


- 首页
- 产品
- 下载
- 学生专享NEW
-
帮助中心
SPSS模糊聚类是什么 SPSS模糊聚类分析步骤
发布时间:2025-02-11 11: 16: 00
电脑型号:华硕K555L
软件版本:IBM SPSS Statistics 29.0
系统:win10
作为一种优于传统聚类的数据分析方法,模糊聚类允许文本信息在数据的分析过程中,携带多种样本属性。今天,我就以“SPSS模糊聚类是什么,SPSS模糊聚类分析步骤”为例,向大家介绍一下模糊聚类的相关知识。
一、SPSS模糊聚类是什么
想要了解模糊聚类的定义,就需要先了解什么是聚类。聚类,顾名思义就是将数据中具有相关性的内容统筹到一起,去进行关联性和影响性分析。
而模糊聚类,通过样本信息的属性和相似度计算,优化了传统聚类方式中的硬性操作,使数据类别更加简洁,更方便前期的查询和排序工作。
这种数据处理方式,广泛应用于图像信息、生物信息以及语言分析等具备高度相似特征的数据处理工作中。
二、SPSS模糊聚类分析步骤
讲解完模糊聚类的定义,接下来我就使用SPSS这样一款数据分析软件,来向大家演示一下,模糊聚类分析的具体操作步骤。
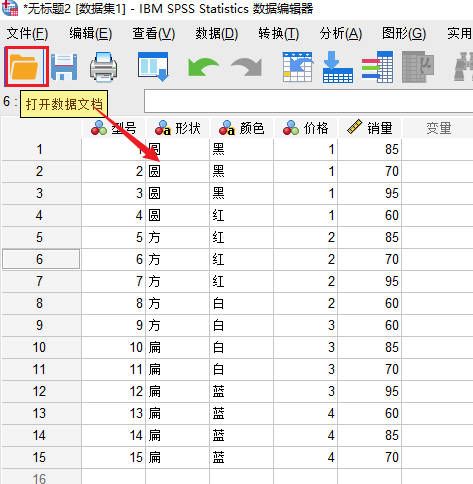
1、打开数据:进入SPSS的编辑界面后,点击文件选项卡中的“打开-数据”命令。
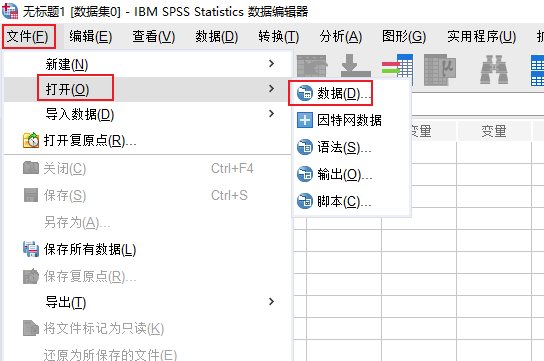
图1:打开数据 2、预览数据:在文件的读取界面中,我们可以通过“预览窗口”查看导入信息的部分内容。
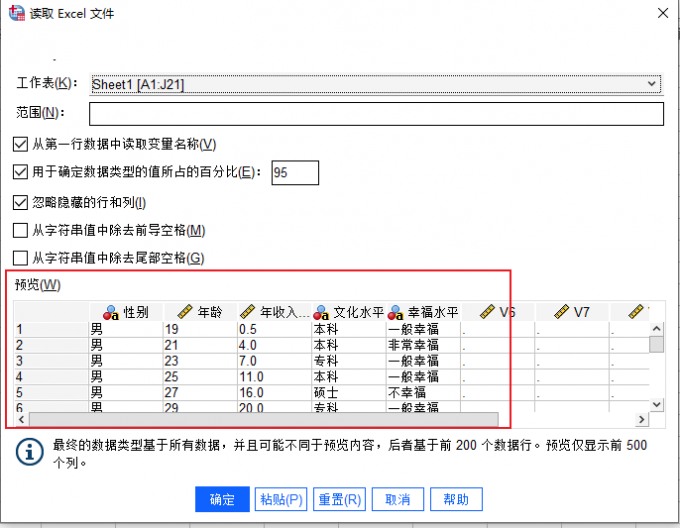
图2:预览数据 3、查看变量:通过主界面中的“变量视图”,我们可以查看数据的“类型”。在这里,我导入了与字符串和数字相关的两种数据类型。
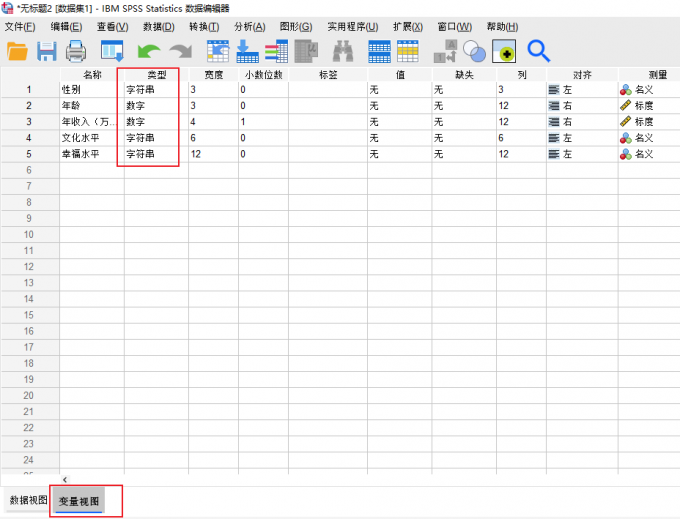
图3:查看变量 4、系统聚类:切换到分析选项卡,使用其中的“分类-系统聚类”命令。
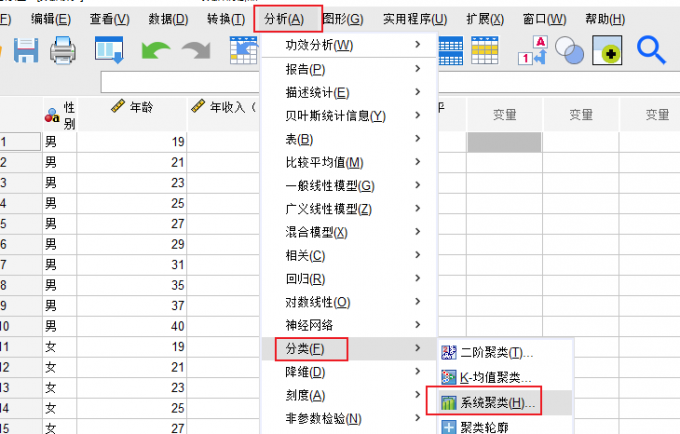
图4:系统聚类 5、聚类设置:进入聚类分析的设置界面后,我们将年收入和年龄放入“变量”选框,将幸福水平放入“个案标注依据”选框。
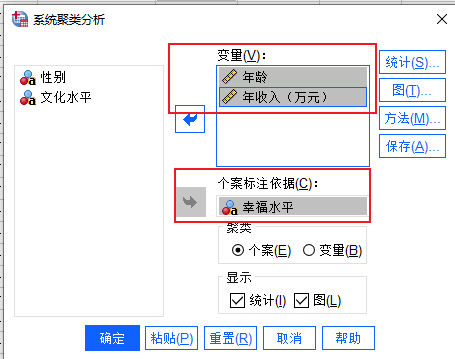
图5:聚类设置 6、统计设置:点击右侧的统计按钮,勾选其中的“集中计划、近似值矩阵”选项,“聚类数”设置为20。
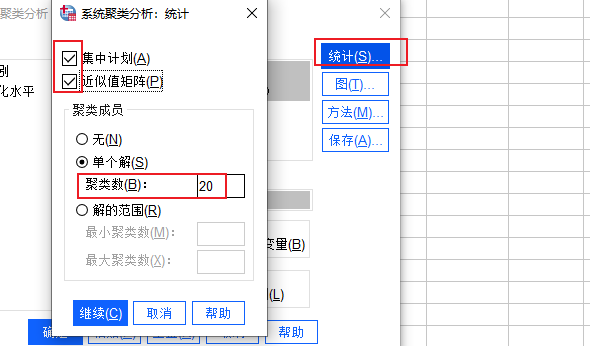
图6:统计设置 7、图设置:图设置界面中,勾选“谱系图”,冰柱图选项中选择“全部聚类”模式,方向选择“垂直”。
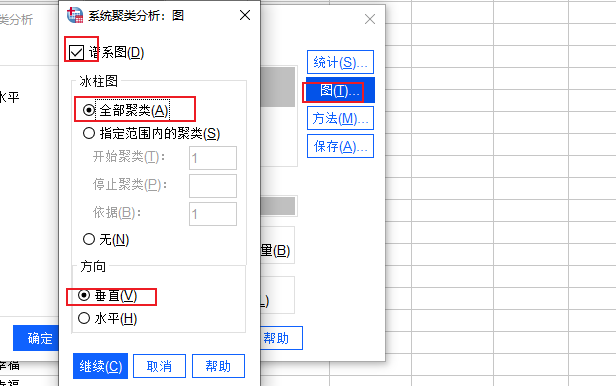
图7:图设置 8、方法设置:方法设置界面中,选择聚类方法中的“瓦尔德法”。
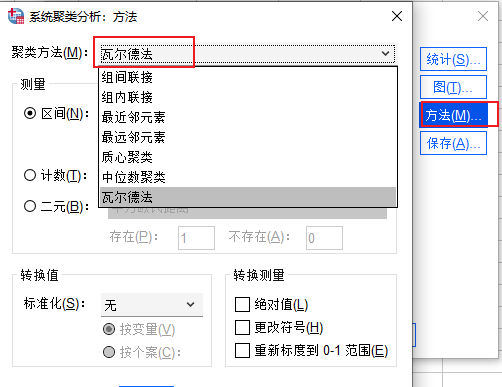
图8:方法设置 9、数据分析:随后返回主设置界面,查看“显示”命令下方的“统计和图”选项是否勾选。勾选完成后,点击确定命令,开始进行数据分析。
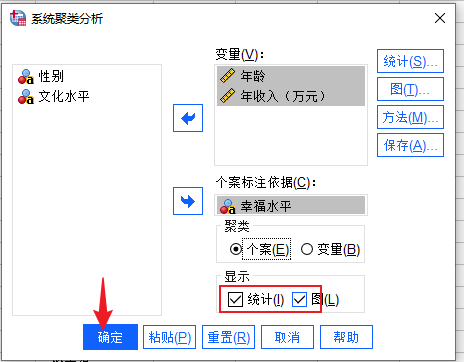
图9:数据分析 10、结果:待软件加载完成后,会弹出对应的结果查看器。通过左侧的结果树,我们可以查看个案数的合理性,以及各要素之间的“显著性水平和影响关系”。获得上述信息后,就可以将差异小的各类要素,作为同一类别进行整合处理。
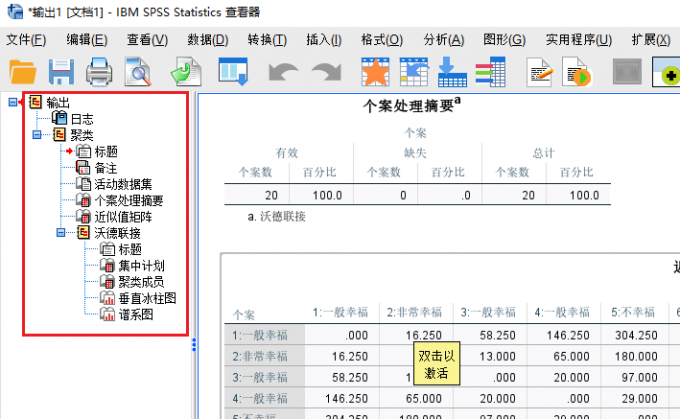
图10:结果 三、小结
以上就是关于“SPSS模糊聚类是什么,SPSS模糊聚类分析步骤 ”的解答。如同上文所演示的,我们一定要提前设置好聚类分析的数目,这样才能更好地判断出各要素之间的影响度。一般情况下,分析数目越多,所得的的数值就越明朗。如果大家在使用SPSS时遇到其他困惑,也欢迎前往其中文网站,查看相关操作教程。
展开阅读全文
︾
标签:SPSS聚类分析,SPSS系统聚类
读者也访问过这里:热门文章SPSS数据分析显著性差异分析步骤 SPSS显著性差异分析结果怎么看数据的显著性差异分析主要有三种方法,分别是卡方检验、T检验和方差分析。这三种方法都有具体的数据要求:卡方检验是对多个类别的数据进行分析,T检验是对两组数据进行分析,方差分析是对多组数据进行检验。下面,小编具体说明一下SPSS数据分析显著性差异分析步骤,SPSS显著性差异分析结果怎么看。2022-01-07实践SPSS单因素方差分析之检验结果解读在《实践SPSS单因素方差分析之变量与检验方法设置》一文中,我们已经详细地演示了IBM SPSS Statistics单因素方差分析方法的变量选择以及相关的选项、对比设置。2021-01-11spss如何做显著性分析 spss显著性差异分析怎么标abc在统计分析中,显著性分析是分析相关因素之间是否存在显著影响关系的关键性指标,通过它可以说明分析结论是否由抽样误差引起还是实际相关的,可论证分析结果的准确性。下面大家一起来看看用spss如何做显著性分析,spss显著性差异分析怎么标abc。2022-03-14SPSS回归分析中的f值是什么 SPSS回归分析F值在什么范围合适回归分析中以R表示相关性程度的高低,以F评价回归分析是否有统计学的意义,使用IBM SPSS Statistics进行回归分析,可以非常快速的完成R,F的计算,并且给出回归曲线方程,那么,SPSS回归分析中f值是什么?SPSS回归分析F值在什么范围合适,本文结合实例向大家作简单的说明。2022-07-22SPSS多元logistic回归分析的使用技巧回归分析是数据处理中较为常用的一类方法,它可以找出数据变量之间的未知关系,得到较为符合变量关系的数学表达式,以帮助用户完成数据分析。2021-04-26SPSS相关性分析结果怎么看相关性分析是对变量或个案之间相关度的测量,在SPSS中可以选择三种方法来进行相关性分析:双变量、偏相关和距离。2021-04-23最新文章SPSS数据分析如何确定用哪种方法分析 SPSS怎样验证数据分析结果的准确性面对不同类型的数据,我们要选择不同的分析方法。对于初学者来说,如果没有系统学习过统计相关的知识,会比较难入门。不过,在SPSS软件里面,我们可以根据数据的特点、研究目的等内容,简单而快速地找到合适的功能。接下来我们会介绍SPSS数据分析如何确定用哪种方法分析,SPSS怎样验证数据分析结果的准确性的相关内容。2026-07-02SPSS多重线性回归哑变量怎么设置 SPSS多重线性回归结果解读我们在进行多重线性回归分析时,分类变量是没法直接纳入模型的,这时候就需要通过设置哑变量来将其转化为可计算的数值变量。接下来我将为大家介绍:SPSS多重线性回归哑变量怎么设置,SPSS多重线性回归结果解读的相关内容。2026-07-02SPSS多重插补数据怎么分析 SPSS多重插补后用哪个结果在数据分析的领域中,多重插补数据是一项重要的数据分析方法,许多数据分析场景中都可以看到它的影子。多重插补数据并不是简单地对数据的内容进行补充,而是在填补缺失值的基础上对数据进行了再一次的分析和模拟,体现出数据样本的不确定性。所以后续的数据分析需要在多重插补的数据分析基础之上根据结果进行合并,这样才能得到更加准确的结果。下面以SPSS为例,给大家介绍SPSS多重插补数据怎么分析,SPSS多重插补后用哪个结果的具体内容。2026-07-01SPSS如何绘制茎叶图 SPSS茎叶图怎么分析我们在进行数据分析的过程中,可以借助数据分析后绘制的图像来辅助我们解读数据。数据分析图像能够更加直观地表现出数据的变化幅度以及分布状况,而在数据分析的图像中,茎叶图能够在保留数据信息的同时展现数据样本的轮廓。所以茎叶图就可以成为我们数据分析的一个重要工具,但是许多小伙伴对茎叶图的绘制和使用并不熟悉。下面以SPSS为例,给大家介绍SPSS如何绘制茎叶图,SPSS茎叶图怎么分析的具体内容。2026-07-01SPSS怎么对多选题进行频率分析 SPSS频率分析怎么做我们在问卷数据分析过程中,常常会遇到多选题。这时候,常规的频率分析可能就无法适配多选项的计数需求,而SPSS中的多重响应功能可精准完成多选题的频率统计,同时也能通过基础频率分析功能完成单选题的常规统计。接下来我将为大家介绍:SPSS怎么对多选题进行频率分析,SPSS频率分析怎么做的相关内容。2026-07-01SPSS回归分析加入中介变量怎么做 SPSS中介效应分析结果解读相信大家在进行社会科学研究的时候,常常使用到中介效应分析这个方法。中介效应分析能够清晰地揭示自变量对因变量的影响是否通过中介变量进行传递,让变量间的作用路径更明确。接下来我将为大家介绍:SPSS回归分析加入中介变量怎么做,SPSS中介效应分析结果解读的相关内容。2026-06-02读者也喜欢这些内容:
-
SPSS偏度和峰度的分析步骤 SPSS偏度和峰度的分析结果解读
偏度和峰度是我们在进行数据分析的过程中,判断数据是否符合正态分布的重要标准之一,通过这两个数值可以很清晰地看出数据的整体走势和集中状态。因此这两项数值也经常被用于市场学分析、股市分析中,能够帮忙用户去发现某些潜在的规律。今天我就以SPSS偏度和峰度的分析步骤,SPSS偏度和峰度的分析结果解读这两个问题为例,来向大家讲解一下关于偏度和峰度的相关知识。...
阅读全文 >
-
SPSS显著性小于0.001的意义 SPSS显著性大于0.05怎么办
在使用SPSS软件进行数据分析工作的过程中,得到的显著性水平分析结果具有极为重要的作用。它能够帮助我们衡量变量之间是否存在真实的关联,或者不同组别数据之间是否存在实质性的差异。今天我们就一起来探讨关于SPSS显著性小于0.001的意义,SPSS显著性大于0.05怎么办的问题。...
阅读全文 >
-
SPSS数据合并怎么实现 SPSS数据合并个案追加流程
当我们进行数据分析时,不会只分析一组数据源,如果需要将多组数据源进行合并,就必须使用到SPSS中的数据合并工具。今天我就以SPSS数据合并怎么实现,SPSS数据合并个案追加流程这两个问题为例,来向大家讲解一下SPSS中数据合并的相关知识。...
阅读全文 >
-

SPSS变量名称怎么改,SPSS变量名称非法字符怎么办
变量是我们进行数据分析的主体,变量的类型和名称有很多,我们需要为不同的变量设定不同的名称,才能使SPSS有效地识别并判断出它们之间的数据属性。今天我就以SPSS变量名称怎么改,SPSS变量名称非法字符怎么办这两个问题为例,来向大家讲解一下SPSS中有关变量名称设定的相关知识。...
阅读全文 >
-















