




仅剩:

发布时间:2024-11-28 10: 49: 00
说到数据分析,尤其是做分类数据的分析时,很多人都会提到对数线性模型。虽然它的名字听起来很复杂,但实际上理解起来并没有那么难。今天我们就来聊聊对数线性模型系数解释,对数线性模型SPSS操作,带你一步步掌握这个有用的分析工具。
一、对数线性模型系数解释
首先,什么是对数线性模型?简单来说,它就是一种用来分析分类数据间关系的模型。特别是当你需要处理的是计数数据,比如研究某种疾病在不同人群中的发生频率,或者在不同地区发生的次数时,使用对数线性模型就特别合适。
它的基本形式可以写成这样:
log(μij )=β0 +β1 X1 +β2 X2 +⋯+βk Xk 看起来有点复杂,但其实没什么大不了的。这里的μij 是你想预测的计数数据;而β0 是常数项,β1,β2,…,βk是回归系数,X1,X2,…,Xk 是你用来预测的自变量。
那么这些系数具体是什么意义呢?每个βi\beta_iβi 系数表示自变量(比如性别、年龄等)对因变量(比如疾病发生频率)的影响程度。由于我们使用的是对数形式的模型,所以这些系数本身的意义可能有点抽象,但只要把系数做指数化(也就是求eβie^{\beta_i}eβi ),就能把它变得更容易理解了。
二、对数线性模型SPSS操作
知道了对数线性模型系数的含义之后,我们来看看怎么在SPSS里面操作它吧!其实,SPSS做这个分析很简单,基本上你按照我说的步骤走一遍就能搞定。
1.准备数据
第一步就是确保你的数据整理好。特别是因变量,记住要是计数数据,比如销售量、人数之类的,而自变量可以是一些分类变量,像性别、年龄段或者地区之类的。如果数据里面有缺失值,最好处理掉。SPSS对缺失值很敏感,数据不完整可能导致分析结果不准确,所以缺失值一定要先填补好,或者直接删掉。
2.打开SPSS进行分析
打开SPSS后,先把数据导进去,然后上面有个菜单,找到“分析”选项,点击后,会看到一个“分类数据”的子菜单,里面有一个“对数线性”的选项。点击它,就进入了设置界面,接下来就可以开始设置了。
3.选择因变量和自变量
在对数线性分析的界面里,最重要的就是选择因变量和自变量了。因变量就是你想分析或者预测的那个东西,譬如说“销售量”或者“疾病发病率”。自变量就是那些你认为可能会影响因变量的因素,比如“性别”“年龄”等等。只要把这些变量拖到对应的位置,SPSS就能识别并且准备好做计算。
4.设置交互项
如果你觉得某些自变量之间有互动效应,比如性别和年龄可能一起影响销售量,你就可以加一个交互项。交互项就是让SPSS考虑这两个变量结合的情况,看看它们是怎么一起影响因变量的。在设置界面里,你只需要选择相关的变量,然后SPSS会自动帮你生成交互项。
5.运行分析并解读结果
设置完了,点击“确定”,SPSS就开始运行了。它会给你生成一个输出结果,其中包含了各个变量的系数和显著性。你可以通过这些系数来判断哪些因素对结果有显著影响。这里注意,输出的系数是对数值的。如果你想更直观地理解,可以把这些系数转换成指数形式,结果就会更加容易解读。
三、SPSS怎么修改字符串变量
SPSS不仅能做统计分析,还能帮助你处理数据。如果你的数据里面有字符串变量,像“男”和“女”这种,你也可以通过SPSS来改一下,让它适应后续分析。
1.打开数据视图
首先,你得打开SPSS的数据视图。这个视图就是你可以看到表格数据的地方,行是样本,列是变量。找到你需要修改的字符串变量,点击它所在的列。
2.修改变量的值
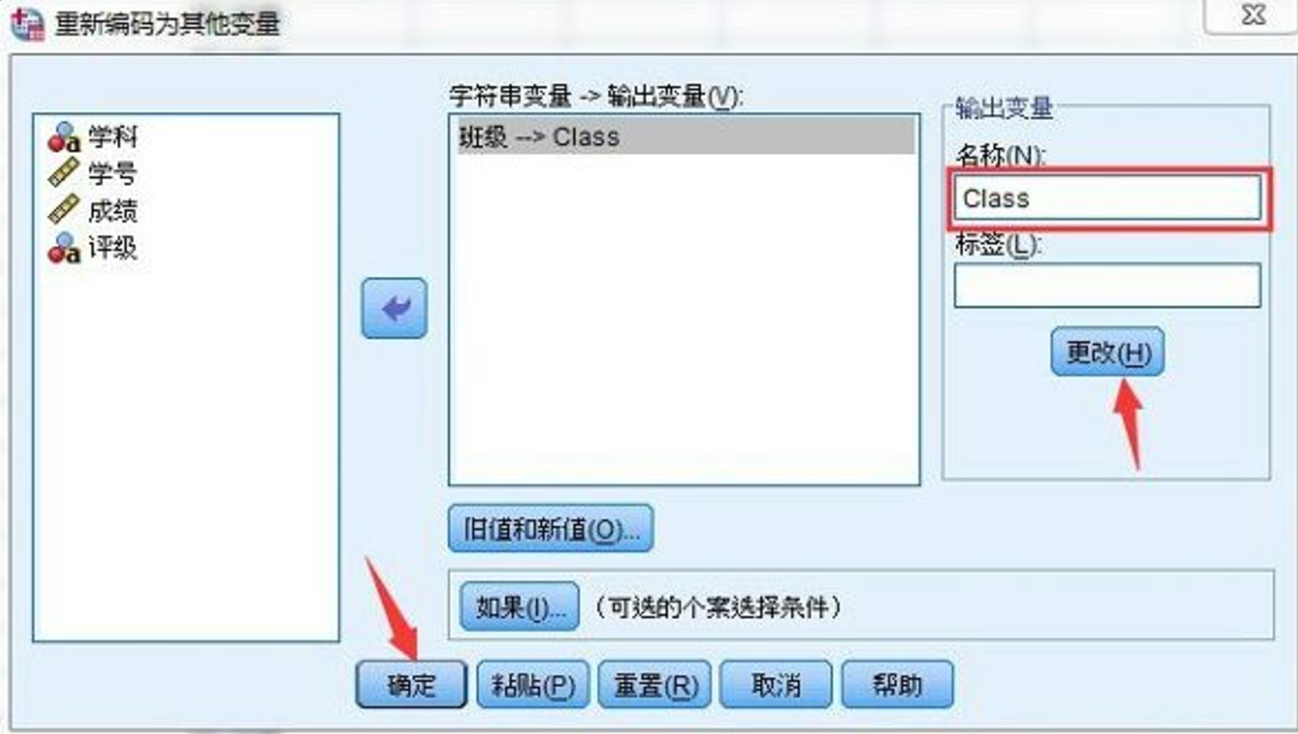
如果你需要批量修改这个字符串变量的值,可以利用SPSS里的“重新编码”功能。在“转换”菜单里有一个“重新编码为不同的变量”选项,点进去后,你就可以选择那个变量,接着设置你想要修改的值。比如“性别”这个变量,如果你有“男”用“M”表示,“女”用“F”表示,你就可以把它们重新编码成1和2,这样就能更方便地做统计了。
3.用查找和替换功能
如果你只是需要修改几个数据点,SPSS也有个查找和替换的功能。你可以直接点击“编辑”菜单,选择“查找和替换”。输入你想替换的值,然后填入新值,SPSS会帮你自动替换掉所有相关的内容。这样做很简单,非常方便。
4.将字符串转为数值型变量
如果你有个字符串变量,比如“是”和“否”这种,想把它转换成数值型变量,SPSS也能搞定。你可以在“转换”菜单里找到“自动编码”选项,这个功能会自动把你的字符串数据转化成数值型数据。转换后,你就可以进行更多的统计分析了。
四、总结
以上就是对数线性模型系数解释 对数线性模型SPSS操作的内容,对数线性模型在处理计数数据和分类数据时,能够帮助我们分析不同变量之间的关系,而SPSS为我们提供了一个非常直观和便捷的工具来进行这一分析。无论是在选择因变量和自变量,还是在设置交互项和解读结果时,SPSS都能轻松应对。掌握这些方法,能让你在数据分析中更加得心应手。
展开阅读全文
︾
读者也喜欢这些内容:
SPSS如何把连续变量变成二分类 SPSS将连续变量重新编码为分类变量的方法
我们在使用SPSS进行数据分析时,都会导入大量的原始文件,只有原始文件的基数足够大,我们才能获得较为客观的分析结果。但是众多原始数据中,总会出现一些连续变量,它们会在一定程度上降低数据的参考价值。针对这种情况,我们就需要考虑如何将这些连续变量转换为对我们有利的分类变量。今天我就以SPSS如何把连续变量变成二分类,SPSS将连续变量重新编码为分类变量的方法这两个问题为例,来向大家讲解一下连续变量的转化技巧。...
阅读全文 >
SPSS怎么进行Logistic回归 SPSS Logistic回归分类结果不准确怎么办
在数据分析中,Logistic回归常常作为处理二分类因变量的方法,应用场景广泛。使用SPSS进行Logistic回归时,很多朋友常面临分类结果不准确的问题。今天我们将会详细介绍关于SPSS怎么进行Logistic回归,SPSS Logistic回归分类结果不准确怎么办的相关问题。...
阅读全文 >
SPSS显著性小于0.001的意义 SPSS显著性大于0.05怎么办
在使用SPSS软件进行数据分析工作的过程中,得到的显著性水平分析结果具有极为重要的作用。它能够帮助我们衡量变量之间是否存在真实的关联,或者不同组别数据之间是否存在实质性的差异。今天我们就一起来探讨关于SPSS显著性小于0.001的意义,SPSS显著性大于0.05怎么办的问题。...
阅读全文 >
SPSS如何把多个指标合并成一个变量 如何定义SPSS变量属性
对于科研工作者、数据分析师来说,好用的数据分析软件可以帮助我们显著提高工作效率。SPSS既能够帮助我们进行日常的数据分析,还可以依照数据分析的结果给出相应的数据分析报告,辅助我们进行后续的工作。接下来给大家介绍SPSS如何把多个指标合并成一个变量,如何定义SPSS变量属性的具体内容。...
阅读全文 >
