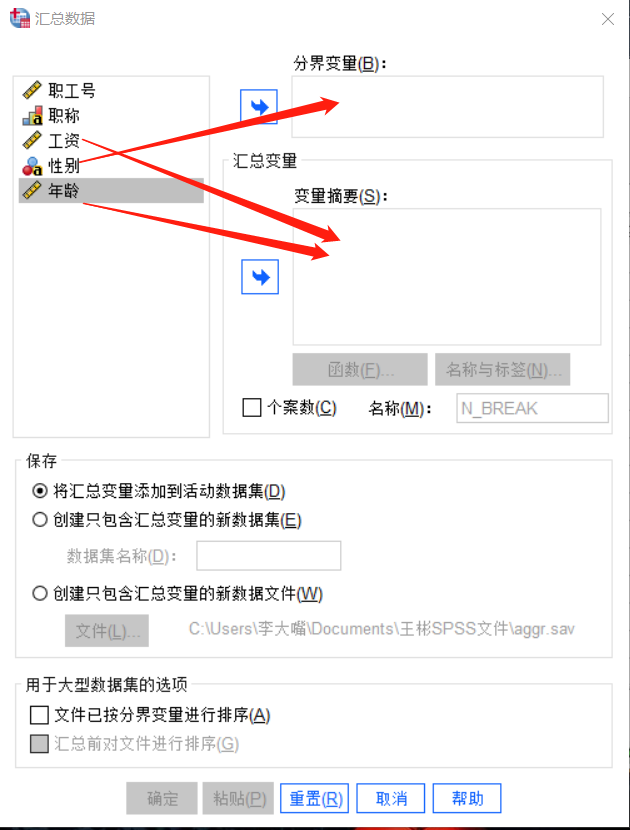
图3:选择分界变量和变量摘要 4、选择合适的函数
如图所示,已经将变量加入到相应的位置,我们点击下方的“函数”按钮。
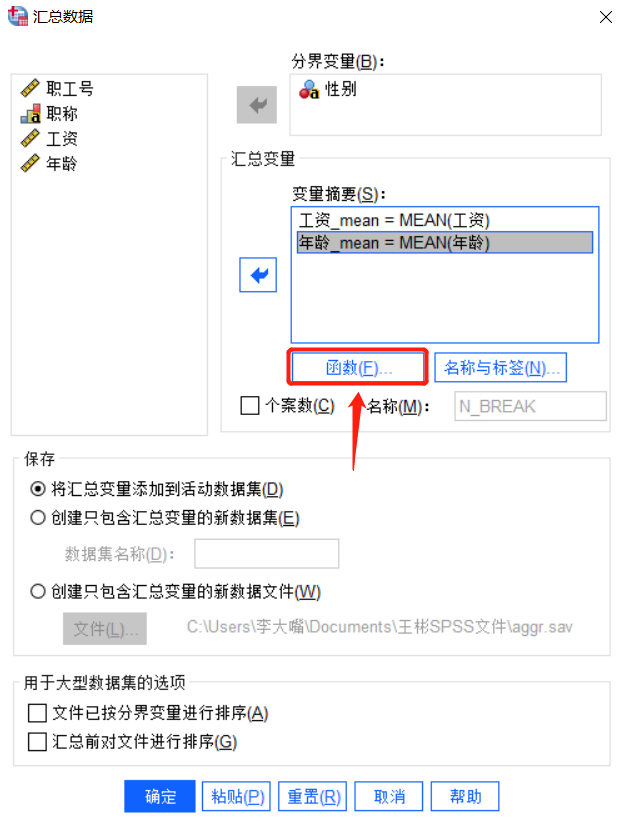
图4:函数 进入汇总函数界面之后,我们可以根据自己的需要选择函数。
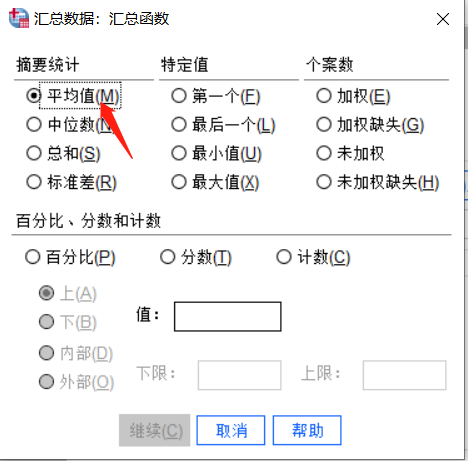
图5:选择函数 5、结果展示
如图所示,这里有三个选项。选择第一个我们会将数据直接生成到原先的数据集中,选择第二个会生成一个新的数据集去存储结果,选择第三个会在指定文件下保存结果。这里我们选择第一个,如果有其他需求可以根据自身情况去选择。
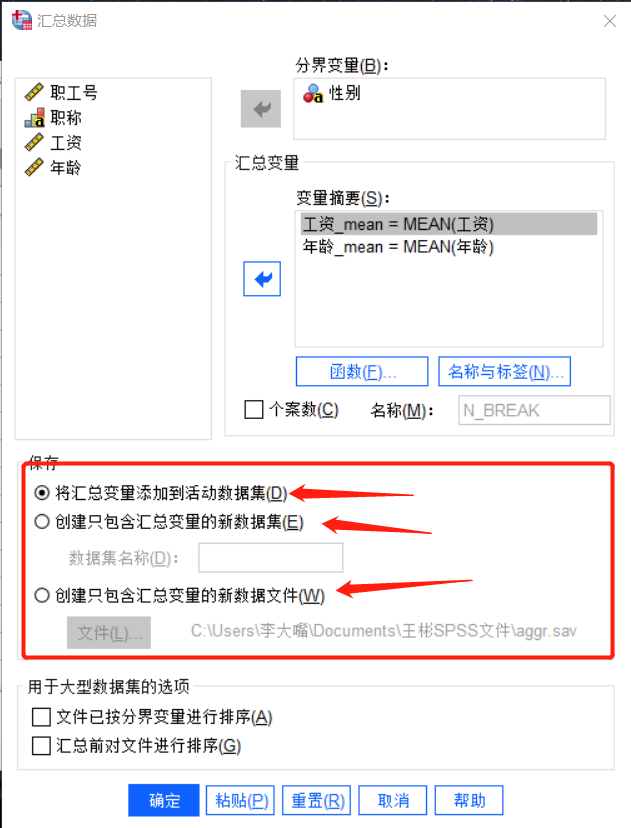
图6:选择结果生成位置 如图所示,在原先的数据基础上,已经成功生成了男女员工的平均工资和平均年龄。
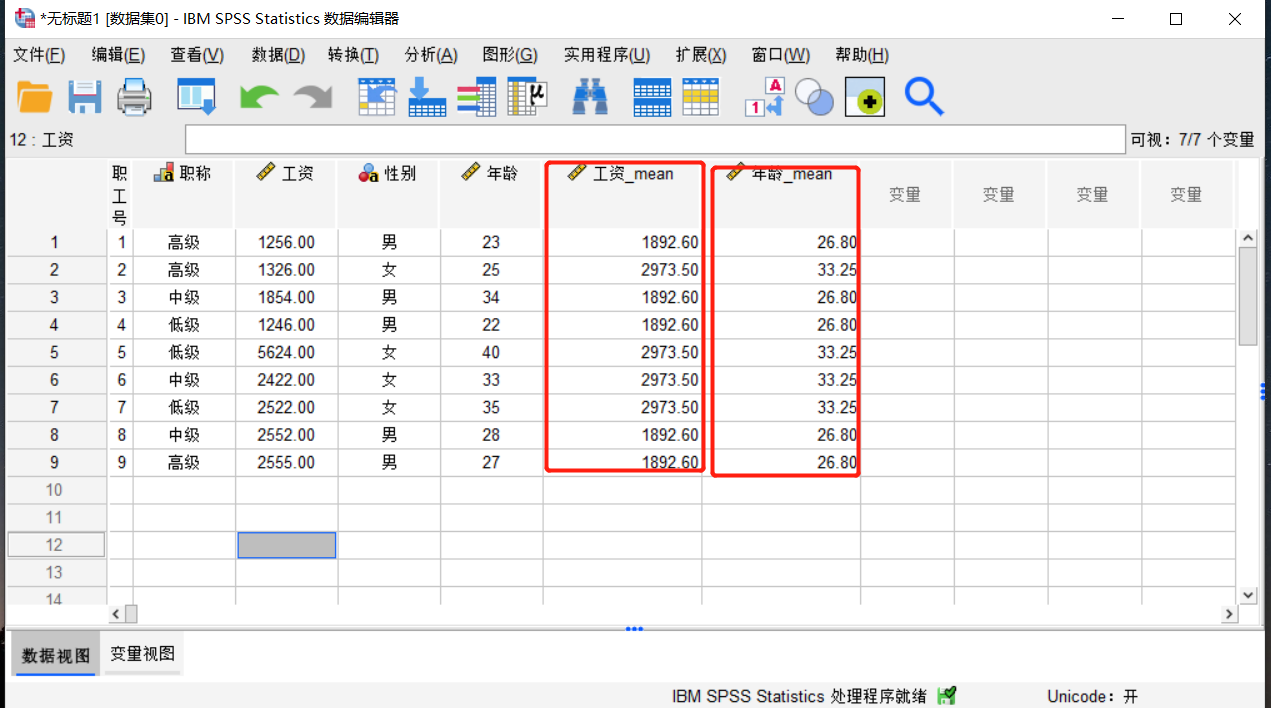
图7:结果展示 数据的分类汇总是常用功能,核心思想就是要选对分界变量和函数。本文只是展示了IBM SPSS中平均值函数,其中还有很多的内置函数,大家可以去中文官网下载正版软件,自己动手尝试。
作者:何必当真
展开阅读全文
︾
标签:IBM SPSS Statistics,数据分析软件
- 上一篇:在SPSS中如何计算新变量
- 下一篇:SPSS中如何进行皮尔逊相关性分析
热门文章SPSS数据分析显著性差异分析步骤 SPSS显著性差异分析结果怎么看数据的显著性差异分析主要有三种方法,分别是卡方检验、T检验和方差分析。这三种方法都有具体的数据要求:卡方检验是对多个类别的数据进行分析,T检验是对两组数据进行分析,方差分析是对多组数据进行检验。下面,小编具体说明一下SPSS数据分析显著性差异分析步骤,SPSS显著性差异分析结果怎么看。2022-01-07实践SPSS单因素方差分析之检验结果解读在《实践SPSS单因素方差分析之变量与检验方法设置》一文中,我们已经详细地演示了IBM SPSS Statistics单因素方差分析方法的变量选择以及相关的选项、对比设置。2021-01-11spss如何做显著性分析 spss显著性差异分析怎么标abc在统计分析中,显著性分析是分析相关因素之间是否存在显著影响关系的关键性指标,通过它可以说明分析结论是否由抽样误差引起还是实际相关的,可论证分析结果的准确性。下面大家一起来看看用spss如何做显著性分析,spss显著性差异分析怎么标abc。2022-03-14SPSS回归分析中的f值是什么 SPSS回归分析F值在什么范围合适回归分析中以R表示相关性程度的高低,以F评价回归分析是否有统计学的意义,使用IBM SPSS Statistics进行回归分析,可以非常快速的完成R,F的计算,并且给出回归曲线方程,那么,SPSS回归分析中f值是什么?SPSS回归分析F值在什么范围合适,本文结合实例向大家作简单的说明。2022-07-22SPSS多元logistic回归分析的使用技巧回归分析是数据处理中较为常用的一类方法,它可以找出数据变量之间的未知关系,得到较为符合变量关系的数学表达式,以帮助用户完成数据分析。2021-04-26SPSS相关性分析结果怎么看相关性分析是对变量或个案之间相关度的测量,在SPSS中可以选择三种方法来进行相关性分析:双变量、偏相关和距离。2021-04-23最新文章SPSS怎么进行简单随机抽样 SPSS怎么进行信效度分析我们在进行问卷调研后,往往需要进行实证的数据分析。在这个过程里,简单随机抽样能够从全量数据中抽取代表性样本,是一种能降低数据分析工作量的核心方法,同时也可以保障样本的随机性与代表性。另外,信度检验验证数据的可靠性,效度分析检验问卷的结构合理性,二者是开展后续统计分析的重要前提。接下来我将为大家介绍:SPSS 怎么进行简单随机抽样,SPSS 怎么进行信效度分析的相关内容。2026-07-02SPSS做频数分布表如何分组 SPSS的频数分布表如何分析数据分析时,连续型变量的原始取值通常较为分散,直接统计频数的话,很难清晰呈现数据的整体分布规律。如果能够分组制作频数分布表,就能将零散的数据整合为有序的组别,直观展现不同区间的样本分布情况。接下来我将为大家介绍:SPSS做频数分布表如何分组,SPSS的频数分布表如何分析的相关内容。2026-07-02SPSS中的f值怎么算 SPSS中的f值显著性数值范围是多少在方差分析、回归分析等统计的方法中,f值多用于判断多组间均值差异是否显著、回归模型是否具有统计学意义。使用SPSS,无需手动计算复杂的f值公式,只需通过对应模块完成变量设置。接下来我将为大家介绍:SPSS中的f值怎么算,SPSS中的f值显著性数值范围是多少的相关内容。2026-07-02SPSS如何将数据转换成二分类 SPSS如何将数据转换成文本原始数据类型往往无法直接满足全部分析与展示需求,所以在数据分析的过程中,我们需要将连续变量或多分类变量转换成二分类变量。而将数值编码转换成文本标签,能让数据结果更直观易懂。接下来我将为大家介绍:SPSS如何将数据转换成二分类,SPSS如何将数据转换成文本的相关内容。2026-07-02SPSS如何验证数据是否符合正态分布 SPSS数据验证怎么用函数计算正态分布,是很多常用的分析方法比如ANOVA方差分析、t检验等,要求数据需要满足的条件。因为满足正态分布的数据,能更加准确地捕捉到差异性,而且它们的总体参数也会更加稳定。在SPSS里面,我们可以通过几种方法来检验数据的分布是否满足需求。接下来我们会介绍SPSS如何验证数据是否符合正态分布,SPSS数据验证怎么用函数计算的相关内容。2026-07-02SPSS变量值设定为0却变成00 SPSS计算变量为什么有空值我们在处理数据样本的过程中,有时候会遇到变量设定错误的问题。就是在设置变量值的时候把变量设定为0,但是实际在数据分析运算的过程中却变成了00,并且在计算变量过程中又出现了空值。出现这种情况可能会直接影响数据分析结果的精准度,因此需通过调整变量类型修正数据。下面以SPSS为例,给大家介绍SPSS变量值设定为0却变成00,SPSS计算变量为什么有空值的具体内容。2026-07-02读者也喜欢这些内容:
-
SPSS显著性小于0.001的意义 SPSS显著性大于0.05怎么办
在使用SPSS软件进行数据分析工作的过程中,得到的显著性水平分析结果具有极为重要的作用。它能够帮助我们衡量变量之间是否存在真实的关联,或者不同组别数据之间是否存在实质性的差异。今天我们就一起来探讨关于SPSS显著性小于0.001的意义,SPSS显著性大于0.05怎么办的问题。...
阅读全文 >
-
SPSS多重响应交叉表怎么做 SPSS多重响应交叉表结果解读
多重响应交叉表工具是数据分析工作中较为常见的一种分析模型,我们可以使用交叉表工具来探究两个变量之间的关联性。今天我就以SPSS多重响应交叉表怎么做,SPSS多重响应交叉表结果解读这两个问题为例,来向大家讲解一下多重响应交叉表的相关知识。...
阅读全文 >
-
SPSS数据转置什么意思 SPSS数据转置怎么操作
在进行SPSS数据计算和分析之前,研究者通常运用SPSS数据转置的方法,借此对繁杂数据进行行列互换,适用于EXCEL、CSV、文本数据、SAS等各类形式的数据文本,便于研究者清晰全面地了解数据信息。本文以SPSS数据转置什么意思,SPSS数据转置怎么操作这两个问题为例,带大家了解一下SPSS数据转置的相关知识。...
阅读全文 >
-

SPSS数据视图都是问号怎么办 SPSS数据视图怎么输入文字
SPSS数据统计分析软件的应用领域很广泛,像是教育学、经济学、社会学、医疗等领域都有涉及,也是因为应用的领域广,所以使用SPSS的统计人员也比较多。不过在使用SPSS的时候,也会遇到一些问题,下面给大家介绍SPSS数据视图都是问号怎么办,SPSS数据视图怎么输入文字的相关内容。...
阅读全文 >





