


- 首页
- 产品
- 下载
- 学生专享NEW
-
帮助中心
SPSS决策树分析使用教程
发布时间:2021-11-11 15: 16: 44
SPSS决策树分析是基于树的分类模型,它将个案分为若干组,或根据自变量(预测变量)的值预测因变量(目标变量)的值。它有易于理解、可以应用于小数据集、能够处理多输出的问题、对缺失值不敏感、效率高等优点。下面就讲解下SPSS决策树分析使用教程。
一、数据集准备
本例使用的是信用风险识别数据(来源Kaggle的项目),包括int_rate(贷款利率)、grade(贷款等级)、home(住房性质)、employment(职业)等八个指标,我们将通过SPSS软件使用这八个指标对数据个案进行决策树分析。
图1数据展示 二、决策树参数设置
点击SPSS主页顶部菜单栏“分析”-“分类”-“决策树”,即可打开决策树窗口。将flag加载到因变量文本框,将八个指标加载到自变量文本框。生长法选择CHAID(卡方自动交互检测),主要是利用卡方检测判断属性优先级。
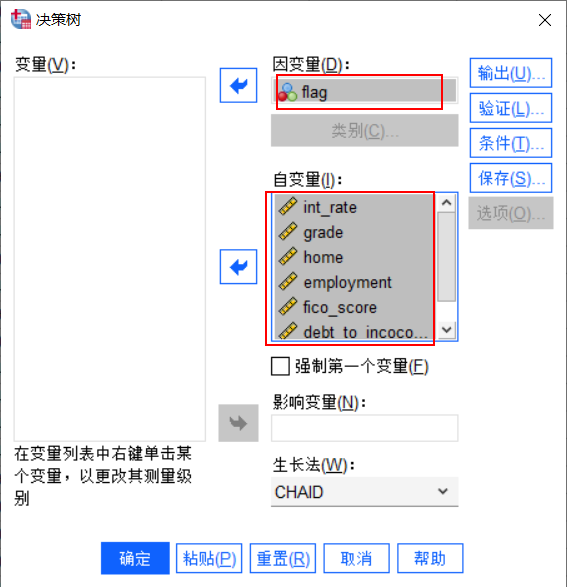
图2决策树 点击右侧的“验证”按钮,按照训练样本70%,检测样本30%的分配数据。
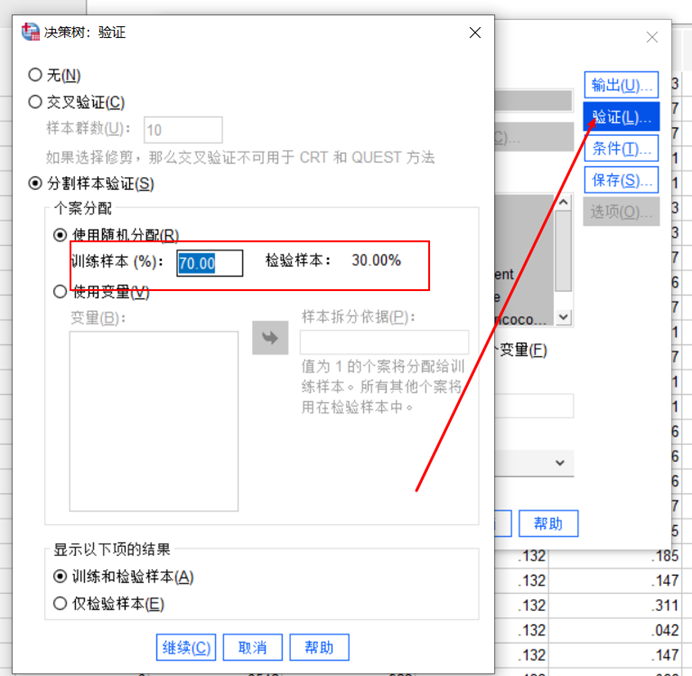
图3数据分配 为了方便结果的观察,点击右侧“保存”,勾选已保存的变量:终端节点数、预测值、预测概率、样本分配。
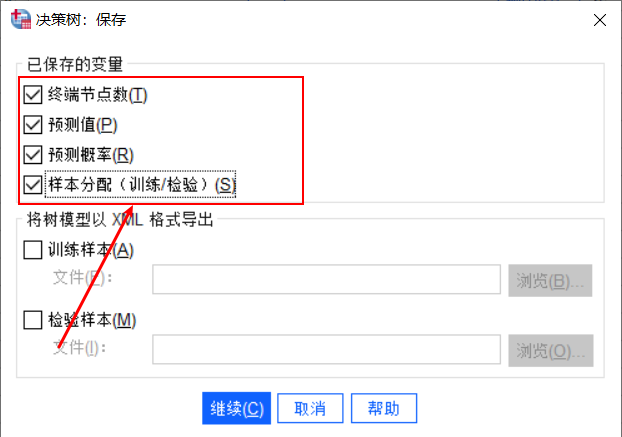
图4设置已保存变量 考虑到防止节点个案数太少而导致结果不准确,因此通过“条件”按钮,将最小个案树父节点设置为400、子节点设置为200。
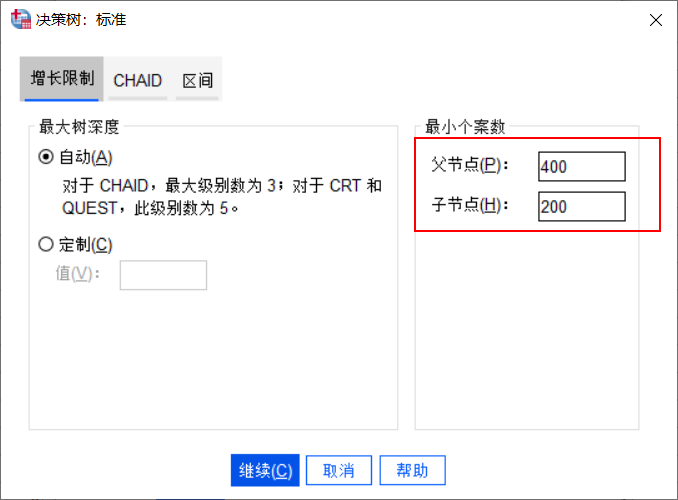
图5增长限制 三、结果分析
通过以上SPSS操作步骤,我们可以得到决策树分析的结果。
1、模型摘要
主要包括生长法、自变量、结果。在本案例中,经过筛选,最终将纳入的是fico_score指标,这意味着这个变量起到重要作用,实际业务操作过程中,我们应该重点关注这个指标。
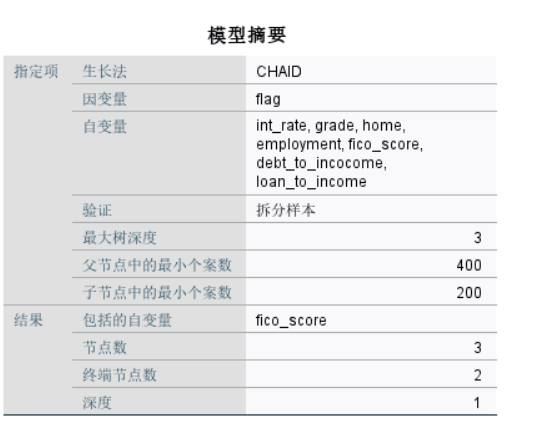
图6模型摘要 2、风险
查看模型效果的重要依据之一,从风险表格中可以看到,训练估算0.061,表示在70%的训练样本中有6.1%的样本被错误归类。检验估算0.069,表示在30%的测试样本中有6.9%的样本被错误归类。
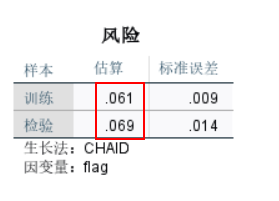
图7风险 3、分类
查看模型效果的重要依据之一,从风险表格中可以看到,训练集93.9%,表示该模型正确率为93.9%。检验集表示在用训练集训练好的模型去检验测试集的数据,正确率为93.1%。
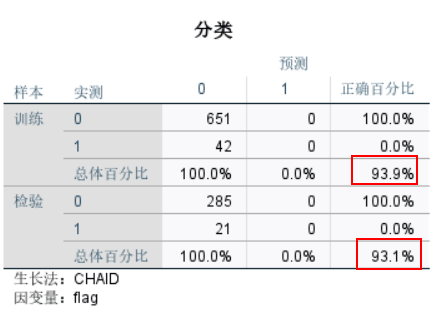
图8分类 四、小结
以上是利用SPSS决策树模型对信用风险识别数据进行分析,首先我们从Kaggle的项目获取数据,然后通过SPSS决策树模型对数据进行分析,最后对得到的分析结果进行解析,可以看到整个分析结果还是非常不错,正确率非常高,也同时说明该模型具有一定的可用性。
作者:独行侠
展开阅读全文
︾
标签:SPSS,决策树分析,SPSS决策树分析,SPSS决策树
读者也访问过这里:热门文章SPSS数据分析显著性差异分析步骤 SPSS显著性差异分析结果怎么看数据的显著性差异分析主要有三种方法,分别是卡方检验、T检验和方差分析。这三种方法都有具体的数据要求:卡方检验是对多个类别的数据进行分析,T检验是对两组数据进行分析,方差分析是对多组数据进行检验。下面,小编具体说明一下SPSS数据分析显著性差异分析步骤,SPSS显著性差异分析结果怎么看。2022-01-07实践SPSS单因素方差分析之检验结果解读在《实践SPSS单因素方差分析之变量与检验方法设置》一文中,我们已经详细地演示了IBM SPSS Statistics单因素方差分析方法的变量选择以及相关的选项、对比设置。2021-01-11spss如何做显著性分析 spss显著性差异分析怎么标abc在统计分析中,显著性分析是分析相关因素之间是否存在显著影响关系的关键性指标,通过它可以说明分析结论是否由抽样误差引起还是实际相关的,可论证分析结果的准确性。下面大家一起来看看用spss如何做显著性分析,spss显著性差异分析怎么标abc。2022-03-14SPSS回归分析中的f值是什么 SPSS回归分析F值在什么范围合适回归分析中以R表示相关性程度的高低,以F评价回归分析是否有统计学的意义,使用IBM SPSS Statistics进行回归分析,可以非常快速的完成R,F的计算,并且给出回归曲线方程,那么,SPSS回归分析中f值是什么?SPSS回归分析F值在什么范围合适,本文结合实例向大家作简单的说明。2022-07-22SPSS多元logistic回归分析的使用技巧回归分析是数据处理中较为常用的一类方法,它可以找出数据变量之间的未知关系,得到较为符合变量关系的数学表达式,以帮助用户完成数据分析。2021-04-26SPSS相关性分析结果怎么看相关性分析是对变量或个案之间相关度的测量,在SPSS中可以选择三种方法来进行相关性分析:双变量、偏相关和距离。2021-04-23最新文章SPSS回归分析加入中介变量怎么做 SPSS中介效应分析结果解读相信大家在进行社会科学研究的时候,常常使用到中介效应分析这个方法。中介效应分析能够清晰地揭示自变量对因变量的影响是否通过中介变量进行传递,让变量间的作用路径更明确。接下来我将为大家介绍:SPSS回归分析加入中介变量怎么做,SPSS中介效应分析结果解读的相关内容。2026-06-02SPSS随机性检验步骤分析 SPSS随机性检验结果分析数据序列的随机性是保障后续统计检验有效性的重要前提,如果出现了非随机分布的数据。有可能会导致分析结果出现偏差。在SPSS中,我们通过游程检验可以快速完成数据随机性的判断。接下来我将为大家介绍:SPSS随机性检验步骤分析,SPSS随机性检验结果分析的相关内容。2026-06-02SPSS绘制箱线图步骤 SPSS箱线图怎么分析SPSS作为一款功能比较齐全的数据统计分析软件,其绘图功能是很全面的,除了常规的条形图、饼形图、折线图外,还有在各种调研报告中常用到的箱线图,可能有些读者朋友不知道怎么用SPSS绘制箱线图,下面将以实际数据给大家在SPSS中演示SPSS绘制箱线图步骤,SPSS箱线图怎么分析。2026-06-022026-06-02SPSS频数分析怎么做 SPSS频数分析结果怎样分析频数分析是我们描述数据分布特征时的一种常用方法,它能够直观呈现分类变量各类别的出现次数与占比情况,帮助我们快速掌握数据的整体分布规律。SPSS中的频数分析功能就十分便捷。接下来我将为大家介绍:SPSS频数分析怎么做,SPSS频数分析结果怎样分析的相关内容。2026-06-02SPSS中如何计算中位数 SPSS中如何计算残差如果我们想看看数据的集中分布情况,一般都会看一下均值,因为它可以观察到数值的平均大小。不过均值容易受到极端值的影响,比如有几个数值很大,就会让平均的数值很高。对于这种情况,可以改用中位数、众数来看数据分布,SPSS可以很快速地计算出这些统计量。接下来,我们会介绍SPSS中如何计算中位数,SPSS中如何计算残差的相关内容。2026-06-02读者也喜欢这些内容:
-
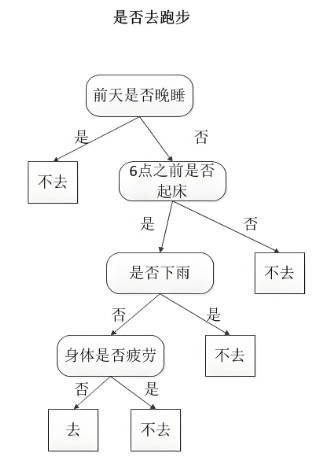
SPSS决策树是什么 SPSS决策树分类规则生成步骤
决策树是非常经典的一种数据分析模型,它以树状结构来呈现决策结果,从而实现数据的分类和预测。今天我就以SPSS决策树是什么,SPSS决策树分类规则生成步骤这两个问题为例,来向大家讲解一下SPSS中有关于决策树的相关知识。...
阅读全文 >
-

SPSS临床应用案例
在医疗科研领域,临床数据的统计分析是验证研究假设、得出科学结论的关键环节。某大型三甲医院作为大学医学院附属医院,其肿瘤科医生兼具临床诊疗与科研教学双重职责,在开展多项临床研究项目时积累了大量数据,亟需高效准确的统计分析工具。SPSS Statistics 凭借操作简便、功能全面的优势,成为该医院处理临床科研数据的首选工具。本文将以该医院肿瘤科的临床研究数据为例,详细阐述 SPSS 在统计描述、统计推断及统计建模中的具体应用,为医疗科研工作者提供参考。...
阅读全文 >
-
SPSS如何进行多重共线性检验 SPSS多重共线性检验分析解读
多重共线性检验是一种常见的回归分析模型,用于检验各变量之间是否存在高度关联性,也是在实际的数据分析过程中使用较为频繁的几类分析模型之一。今天我就以SPSS如何进行多重共线性检验,SPSS多重共线性检验分析解读这两个问题为例,来向大家讲解一下多重共线性检验的相关知识。...
阅读全文 >
-
SPSS数据转置什么意思 SPSS数据转置怎么操作
在进行SPSS数据计算和分析之前,研究者通常运用SPSS数据转置的方法,借此对繁杂数据进行行列互换,适用于EXCEL、CSV、文本数据、SAS等各类形式的数据文本,便于研究者清晰全面地了解数据信息。本文以SPSS数据转置什么意思,SPSS数据转置怎么操作这两个问题为例,带大家了解一下SPSS数据转置的相关知识。...
阅读全文 >
-




