


- 首页
- 产品
- 下载
- 学生专享NEW
-
帮助中心
SPSS如何进行随机抽样
发布时间:2021-05-20 11: 21: 36
在统计学中,随机抽样是非常重要的一种统计分析手段,它使得研究对象有相同的机会被分在某一处理组当中,排除人为因素的影响和干扰。随机抽样是提高研究样本代表性和组间均衡性的重要方法,它的正确使用将直接影响到研究成果的可靠性。
下面我就以一篇简单的教程文章,为大家介绍使用IBM SPSS Statistic,进行随机抽样。
一、设定随机种子
首先我们需要准备好一组数据,接下来的随机抽样将在这组数据中进行随机抽取。准备好数据后,我们点击转换菜单的“随机数生成器”,打开SPSS的随机抽取器。
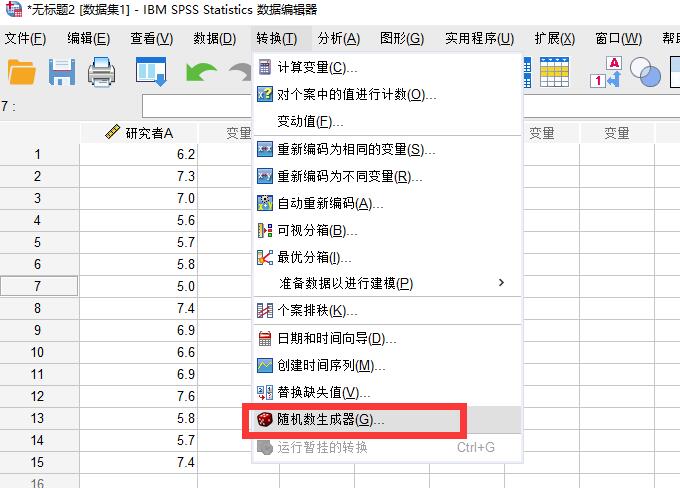
图1:随机数生成器 在活动生成器初始化选项中,勾选“设置起点”,然后选择其中的“固定值”,默认的固定值是2000000,我们采用默认即可。这里选择固定值而不是随机,是为了保证每一次随机抽样的抽取值都是相同的,保证抽样结果具有可重现性。
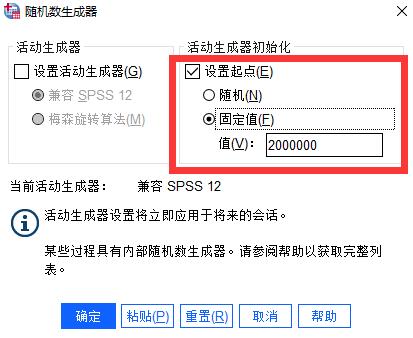
图2:设置固定值 二、简单随机抽样
点击“数据”菜单,选择其中的“选择个案”选项,进入选择个案界面。在该界面中,我们勾选“随机个案样本”,随后在“输出”项中,选择“将选定个案”复制到新数据集,生成一个随机抽取出来的全新数据集合,操作步骤如图3。
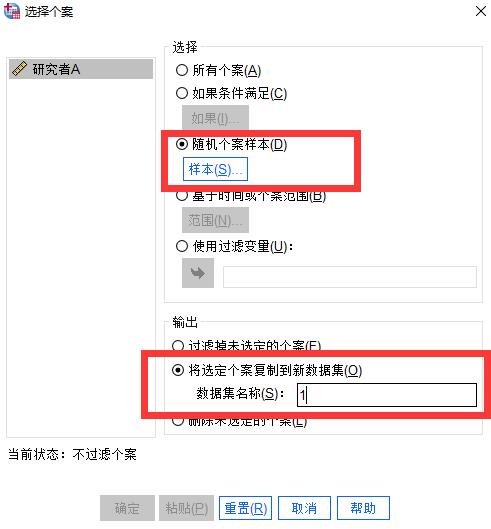
图3:设置随机个案 点击“样本”按钮,设置样本大小的具体参数,主要有两种设置方法,一种是近似法,我们可以设置按百分比大小来选择样本大小,如百分之十,那么会从1000个数据中抽取出100个随机样本。
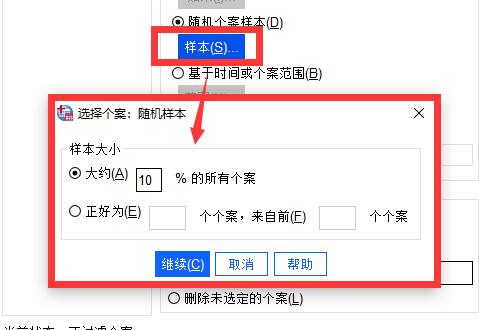
图4:百分比设置样本大小 另外一种是精确法,我们可以设置从前1000个样本中,精确抽取出99个随机样本,如图5。
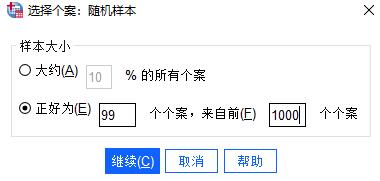
图5:精确设置样本大小 完成以后,回到上个页面点击“确定”,SPSS就会帮我们快速生成一个全新的数据集,当中的数据就是从原本样本中随机抽取出来的数据。
图6:随机抽取结果 这就是关于IBM SPSS Statistic软件,进行随机样本抽取并生成新数据集的完整过程,除了这种简便的随机抽样方法外,对于一些更复杂的随机抽样要求,我们还可以通过外部脚本等多种方式在SPSS中进行随机抽样,更多教程大家可到IBM SPSS Statistic中文网站上查看。
作者署名:包纸
展开阅读全文
︾
标签:SPSS,随机抽样
读者也访问过这里:热门文章SPSS数据分析显著性差异分析步骤 SPSS显著性差异分析结果怎么看数据的显著性差异分析主要有三种方法,分别是卡方检验、T检验和方差分析。这三种方法都有具体的数据要求:卡方检验是对多个类别的数据进行分析,T检验是对两组数据进行分析,方差分析是对多组数据进行检验。下面,小编具体说明一下SPSS数据分析显著性差异分析步骤,SPSS显著性差异分析结果怎么看。2022-01-07实践SPSS单因素方差分析之检验结果解读在《实践SPSS单因素方差分析之变量与检验方法设置》一文中,我们已经详细地演示了IBM SPSS Statistics单因素方差分析方法的变量选择以及相关的选项、对比设置。2021-01-11spss如何做显著性分析 spss显著性差异分析怎么标abc在统计分析中,显著性分析是分析相关因素之间是否存在显著影响关系的关键性指标,通过它可以说明分析结论是否由抽样误差引起还是实际相关的,可论证分析结果的准确性。下面大家一起来看看用spss如何做显著性分析,spss显著性差异分析怎么标abc。2022-03-14SPSS回归分析中的f值是什么 SPSS回归分析F值在什么范围合适回归分析中以R表示相关性程度的高低,以F评价回归分析是否有统计学的意义,使用IBM SPSS Statistics进行回归分析,可以非常快速的完成R,F的计算,并且给出回归曲线方程,那么,SPSS回归分析中f值是什么?SPSS回归分析F值在什么范围合适,本文结合实例向大家作简单的说明。2022-07-22SPSS多元logistic回归分析的使用技巧回归分析是数据处理中较为常用的一类方法,它可以找出数据变量之间的未知关系,得到较为符合变量关系的数学表达式,以帮助用户完成数据分析。2021-04-26SPSS相关性分析结果怎么看相关性分析是对变量或个案之间相关度的测量,在SPSS中可以选择三种方法来进行相关性分析:双变量、偏相关和距离。2021-04-23最新文章SPSS如何绘制茎叶图 SPSS茎叶图怎么分析我们在进行数据分析的过程中,可以借助数据分析后绘制的图像来辅助我们解读数据。数据分析图像能够更加直观地表现出数据的变化幅度以及分布状况,而在数据分析的图像中,茎叶图能够在保留数据信息的同时展现数据样本的轮廓。所以茎叶图就可以成为我们数据分析的一个重要工具,但是许多小伙伴对茎叶图的绘制和使用并不熟悉。下面以SPSS为例,给大家介绍SPSS如何绘制茎叶图,SPSS茎叶图怎么分析的具体内容。2026-07-01SPSS怎么对多选题进行频率分析 SPSS频率分析怎么做我们在问卷数据分析过程中,常常会遇到多选题。这时候,常规的频率分析可能就无法适配多选项的计数需求,而SPSS中的多重响应功能可精准完成多选题的频率统计,同时也能通过基础频率分析功能完成单选题的常规统计。接下来我将为大家介绍:SPSS怎么对多选题进行频率分析,SPSS频率分析怎么做的相关内容。2026-07-01SPSS回归分析加入中介变量怎么做 SPSS中介效应分析结果解读相信大家在进行社会科学研究的时候,常常使用到中介效应分析这个方法。中介效应分析能够清晰地揭示自变量对因变量的影响是否通过中介变量进行传递,让变量间的作用路径更明确。接下来我将为大家介绍:SPSS回归分析加入中介变量怎么做,SPSS中介效应分析结果解读的相关内容。2026-06-02SPSS随机性检验步骤分析 SPSS随机性检验结果分析数据序列的随机性是保障后续统计检验有效性的重要前提,如果出现了非随机分布的数据。有可能会导致分析结果出现偏差。在SPSS中,我们通过游程检验可以快速完成数据随机性的判断。接下来我将为大家介绍:SPSS随机性检验步骤分析,SPSS随机性检验结果分析的相关内容。2026-06-02SPSS绘制箱线图步骤 SPSS箱线图怎么分析SPSS作为一款功能比较齐全的数据统计分析软件,其绘图功能是很全面的,除了常规的条形图、饼形图、折线图外,还有在各种调研报告中常用到的箱线图,可能有些读者朋友不知道怎么用SPSS绘制箱线图,下面将以实际数据给大家在SPSS中演示SPSS绘制箱线图步骤,SPSS箱线图怎么分析。2026-06-022026-06-02读者也喜欢这些内容:
-
SPSS 安装激活流程
...
阅读全文 >
-
SPSS怎样生成描述性统计表 SPSS统计表结果格式不规范怎么办
在数据分析的过程中,描述性统计表是其中不可缺少的重要部分。由于能够准确地描述出需要分析的数据样本和统计内容,描述性的统计表在不同的统计场景中也有广泛的应用(例如对数据样本进行集中趋势分析和离散性分析)。所以随着精准数据分析的需求不断提升,越来越多的用户会选择采用描述性统计分析的方式来分析数据。下面以SPSS为例,给大家介绍SPSS怎样生成描述性统计表,SPSS统计表结果格式不规范怎么办的具体内容。...
阅读全文 >
-
SPSS的Fisher精确检验怎么操作 SPSS Fisher精确检验结果解读
Fisher精确检验是一种用于分析纵列交叉表数据的统计学模型,我们可以使用SPSS中的交叉表工具来完成这一操作。今天我就以SPSS的Fisher精确检验怎么操作,SPSS Fisher精确检验结果解读这两个问题为例,来向大家讲解一下有关Fisher精确检验的相关知识和操作技巧。...
阅读全文 >
-
SPSS回归方程怎么做 SPSS回归方程怎么看
我们在进行数据分析时会经常遇到“回归方程”这个概念,这个概念在分析数据的趋势和走向中发挥了重要作用,同时可以对数据的未来发展方向进行研判,而回归方程就是将抽象的趋势与数学连接起来的方程式。在制作回归方程时,一款好用的软件是不可缺少的,下面以数据分析软件SPSS为例,给大家介绍SPSS回归方程怎么做 ,SPSS回归方程怎么看的相关内容...
阅读全文 >
-




